
软件工程笔记9-软件工程刷题
Published:
有一部分人认为,即使爱获得了许可,它也必须服从婚姻的誓言和家庭的纽带,这样爱的火焰才会温暖人心而又不灼烧生活。
另一部分人则坚信,只有激情才能让灵魂从肉体的泥屋中得到解脱,只有放任你的心像野兔一样奔跑直到日落,才能使人在入夜后安然睡去。还有“沉重说”学派,他们压抑爱情,并以古代文学中的章节为例,声称那些为欲望一最轻浮的东西一所驱使的人,终会被他们无法承受的重量所伤。与其承受这可怕的重量,不如一开始就接受情欲必要带着枷锁走完一生。
软件工程刷题
杂项
数据是使程序能够正确处理信息的数据结构
设计是软件工程的技术核心
文档是与程序开发、维护、使用有关的图文材料
软件的定义是:软件是计算机系统中与硬件相互依存的另一部分,包括(程序)、(数据)及其(相关文档)的完整集合。
程序是事先设计的功能和性能要求执行的指令序列
反映软件结构的基本形态特征是深度、宽度、扇入和扇出。
- 系统软件,操作系统
- 支撑软件,需求分析工具,设计工具,编码工具,测试工具,维护工具
- 应用软件,办公软件
- 可复用软件,类库,应用程序库
软件十大特性:形态特性、智能特性、开发特性、质量特性、生产特性、管理特性、环境特性、维护特性、废弃特性、应用特性
形智开发质量,生产管理环境,维护废弃应用
软件工程的目标是运用先进的软件开发技术和管理方法来提高软件的质量和生产率,
也就是要以较短的周期、较低的成本生产出高质量的软件产品,
并最终实现软件的工业化生产。
软件危机:软件危机是指在计算机软件的开发和维护过程中所遇到的一系列严重问题。典型表现(7个):·····
- 对软件开发成本和进度的估计常常很不准确
- 用户对“已完成的”软件系统不满意的现象经常发生。
- 软件产品的质量往往靠不住。
- 软件常常是不可维护的
- 软件通常没有适当的文档资料
- 软件成本在计算机系统总成本中所占的比例逐年上升。
- 软件开发生产率提高的速度,既跟不上硬件的发展速度,也远远跟不上计算机应用迅速普及深入的趋势。
(用户不满意、软件不可维护、软件成本上升、开发和进度估计不准、不写文档!!、软件开发生产率提高速度落后其他)
产生软件危机的原因:除了软件本身的特点,其原因主要有以下几个方面(5个)
- 缺乏软件开发的经验和有关软件开发数据的积累,使得开发工作计划很难制定。🐔
- 软件人员与用户的交流存在障碍,使得获取的需求不充分或存在错误。🐎
- 软件开发过程不规范。如,没有真正了解用户的需求就开始编程序🐢
- 随着软件规模的增大,其复杂性往往会呈指数级升高。需要很多人分工协作,不仅涉及技术问题,更重要的是必须有科学严格的管理。🔧
- 缺少有效的软件评测手段,提交给用户的软件的质量不能完全保证🔎
(没经验、不懂交流、开发没规范、不懂测评、体量大)

软件工程是指导计算机软件开发和维护的工程学科。 软件工程是怎样的学科?
采用工程的概念、原理、技术和方法来开发和维护软件, 采用哪些方法开发维护?
把经过时间考验而证明正确的管理技术和当前能够得到的最好的技术方法结合起来, 用什么技术?
以经济地开发出高质量的软件并有效地维护它, 怎样的开发和维护(修饰词)?
这就是软件工程。
软件工程主要研究领域是软件工程方法学、软件工具和软件支撑环境、软件管理及软件的规范与标准等
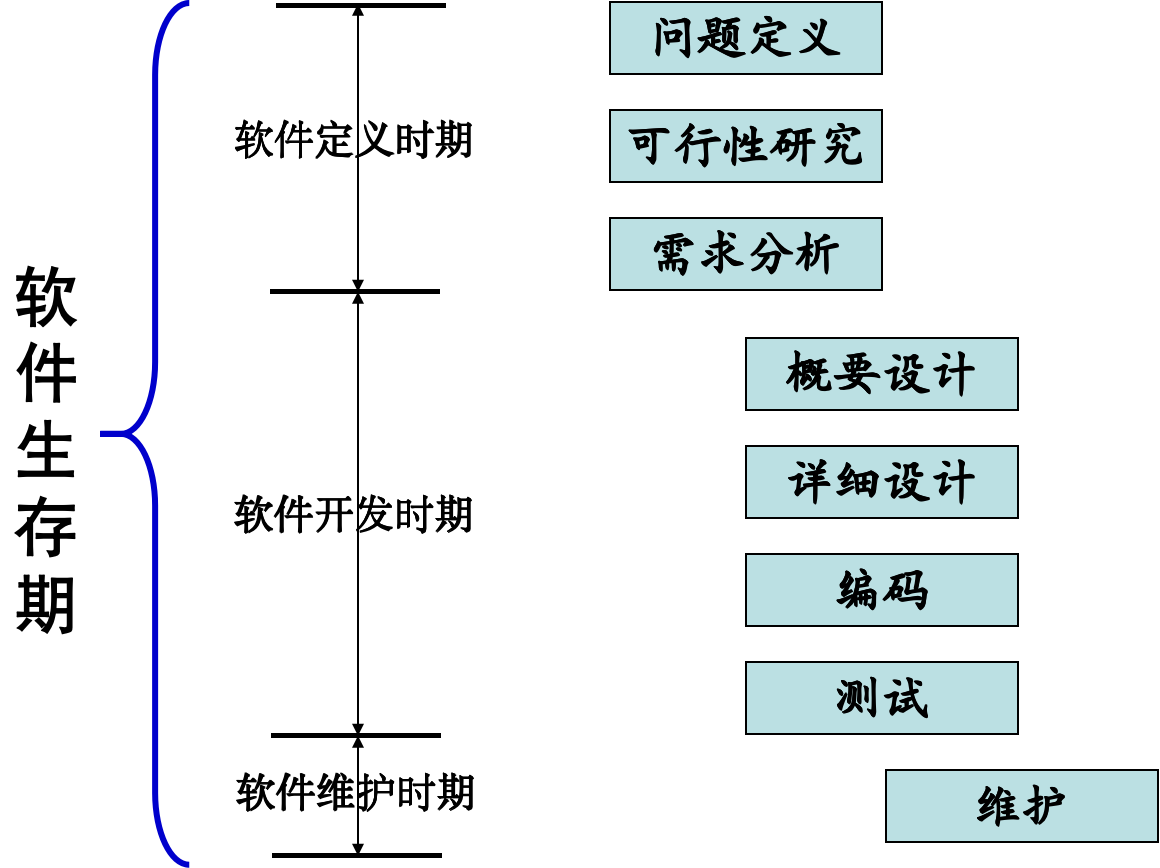
软件生存周期是指一个计算机软件从功能确定、设计到开发成功投入使用,并在使用中不断地修改、增补和完善,直到被新的需求所替代而停止该软件的使用的全过程。
- 问题定义与可行性研究:
- 问题定义必须回答的关键问题是:“要解决的问题是什么?“。软件生存周期中,用户主要是在软件定义期中参与软件开发
可行性研究要回答的关键问题是:“在成本和时间的限制条件下能否解决问题?是否值得做?”
可行性研究需要从
技术可行性、经济可行性、社会可行性三个方面分析研究每种解决方法的可行性。- 需求分析:这个阶段的任务仍然不是具体地解决客户的问题,而是准确地回答“目标系统必须做什么”
- 软件设计:本阶段要回答的关键问题是“目标系统如何做?”。为此,必须在设计阶段中制定设计方案,把已确定的各项需求转换成相应的软件体系结构。结构中的每一组成部分都是意义明确的构件,此即所谓概要设计。进而具体描述每个构件所要完成的工作,为源程序编写打下基础,此即所谓详细设计。
- 程序编码和单元测试:本阶段要解决的问题是“正确地实现已做的设计”,为此,需要选择合适的编程语言,把软件设计转换成计算机可以接受的程序代码,并对程序结构中的各个模块进行单元测试,然后运用调试的手段排除测试中发现的错误。要求编写出的程序应当是结构良好、清晰易读的,且与设计相一致的。
- 集成测试和系统测试:
- 集成测试的任务是将已测试过的模块按设计规定的顺序组装起来,在组装的过程中检查程序连接的问题。
- 系统测试的任务是根据需求规格说明的要求,对必须实现的各项需求,逐项进行确认,判定已开发的软件是否符合用户需求能否交付用户使用。为了更有效地发现系统中的问题,通常这个阶段的工作由开发人员、用户之外的第三者承担
- 运行维护:已交付的软件投入正式使用,便进入运行维护阶段。这一阶段可能持续若干年。软件在运行中可能由于多方面的原因,需要对它进行维护。通常有四种类型的维护:改正性维护、适应性维护、完善性维护、预防性维护
数据库设计与用户界面设计属于软件开发阶段的详细设计阶段
E-R 图是数据库设计概要设计阶段的工具
软件体系结构设计属于( 概要设计阶段 )
需求分析最终结果是产生( 需求规格说明书 )



首先需要进行概要的分析研究,初步确定项目的规模和目标,确定项目的约束和限制,把他们清楚地列举出来。然后,分析员进行简要的需求分析,抽象出该项目的逻辑结构,建立逻辑模型。从逻辑模型出发,经过压缩的设计,探索出若干种可供选择的主要解决方法,对每种解决方法都要研究它的可行性,可从以下三个方面分析研究每种解决方法的可行性。
㈠技术可行性:对要开发项目的功能、性能、限制条件进行分析,确定在现有的资源条件下,技术风险有多大,项目是否能实现。
㈡经济可行性:进行开发成本的估算以及了解取得效益的评估,确定要开发的项目是否值得投资开发。
㈢社会可行性:要开发的项目是否存在任何侵犯、妨碍等责任问题,要开发项目的运行方式在用户组织内是否行得通,现有管理制度、人员素质、操作方式是否可行。
需求分析阶段的基本任务是要准确的定义新系统的目标,为了满足用户需要,回答系统必须“做什么”的问题。本阶段要进行以下几方面的工作:
㈠问题识别。双方确定对问题的综合需求,这些需求包括:功能需求、性能需求、环境需求、用户界面需求,另外还有可靠性、安全性、保密性、可移植性、可维护性等方面的需求。
㈡分析与综合,导出软件的逻辑模型。分析人员对获取的需求,进行一致性的分析检查,在分析、综合中逐步细化软件功能,划分成各个子功能。这里也包括对数据域进行分解,并分配到各个子功能上,以确定系统的构成及主要成份,并用图文结合的形式,建立起新系统的逻辑模型。
㈢编写文档。编写“需求规格说明书”、编写初步用户使用手册、编写确认测试计划、修改完善软件开发计划。
单元测试是针对软件中最小的测试单元进行的测试,通常指的是函数或方法;
集成测试关注的是多个单元组合在一起的行为,并且着重测试它们的接口;
系统测试则是在整个软件系统层面上进行的综合测试,用以验证最终的系统是否符合规定的需求。
单元测试是一种软件测试方法,旨在对软件中最小的可测试单元进行验证。
这些最小的可测试单元通常是函数、方法或类。单元测试独立于其他组件,主要关注各个单元的相互作用和功能。
通过对各个单元的隔离测试,可以准确快速地发现问题,提高软件的质量和稳定性。
集成测试用于验证不同组件在一起工作时的功能和性能。
与单元测试不同的是,集成测试关注系统中多个组件之间的接口和协作。
在集成测试中,多个单元在一起进行测试,以确保它们正确地协同工作,并且不会因为组件之间的交互而产生问题。
系统测试是一种测试方法,用于验证整个软件系统的功能、性能和可靠性。
与单元测试和集成测试不同的是,系统测试主要关注软件系统与用户需求之间的匹配程度。
在系统测试中,测试人员会以用户的角度进行测试,模拟真实环境,并检查系统与用户需求之间的一致性和完整性。
系统测试的目的是确保软件系统能够按预期满足用户的需求。
软件工程的三种基本要素是方法、工具和过程
软件工程方法(method)为建造软件提供技术上的解决方法(“如何做”)。目前使用得最广泛的方法是传统方法(结构化方法)和面向对象方法工具为方法的运用提供自动的或半自动的软件支撑环境过程是为了获得高质量的软件所需要完成的一系列任务的框架,它规定了完成各项任务的工作步骤。
传统方法的特点
传统方法也称为生命周期方法或结构化范型。它采用结构化技术来完成软件开发的各项任务。这种方法学把软件生命周期的全过程依次划分为若干个阶段,然后顺序地逐步完成每个阶段的任务。
每一个阶段的开始和结束都有严格的标准,对于任何两个相邻的阶段而言前一个阶段的结束标准就是后一阶段的开始标准。 传统方法的主要缺点是在适应需求变化方面不够灵活,另外,结构化方法要么面向行为,要么面向数据,缺乏使两者有机结合的机制。
面向对象方法的特点
面向对象方法把数据和行为看成同等重要,是将数据和对数据的操作紧密地结合起来的方法,这也是面向对象方法与传统方法的重要区别。 面向对象方法的出发点和基本原则,是尽量模拟人类习惯的思维方式,使开发软件的方法和过程尽可能接近人类认识问题和解决问题的方法与过程,从而使描述问题的问题空间与其解空间在结构上尽可能一致。
对于大型、复杂及交互性比较强的系统,使用面向对象方法更有优势。
形式化方法的主要特点是:
- 软件需求规格说明被细化为用数学记号表达的详细的形式化规格说明
- 设计、实现和单元测试等开发过程由一个变换开发过程代替。通过一系列变换将形式的规格说明细化成为程序。
软件开发本质可以概括为:不同抽象层术语之间,以及不同抽象层处理逻辑之间的映射
在同一个应用中的共享是指在同一应用的类层次结构中,存在继承关系的各相似子类中,存在数据结构和行为的继承,使各相似子类共享共同的结构和行为。使用继承来实现代码的共享。
对象的抽象是类,类的实例化是对象
数据字典有四类条目,分别是数据流、数据项、数据存储、基本加工
软件设计的基本原理包括模块化、抽象、信息隐蔽、模块独立性
结构化分析设计方法
需求获取的基本过程、需求分析的四个步骤,结构化的分析方法分为数据建模、功能建模、行为建模。 功能建模里面分为数据流图,数据建模里面画的是ER图,行为建模里面画状态图。数据字典里面决策表决策树。 软件设计的原则。软件设计的任务。 数据流图转化为功能建模的功能模块图。接口设计恶化界面设计需要注意什么问题



- 发现和分析问题,并分析问题的原因/结果关系 (发现和分析问题👀)
- 与用户进行各种方式的交流,并使用调查研究方法收集信息 (交流收集信息😧,唠嗑)
- 按照3个成分即数据,过程,接口观察问题的不同侧面。 (换个jio🦶度重新分析)
- 将获取的需求文档化,形式有用例、决策表、决策树等 (写个文档😩🤮🤮)
- 深入浅出的原则 (给用户整轻松了整浅了,给哥们整的又深又苦😭)
- 以流程为主线的原则 (踏🐎的,怕您看不懂还得给你整一个流程串起来呢)
- 开发高层的业务模型 (给你整点高级的模型)
- 定义项目范围和高层需求 (也别太好了,求求你定义个范围🥺🤢)
- 识别用户类和用户代表 (得和你说是谁用吧💦)
- 获取具体的需求 (你得和我说是要干嘛吧😅
- 确定目标系统的业务工作流 (得给你串成流
- 需求整理与总结 (给您整理总结,行吧
- 需求获取 你不获取分析个🔨用
- 需求分析 你获取了不分析又有个🔨用
- 需求定义 分析了之后你才能定义系统
- 需求验证 你可别光说但是不验证吧?
结构化方法有结构化分析、结构化设计、结构化程序设计构成,它是一种面向数据流的开发方法。
结构化设计是一种面向数据流的设计方法
数据流图(DFD)描述数据在系统中如何被传送或变换,以及描述如何对数据流进行变换的功能(子功能),用于功能建模
实体-关系图(ER图)描述数据对象及数据对象之间的关系,用于数据建模
状态-迁移图(STD)描述系统对外部事件如何响应、如何动作,用于行为建模
数据源或者数据汇点表示图中要处理数据的输入来源或处理结果要送往何处
数据流表示数据沿箭头方向的流动
加工是对数据对象的处理或变换
数据存储在数据流图中起保存数据的作用,可以是数据库文件或任何形式的数据组织
环境图仅包括一个数据处理过程,也就是要开发的目标系统。环境图的作用是确定系统在其环境中的位置,通过确定系统的输入和输出于外部实体间关系确定其边界
画数据流图的基本步骤概括为自外向内、自顶向下、逐层细化、完善求精。
数据建模的三要素分别为数据对象(实体)、属性、关系。
结构化分析的基本思想是自顶向下逐步分解
结构化程序设计主要强调程序的易读性
面向对象软件开发方法中,类与类之间是继承和聚集的关系
结构化语言是介于自然语言(英语和汉语)和形式化语言之间的一种半形式语言。它的结构可分成外层和内层两层,外层用来描述控制结构,采用的三种基本控制结构:顺序、选择、循环
程序的三种基本控制结构的共同特点是单入口单出口
数据字典中有四类条目:数据流、数据项、数据存储、加工。
三种描述加工逻辑的工具各有优缺点,对于顺序执行和循环执行的动作,用结构化语言描述。对于存在多个条件复杂组合的判断问题,用判定表和判定树。
结构化分析中对加工出现的组合条件的说明工具是判定树和判定表
判定树和判定表是数据流图中用以描述加工的工具,它常描述的对象是组合条件
结构化分析方法以数据流图、数据字典和加工说明等描述工具,用直观的图和简洁的语言来描述系统模型
结构设计是一种应用最广泛的系统设计方法,是以数据流为基础、自顶向下、逐步求精和模块化的过程,特别适合于数据处理领域的问题。
结构化方法由结构化分析、结构化设计、结构化程序设计构成。它是一种面向数据流的开发方法。
面向对象开发方法包括面向对象分析、面向对象设计、面向对象实现三个部分
结构化设计对数据流有两种分析方法,他们是变换分析设计和事务分析设计。
- 分而治之
- 模块独立性
- 提高抽象特征
- 复用性设计
灵活性设计
美国`分`裂闹`独`立,`灵活|复`活毕加索(抽象0.0)
结构化软件设计分为体系结构设计、接口设计、数据设计、过程设计
软件可以分为软件模块结构和软件的数据结构
模块是程序语句按逻辑关系建立起来的组合体
不能再分解的模块称为原子模块
模块分为传入模块、传出模块、变换模块和协调模块
结构图的上下级模块之间存在主从关系,即自上而下是“主宰”关系,自下而上是“从属”关系
结构图中同一层的最大模块数称为结构图的宽度,层数为结构图的深度
数据结构是数据的各个元素之间逻辑关系的一种表示
数据流图分为变换型数据流图和事务性数据流图
变换型数据处理问题的工作分为3步,即取得数据、变换数据和给出数据,变换数据是数据处理过程的核心工作
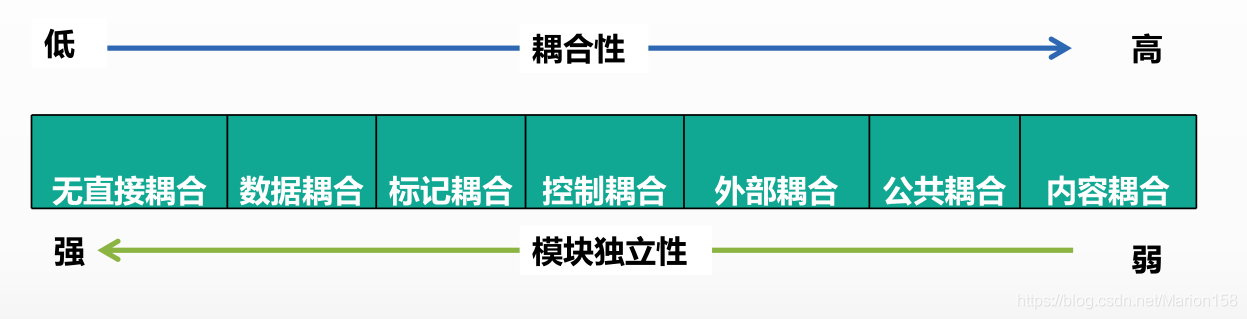
耦合是程序结构中各个模块之间的相关关联的度量,它取决于各个模块之间接口的复杂程度、调用模块的方式以及通过接口的信息类型。
内容耦合(模块独立性最弱)
- 一个模块直接访问另一个模块的内部数据
- 一个模块不通过正常入口转到另一个模块内部
- 两个模块有一部分程序代码重叠
- 一个模块有多个入口
公共耦合:一组模块都访问同一个公共数据环境。公共数据环境可以是全局的数据结构、共享的通信区、内存的公共覆盖区
外部耦合:若有一组模块都访问同一简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息
控制耦合:一个模块传给另一模块的参数中包含了控制信息,该控制信息用于控制接受模块中的执行逻辑。控制模块必须知道被控制模块的内部一些逻辑关系。允许发生但是减少
标记耦合:一组模块通过参数表来传递接受信息。尽量避免这种耦合,采取“信息隐蔽”的方法,把在数据结构上的操作都集中在一个模块中,可以消除这种耦合
数据耦合:仅通过参数表传递简单数据。在软件程序结构中至少必须有这类耦合
非直接耦合:两个模块之间没有直接关系,它们之间完全是通过主模块控制和调用实现的
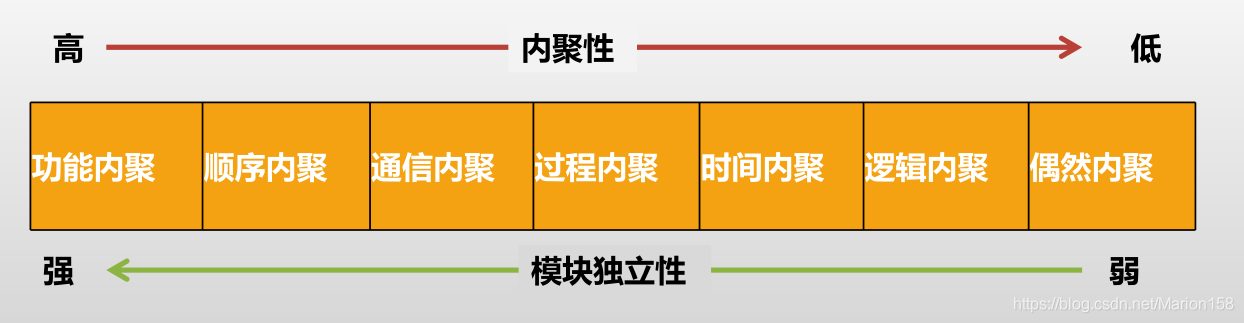
内聚是一个模块内部各个元素彼此结合的紧密程度的度量
巧合内聚(偶然内聚):模块内个部分之间没有联系,或者即使有联系也很松散
逻辑内聚:模块把几种相关的功能组合在一起,每次调用时,由传送给模块的判定参数来确定该模块应该执行哪一种功能。不容易修改
时间内聚(经典内聚):要求所有功能在同一时间段内执行。例如初始化模块和终止模块。不能避免
过程内聚:模块内的处理是相关的,而且必须以特定次序执行。过程内聚程度比时间内聚更强
通信内聚:一个模块内各功能部分都使用了相同的输入数据,或产生了相同的输出数据。使用相同的输入/输出缓冲区,因而降低了效率
信息内聚:模块各个功能都在同一数据结构上操作,每一项功能有一个唯一的入口点
功能内聚:所有部分都是为完成一项具体功能而协同工作。容易修改和维护
划分模块时尽量做到高内聚低耦合,保持模块的独立性,尽量使用公共模块
衡量模块独立性的两个定性标准是耦合性和内聚性
内聚是从功能角度来度量模块内的联系,耦合是度量模块之间联系的程度
软件结构中各模块之间相互连接的关系的一种度量常称为模块的耦合
为了提高模块的独立性,模块内部最好的是功能内聚
内聚程度最低的是巧合内聚
如果某种内聚要求一个模块中包含的任务必须在同一时间内执行,则称这种内聚为时间内聚
为了提高模块的独立性,模块之间联系最好,耦合性最弱、信息隐蔽性最好的是数据耦合
当一个模块直接使用另一个模块的内部数据,这种模块之间的耦合称为内容耦合
一个软件结构中,同一层次上模块总数最大值是指模块的宽度
一个模块向其下属模块传递了一个开关量信息,则该模块与下属模块的关系是控制耦合
如果两个模块都使用一张表,这种模块的耦合叫做公共耦合
软件模块结构的改进方法
- 模块功能的完善化
- 消除重复功能改善软件结构
- 模块的作用范围应在控制范围之内
- 尽可能减少高扇出结构,随着深度增大扇入
- 避免或减少使用病态连接
- 模块的大小要适中
在设计中引入灵活性的方法有:
- 降低耦合并提高内聚(易于提高替换能力)
- 建立抽象(创建有多态操作的接口和父类)
- 不要将代码写死(消除代码中的常数)
- 抛出异常(由操作的调用者处理异常)
- 使用并创建可复用的代码。
接口设计分为:
- 模块或软件构件间的接口设计
- 软件与其他软硬件系统之间的接口设计
- 软件和人之间的接口设计
人机交互界面是人机交互的主要方式
用户界面应具备的特性
- 可使用性
- 灵活性
- 可靠性
人机交互的准则
- 一致性
- 操作步骤少
- 不要“哑播放”
- 提供Undo功能
- 减少人脑的记忆负担
- 提高学习效率
结构化程序设计的7个原则:
- 使用语言中的顺序、选择、重复等有限的基本控制结构表示程序逻辑
- 选用的控制结构只准许有一个入口和一个出口
- 程序语句组成简单容易识别的块,每块只有一个入口和一个出口
- 复杂结构应该用基本控制结构进行组合嵌套来实现
- 语言中没有的控制结构,可以用一段等价的程序段模拟,但要求该程序段在整个系统中一致
严格控制GOTO语句- 尽量使用自顶向下和逐步细化的原则
将大的软件划分成独立命名且可独立访问的模块,不同的模块通常具有不同的功能或职责。这种方法有利于将复杂的问题简单化,是分而治之策略的具体表现。
尽管模块分解可以简化要解决的问题,但模块分解并不是越小越好。当模块数目增加时每个模块的规模将减小,开发单个模块的成本确实减少了;
但是,随着模块数目增加,模块之间关系的复杂程度也会增加,设计模块间接口所需要的工作量也将增加。划分模块的依据是,模块只具有单一的功能且与其他模块没有太多的联系
软件生存周期模型
模型只需要看瀑布模型、快速原型模型、增量模型、螺旋模型、喷泉模型、敏捷过程(华为)。 敏捷开发里面的敏捷宣言、敏捷的十二条基本原则
构造原型时,必须注意功能性能取舍,忽略一切暂不关心的部件
瀑布模型
瀑布模型的特点是(阶段间顺序性和依赖性),(推迟实现的观点),(质量保证的观点)。
瀑布模型是整体开发模型,增量模型是非整体开发模型
瀑布模型不适应需求可变的软件开发,只有到开发结束之后才能见到整个软件系统
瀑布模型强迫开发开发人员采取规范化的方法进行开发,严格规定了每个阶段必须提交的文档,要求每个阶段交出所有的产品必须经过验证
瀑布模型的关键不足在于不能适应需求的动态变更,只适用项目开始时需求已经确定的情况
瀑布模型生命周期的八个阶段中,最容易出错对软件影响最大的是需求分析阶段
瀑布模型本质上是一种线性模型
在结构性的瀑布模型中,需求分析阶段定义的标准将成为软件测试中的系统测试阶段的目标。
软件开发中常采用的结构化生命周期方法,由于其特征一般称其为瀑布模型
规定了由前到后、相互衔接的固定次序的模型是瀑布模型
软件开发的瀑布模型,一般都将开发过程划分为:分析、设计、编码和测试等阶段,一般认为可能占用人员最多的阶段是编码阶段。
瀑布模型中软件生命周期划分为八个阶段:问题的定义、可行性研究、软件需求分析、系统总体设计、详细设计、编码、测试和运行、维护。八个阶段又可归纳为三个大的阶段:计划阶段,开发阶段和运行阶段。
从结构化的瀑布模型看,在软件生命周期中的八个阶段中,需求分析阶段出错,对软件的影响最大。
瀑布模型的优点:
- 可强迫开发人员采用
规范化的方法 - 严格规定了每个阶段必须提交的
文档 - 要求每个阶段交出的所有产品都是必须
经过**验证**的
瀑布模型的缺点:
- 完全依赖书面的规范说明,导致产品难以满足用户需要
- 项目开始时需求需要确定
实际的瀑布模型带有“反馈环”
喷泉模型
喷泉模型是一种以(用户需求)为动力,以(对象)作为驱动的模型,适合于(面向对象)的开发方法。它克服了瀑布模型不支持软件重用和多项开发活动集成的局限性。喷泉模型使开发过程具有(迭代性)和(无间隙性)。
喷泉模型是典型的面向对象生命周期模型
各阶段工作自顶向下,从抽象到具体顺序进行,一般用( 喷泉模型 )模型来模拟。
快速原型模型
快速原型模型所完成的功能往往是最终产品的一个(子集),开发过程基本不带“反馈环”,基本是按线性顺序进行
原型化方法是一种自外向内的设计过程,有助于满**足用户真实需求**
快速原型是利用原型辅助软件开发的一种新思想,它是在研究需求分析方法和技术中产生的
快速原型是利用原型辅助软件开发的一种新思想。是在原型的基础上,逐渐完成整个系统的开发工作。经过简单快速分析,快速实现一个原型,用户与开发者在试用原型过程中加强通信与反馈,通过反复评价和改进原型,减少误解,弥补遗漏,适应变化,最终提高软件质量
软件开发中的原型是软件的一个早期可运行的版本,它反映了最终系统的重要特性
增量模型
增量模型开发软件时,把软件产品作为一系列的增量构件来设计、编码、集成、测试
第一个增量构件往往实现软件的基本需求,提供最核心的功能,优先级高的首先交付。
增量模型比采用瀑布模型需要更精心的设计

增量构造模型是在瀑布模型基础上,对一些阶段进行整体开发,对另一些阶段进行增量开发。
增量构造模型是指,在前面的开发阶段按瀑布模型进行整体开发,后面的开发阶段按增量方式开发。在这种模型的开发中,用户及早看到部分软件功能,可以及早发现全面问题,以便在开发其他软件功能时及时解决问题。
增量模型是在项目的开发过程中以一系列的增量方式开发系统。增量方式包括增量开发和增量提交。可同时使用也可以单独使用。
增量模型和瀑布模型之间的本质区别是:瀑布模型属于整体开发模型,它规定在开始下一个阶段的工作之前,必须完成前一阶段的所有细节。而增量模型属于非整体开发模型,它推迟某些阶段和所有阶段中的细节,从而较早地产生工作软件。
增量模型是一种非整体开发的模型。软件在该模型中是“逐渐”开发出来的,开发出一部分,向用户展示一部分,可让用户及早看到部分软件,及早发现问题。或者先开发一个“原型”软件,完成部分主要功能,展示给用户并征求意见,然后逐步完善,最终获得满意的软件产品。
增量模型存在的主要问题是缺乏丰富而强有力的软件工具和开发环境
增量模型在开发过程中以一系列增量方式开发系统,推迟某阶段的细节,从而尽早产生工作软件
在常见的软件开发模型中,适用于发布版本快,可减少用户需求变更的模型是增量模型
增量模型根据增量方式和形式的不同,分为渐增模型和原型模型
增量构造模型在需求分析和设计阶段按整体方式开发,但是在编码和测试阶段按增量方式开发
在快速原型模型的开发过程中,用原型过程来代替全部开发阶段所用的模型是演化型原型
快速原型模型的主要特点之一是尽早提供工作材料
增量模型软件体系结构是开放的
为了克服瀑布模型的局限性,使开发过程具有一定的灵活性和可修改性,于是产生了增量模型。
它是在瀑布模型的基础上加以修改而形成的。增
量模型和瀑布模型之间的本质区别是:
瀑布模型属于整体开发模型,它规定在开始下一个阶段的工作之前,必须完成前一阶段的所有细节。
而增量模型属于非整体开发模型,它推迟某些阶段或所有阶段中的细节,从而较早的产生工作软件。
增量模型是在项目的开发过程中以一系列的增量方式开发系统。
增量方式包括增量开发和增量提交。
增量开发是指在项目开发周期内,以一定的时间间隔开发部分工作软件;
增量提交是指在项目开发周期内,以一定的时间间隔增量方式向用户提交工作软件及相应文档。
增量开发和增量提交可以同时使用,也可以单独使用。
螺旋模型
螺旋模型是一种将瀑布模型和快速原型模型的结合起来,加入了两种模型均忽略了的风险分析,弥补了这两种模型的不足。可以看成在每个阶段之前都增加了风险分析过程的快速原型模型
具有风险分析的软件生存周期模型是螺旋模型,适用于项目开发的风险很大或用户不能确定情况
螺旋模型将开发过程分为几个螺旋周期,在每个螺旋周期内分为四个工作步骤。第一步制定计划,确定目标,选定实施方案,明确开发限制条件。第二步风险分析,分析所选方案,识别风险,通过原型消除风险。第三步开发实施,实施软件开发。第四步用户评估,评价开发工作,提出修改意见,建立下一个周期的计划。
书上写的是:目标设定、风险评估与弱化、开发与验证、计划
螺旋模型吸收了软件工程“演化”的概念,适合于大型软件的开发
螺旋模型是(风险驱动)的,因此要求软件开发人员必须具备丰富的风险评估经验和这方面的专业知识。
敏捷开发
敏捷原则
- 我们最优先要做的是通过尽早、持续交付有价值的软件来使客户满意。
- 即使在开发的后期,也欢迎需求变更。敏捷过程利用变更为客户创造竞争优势。
- 经常交付可运行软件,交付的间隔可以从几个星期到几个月,交付的时间间隔越短越好。
- 在整个项目开发期间,业务人员和开发人员必须天天都在一起工作。
- 围绕有积极性的个人构建项目。给他们提供所需的环境和支持,并且信任他们能够完成工作。
- 在团队内部,最富有效果和效率的信息传递方法是面对面交谈。
- 可运行软件是进度的首要度量标准。
- 提倡可持续的开发速度。责任人(sponsor)、开发者和用户应该能够长期保持稳定的开发速度。
- 不断地关注优秀的技能和好的设计会增强敏捷能力。
- 简单——是减少不必要工作量的艺术——是必要的
- 最好的架构、需求和设计出自于自组织团队。
- 每隔一定时间,团队会反省如何才能更有效地工作,并相应调整自己的行为。
敏捷开发宣言
- 个体和交互胜过过程和工具
- 可工作软件胜过宽泛的文档
- 客户合作胜过合同谈判
- 响应变更胜过遵循计划
Scrum开发模型中3个角色分别是:产品负责人、Scrum Master;Scrum团队
Scrum过程模式:待定项、冲刺、Scrum例会、演示
3个工件:产品Backlog;SprintBacklog;燃尽图
5个活动:Sprint计划会议、每日站会、Sprint评审会议、Sprint回顾会议、产品Backlog梳理会议
Scrum的价值观:承诺、尊重、勇气、专注、公开(承诺要尊重有勇气专注公开的人
极限编程XP的价值观:沟通、简单、反馈、勇气、尊重(尊重简单沟通勇敢反馈的人
XP包含(策划)、(设计)、(编码)和(测试)4个框架活动的规则和实践
XP鼓励既是(构建技术)又是(设计优化方法的“重构”)
XP的中心思想是(设计可以在编码开始前后同时进行)
在编码开始之前建立**(单元测试)**是XP方法的关键因素
极限编程的十个实践
- 完整的团队
- 增量式规划
- 客户参与全过程
简单设计- 结对编程
- 测试驱动开发
- 适时重构
- 持续集成
- 代码归集体所有
- 其他
精益-敏捷的9个原则
- 采取经济原则
- 运用系统思考
- 接受变异性,保留可选项
- 通关快速集成学习环、进行增量式构建
- 基于对工作系统的客观评价设立里程碑
- 可视化和限制在制品,减少批次规模,管理队列长度
- 应用节奏,通过跨领域计划进行同步
- 释放知识工作者的内在压力
- 去中心化的决策
敏捷关键词:迭代
软性系统的内在特性:复杂性
敏捷关键词:反馈
软件系统的内在特性:可变性、不可见性
与反馈相关的7个实践
- 测试驱动开发
- 结对编程
- 持续集成
- 状态墙
- 每日站会
- 迭代演示
- 迭代回顾会议
用户故事三要素:角色(使用者);功能(要完成怎么样的功能);价值(为什么)
用户故事3C原则:卡片(用来描述故事);会话(与用户交谈明确细节);确认(验收评审,确认呗正确完成,验收测试用例)
测试驱动开发
- 快速新增一个测试
- 运行所有测试,发现新的测试不能通过
- 做一些小小改动
- 运行所有测试,并且全部通过
- 重构代码,以消除重复设计,优化设计结构
DevOps的特点是:持续交付、持续反馈、持续改进
面向对象设计
程序中的对象分为五类:物理对象、角色、事件、交互、规格说明
建立对象模型的时区分实体类、边界类和控制类
实体类表示系统将跟踪的持久信息
边界类表示参与者与系统之间的交互
控制类负责用例的实现
面向对象方法学建模得到的三个基本子模型是:(对象模型)、(动态模型)、(功能模型)。
数据流图中信息流的类型有(变换流)和事务流。
复杂大型问题的对象模型通常由主题层、类与对象层、结构层、(属性层 )、及服务层 5个层次组







面向对象设计6大准则:模块化、抽象、信息隐蔽、弱耦合、强内聚、可重用。
模块抽信息,你强我弱可重用
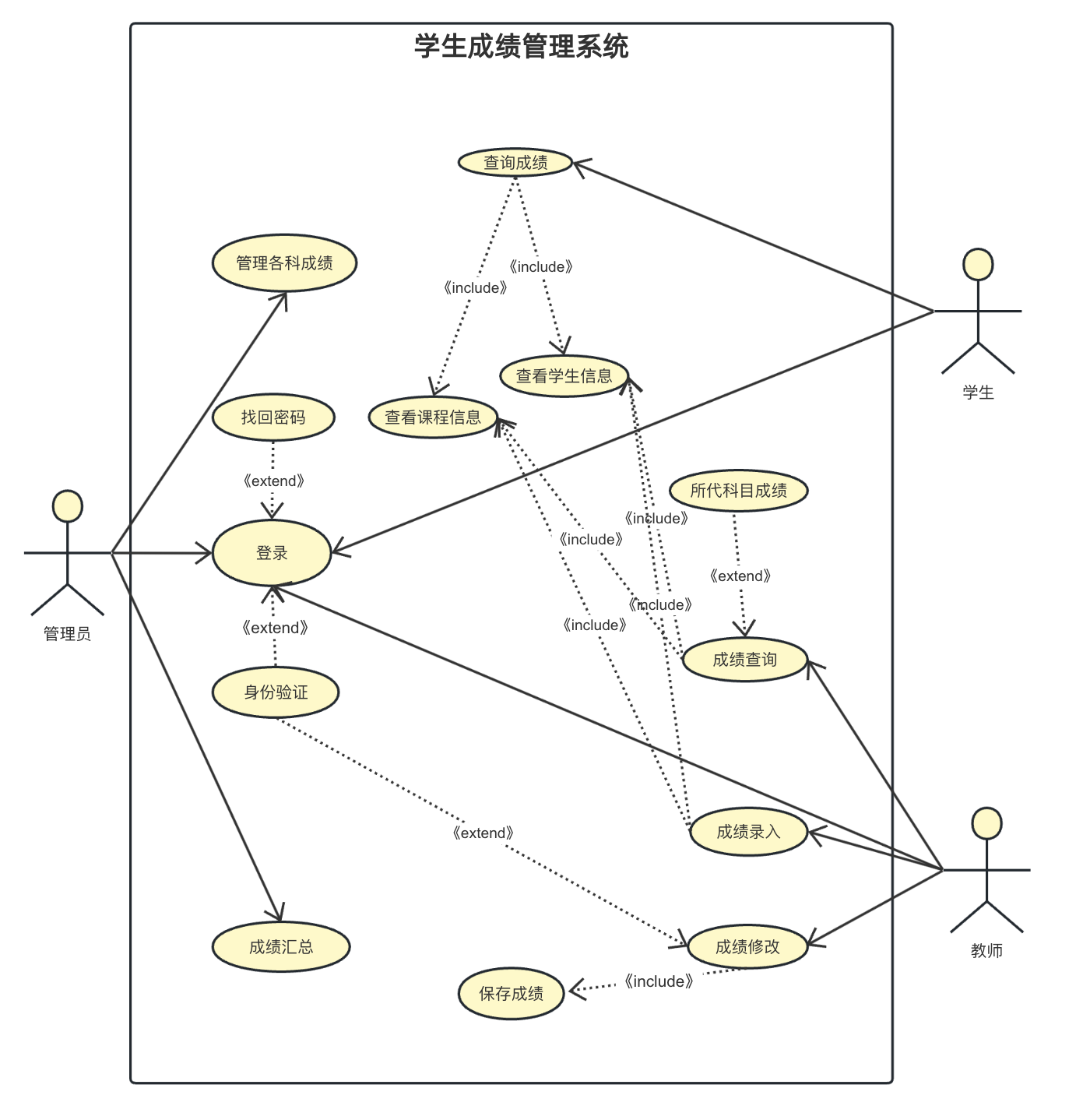
面向对象的分析方法使用用例模型来表示用户的功能需求,用例模型相当于功能模型在对用例模型进行细化的过程中,也伴随着对功能的分解。
但面向对象的分析方法并不是以功能分解为核心,在获取并分析用户的功能需求之后,重点以类和对象为核心,建立对象模型,交互模型也是围绕对象模型进行的。
面向数据流的分析方法是从建立顶层数据流图(环境图)开始,之后逐层对加工进行分解。面向数据流的分析方法是以功能分解为核心的。
用例建模的主要步骤如下:
- 确定业务参与者–可以是与系统有交互的外部硬件、软件、组织、人等。
- 确定业务需求用例–参与者需要系统提供的完整功能。
- 创建用例图–标识参与者与用例之间、用例与用例之间的关系。
用例之间的关系主要有《包含》(也称《使用》)和《扩展》。
- 《包含》表示一个用例所执行的功能中总是
包括被包含用例的功能; - 《扩展》是指一个用例的执行可能
需要由其他用例的功能来扩展,《扩展》联系可用于对期望或可选的行为建模但其主要用途是使基本用例的功能不依赖于扩展用例。
面向对象分析需要建立的3个模型是:由用例和场景表示的功能模型(用例模型);用类和对象表示的静态模型(对象模型);由状态图和顺序图表示的动态模型(交互模型)。
本质上,两个包之间的依赖性来自于两个包中类之间的依赖性。类之间的循环依赖性是个特别棘手的问题,好在大多数情况下可以通过重新设计避免循环依赖性。具体方法是增加新包。举例说明如下:
包 A 依赖于包 B,反过来包B 又依赖包 A,构成了循环依赖。具体解决办法是:将包B 依赖的包A 中的元素从包A 中分离出来,组成包 C,使得包B 不再依赖包 A,而是依赖包 C。
功能模型(用例图)、对象模型(类图、实体类、边界类、控制类)、动态模型(顺序图、状态图)
典型的面向对象设计模型在逻辑上将系统划分为4个部分,分别是问题域部分、人机交互部分、任务管理部分及数据管理部分。
问题域部分的设计
在面向对象设计过程中,可能要对面向对象分析所得出的问题域模型进行补充或调整例如,调整需求、复用已有的类、把问题域类组合在一起、增添泛化类以建立类间的协议调整继承的支持级别、改进性能等。
人机交互部分的设计
人机交互界面的设计质量直接影响到用户对软件的使用。在设计阶段,必须根据需求把交互细节加入到用户界面设计中,包括人机交互所必需的实际显示和输入。
任务管理部分的设计
任务管理主要包括任务的选择和调整。常见的任务有事件驱动型任务、时钟驱动型任务优先任务、关键任务和协调任务等。 设计任务管理子系统时,需要确定各类任务,并将任务分配给适当的硬件或软件去执行。
数据管理的设计
在采用面向对象方法进行软件开发时,数据的存储还是普遍使用关系数据库。在面向对象设计中,可以将UML类图看作是数据库的概念模型,一个类可以映射为一个表或多个表,此外,还要考虑类之间的关联关系、继承关系的映射。
画图
UML语言定义了五种类型,9种不同图
- 用例图(Use case diagram) 从用户角度
描述系统功能,并指出各功能的操作者。 - 静态图(Static diagram),表示
系统的静态结构。包括类图、对象图、包图。 - 行为图(Behavior diagram),描述系统的
动态模型和组成对象间的交互关系。包括状态图、活动图。 - 交互图(Interactive diagram), 描述
对象间的交互关系。包括顺序图、合作图。 - 实现图( Implementation diagram ) 用于描述
系统的物理实现。包括构件图、部件图。
UML的图形化工具分为两种:结构图和行为图

程序流程图(框图)中的箭头表示控制流
状态图反映了状态和事件之间的关系,状态图确定了由事件序列引起的状态序列
软件结构图中,模块框之间若有直线连接,表示他们之间存在调用关系
顺序图中返回消息用带箭头的虚线表示
类图可以可视化的表达系统的静态结构模型
用例图不包括数据流,用例图是用户使用描述系统功能的图形表达方法
用例图中的参与者可以算是一种分析类,应该归位实体类
数据流图中,有名字有方向的成分是数据流,不能由计算机处理的成分是数据源/终点,每个数据加工至少有一个输入流,一个输出流
0层数据流图有1个数据加工
数据流图的主图上的数据流必须封闭在外部实体之间
在数据流图中,从数据存储输出的数据流可以不给出命名
数据字典是用来定义数据流图中的各个成分的具体含义,是数据流图中信息的集合,它对数据流图上的每一个成分、数据项、文件(数据结构)、数据流、数据存储、加工和外部项等给以定义和说明;它主要由数据流描述、加工描述和文件描述组成
数据字典包括数据流、加工、数据文件、数据元素、以及数据源点和数据汇点等,数据字典成为3种分析模型黏合在一起的“黏合剂”,是分析模型的“核心”
数据词条分为数据流词条、数据元素词条、数据存储文件词条、加工词条、数据源点及汇点词条。
在对数据流图的分解中,位于层次树最底层的加工也称为基本加工或子加工,对于每一个基本加工都需要进一步说明,这称为加工规格说明
数据流图里的数据流包括变换型和事务性
数据流图中有四种基本符号:圆框代表变换/加工,方框代表外部实体,箭头代表数据流,双杠代表数据存储

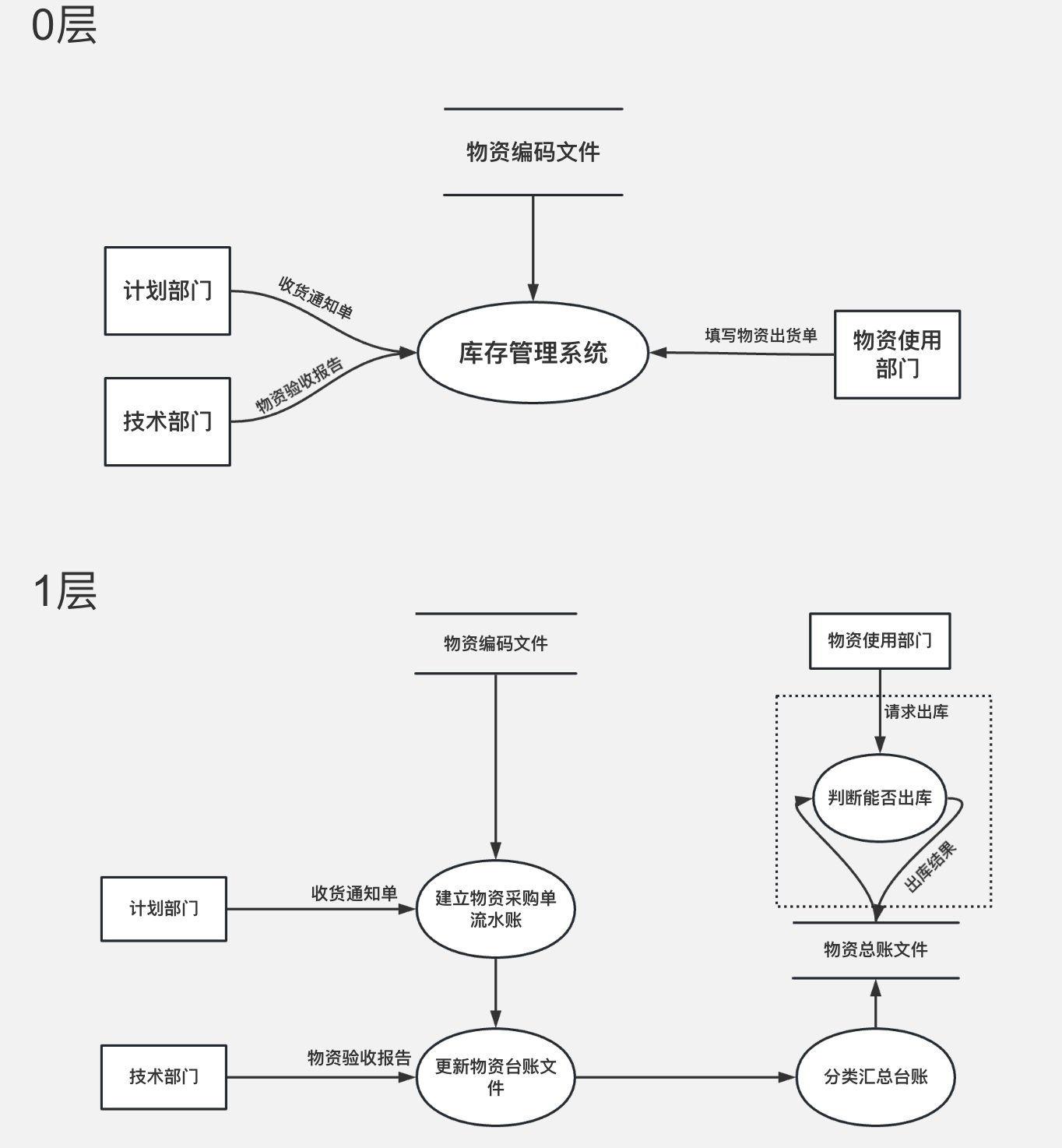
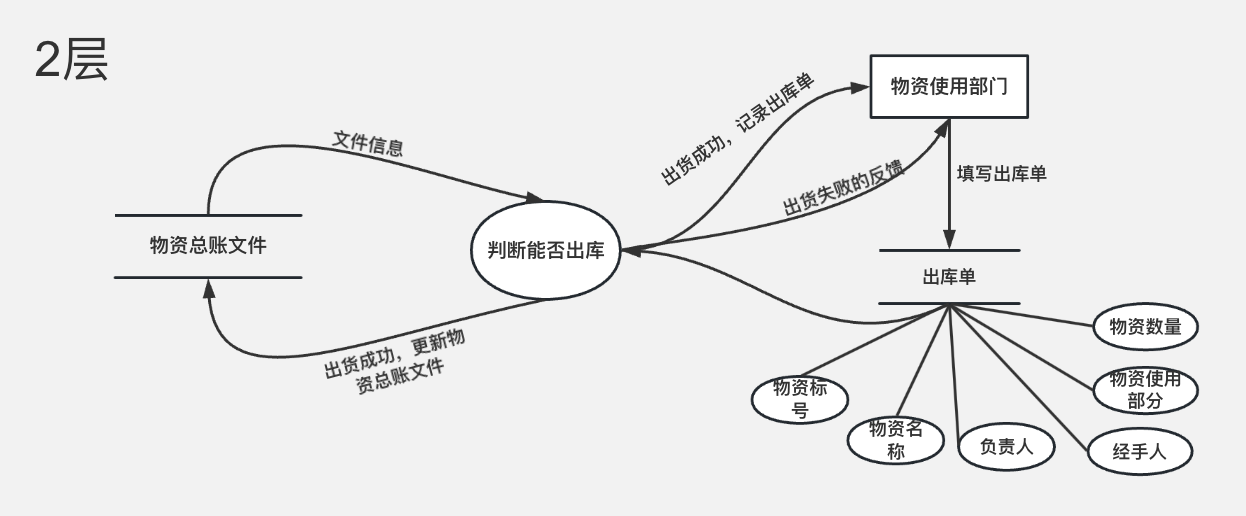
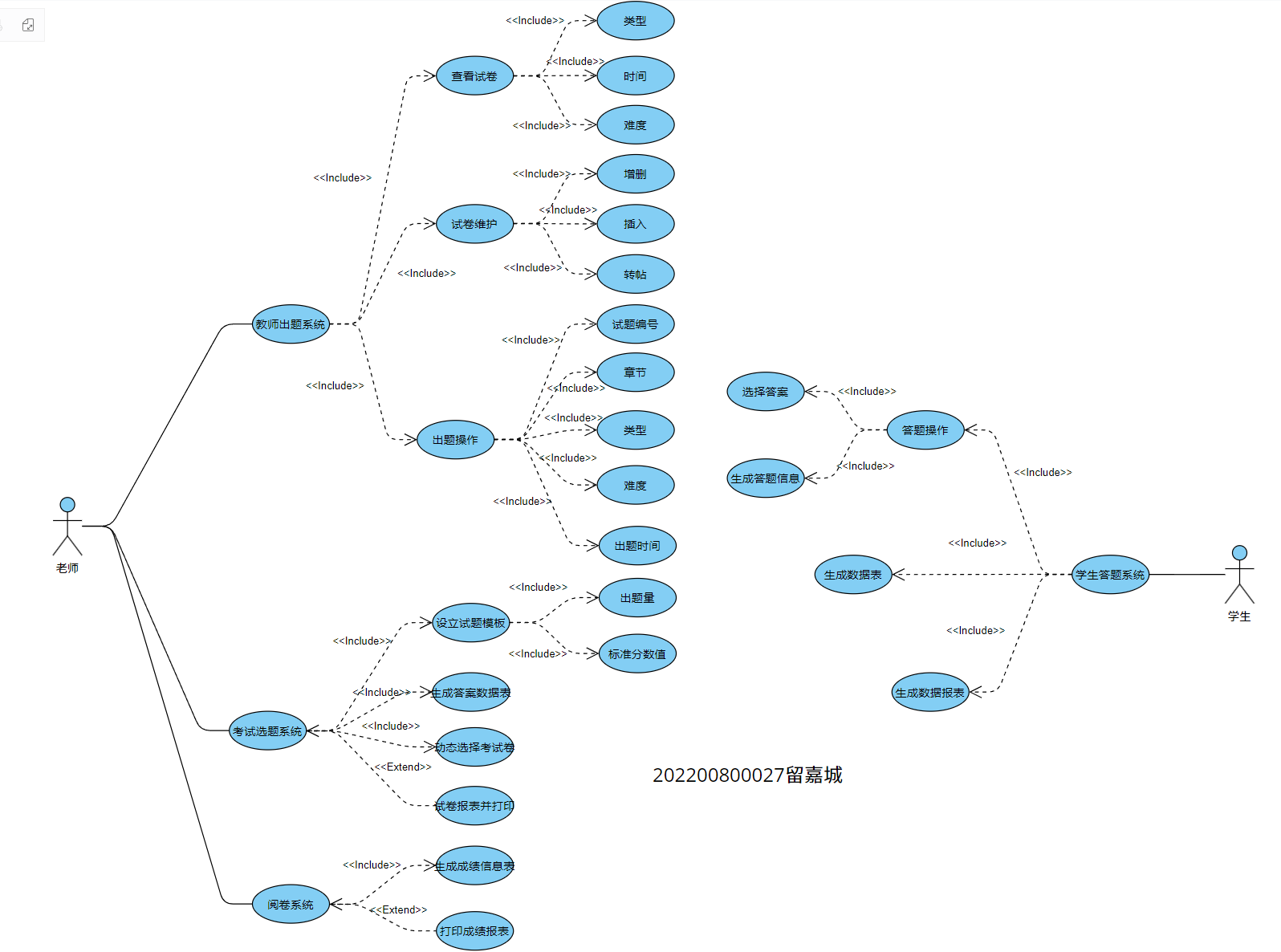
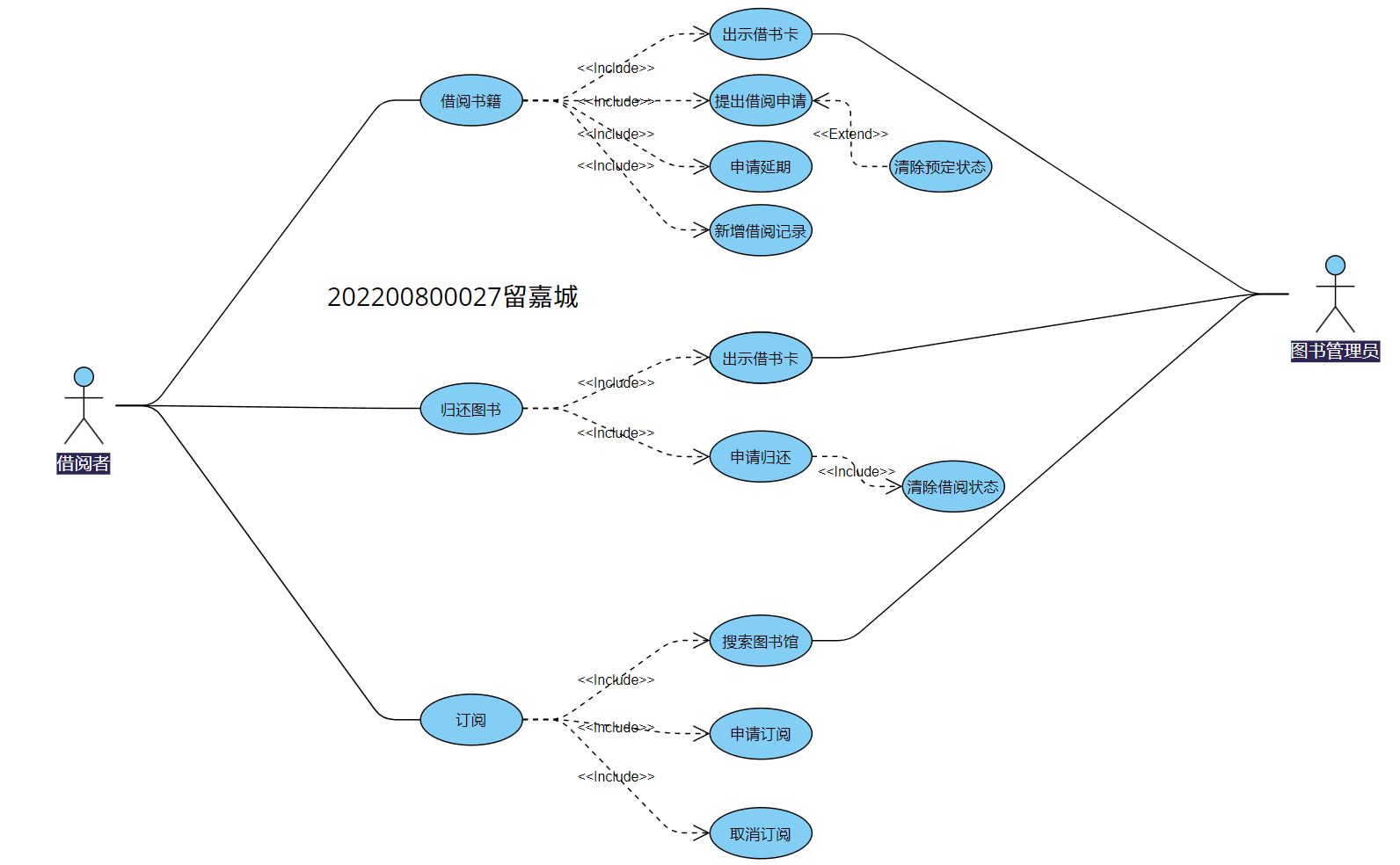
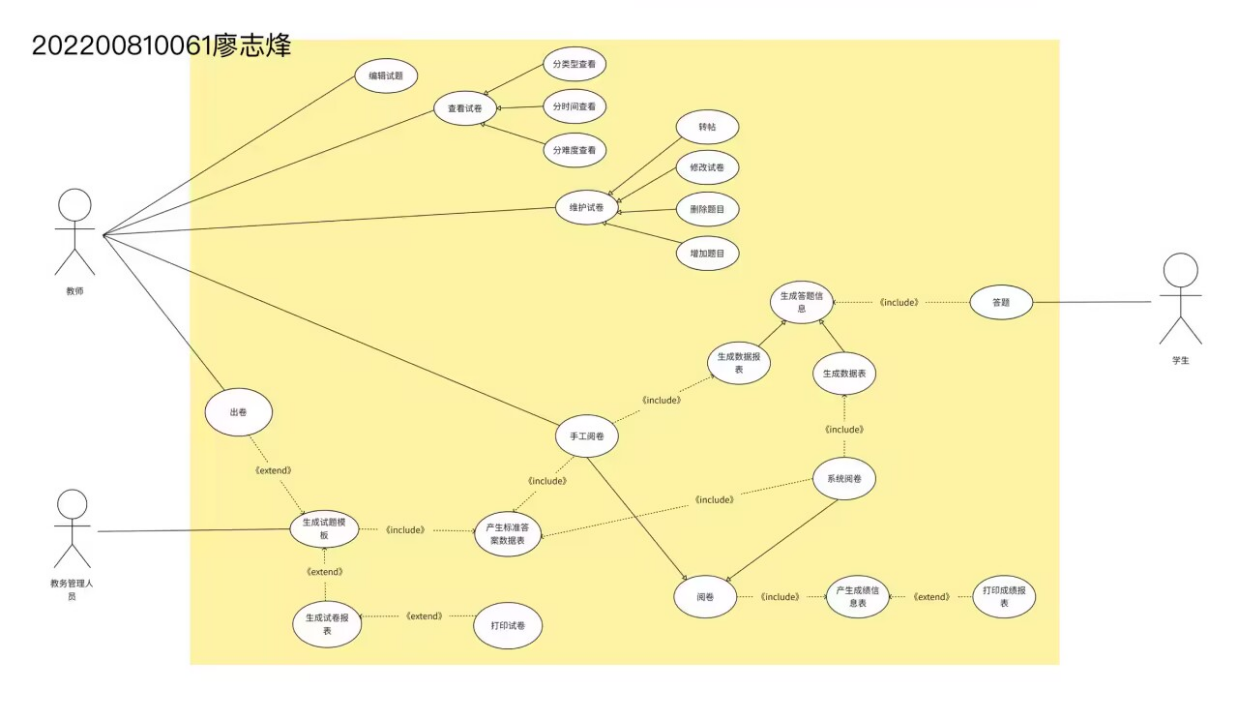
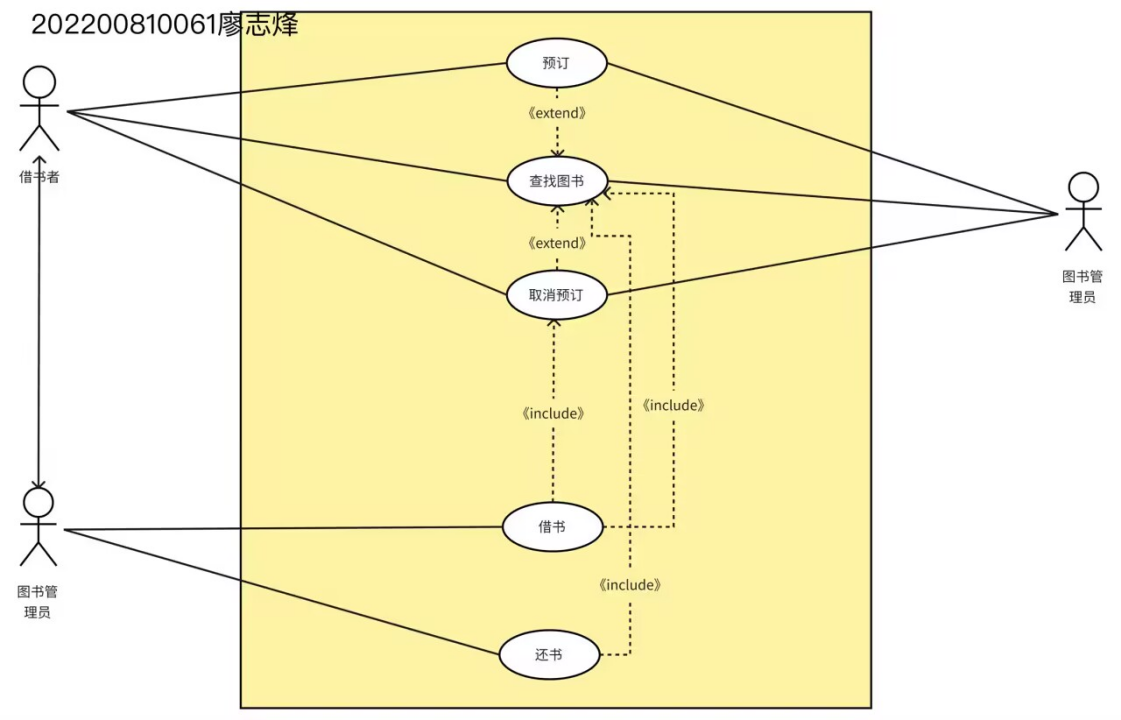
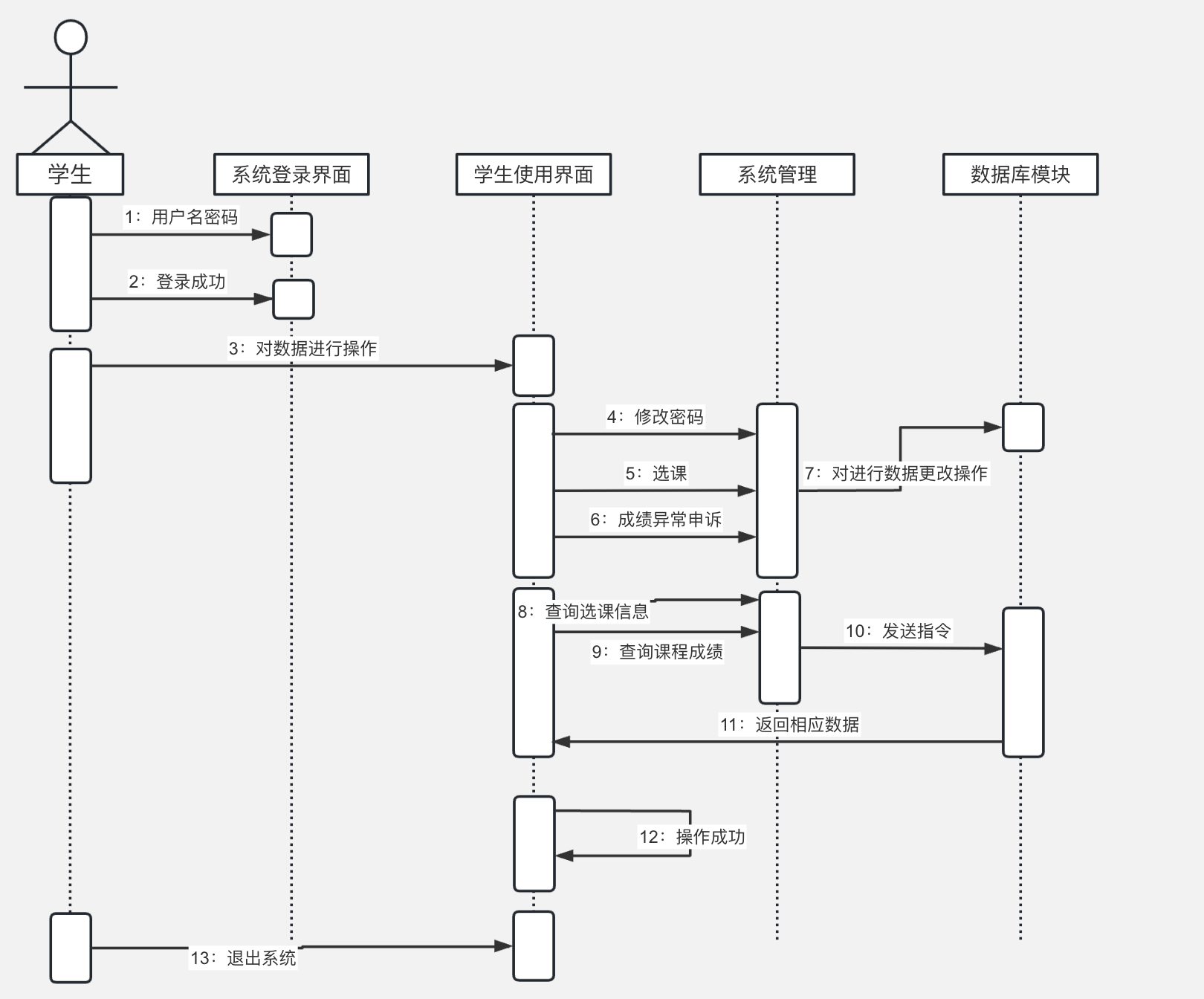
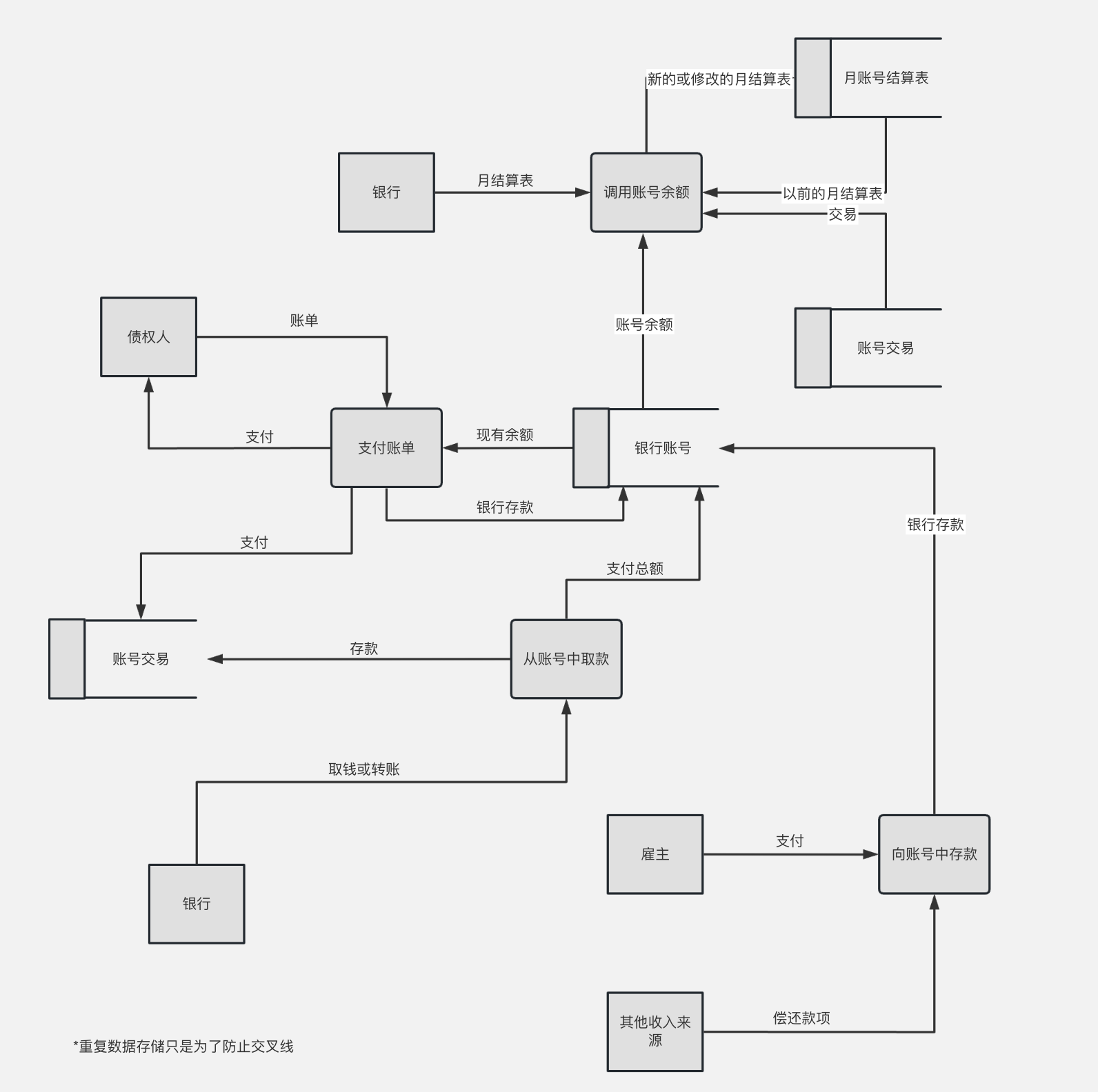
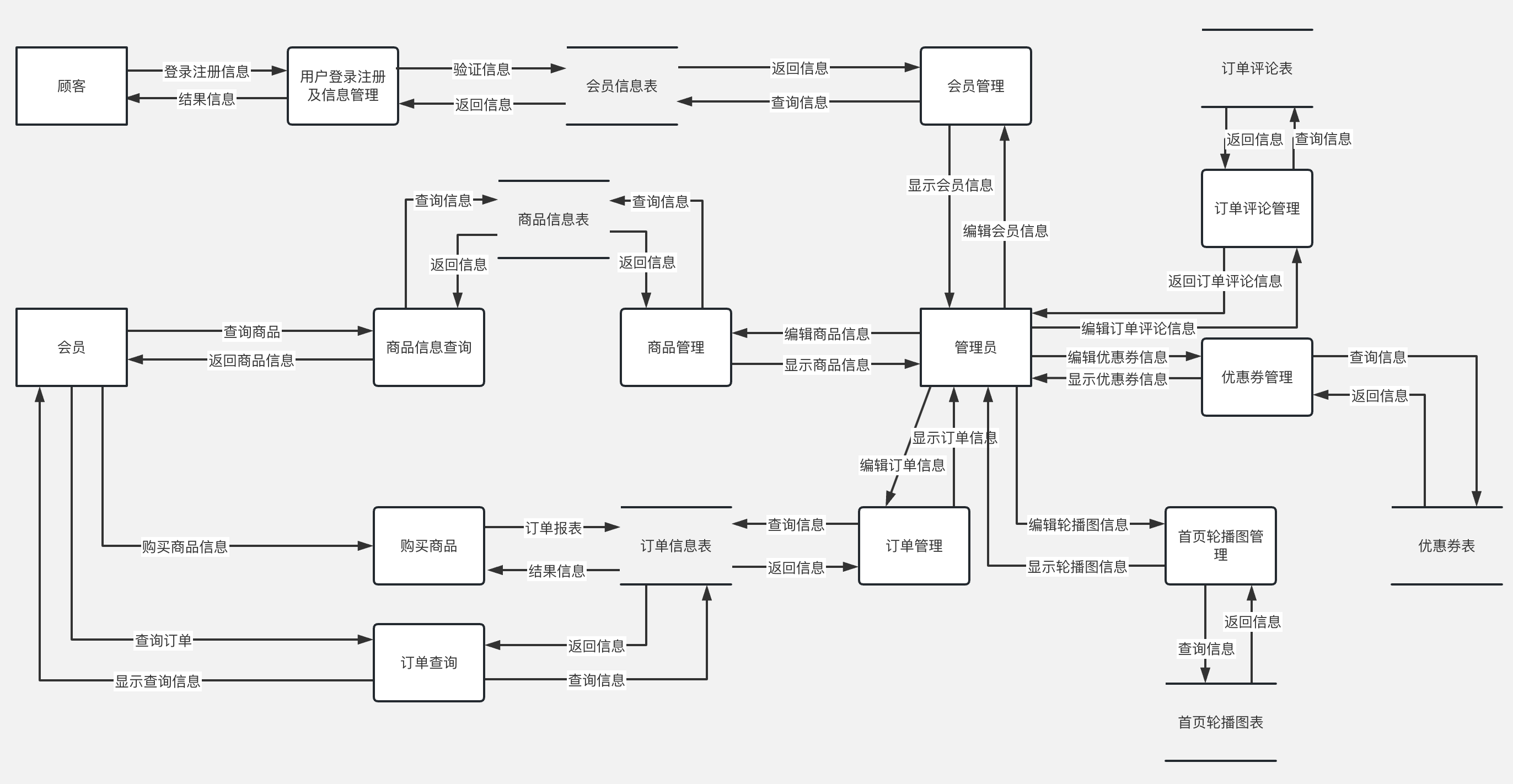
数据流图转化为系统结构图
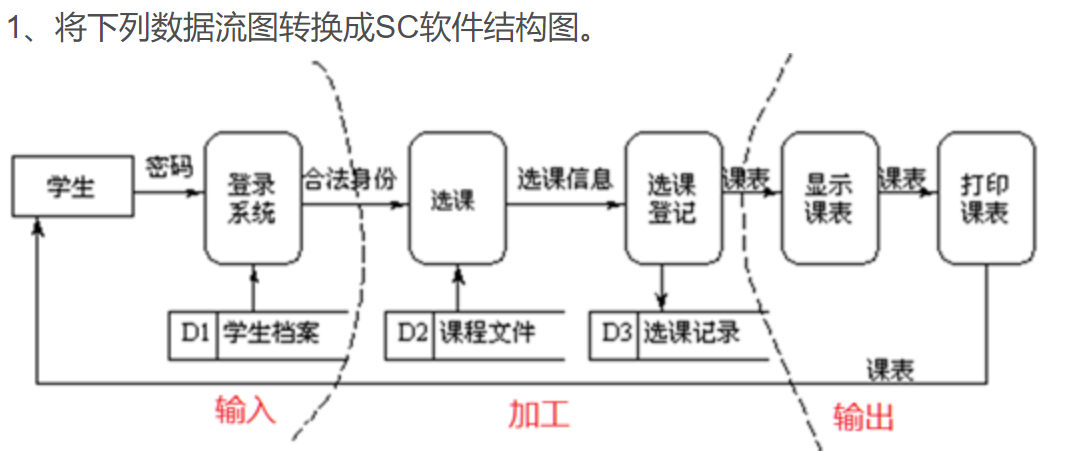
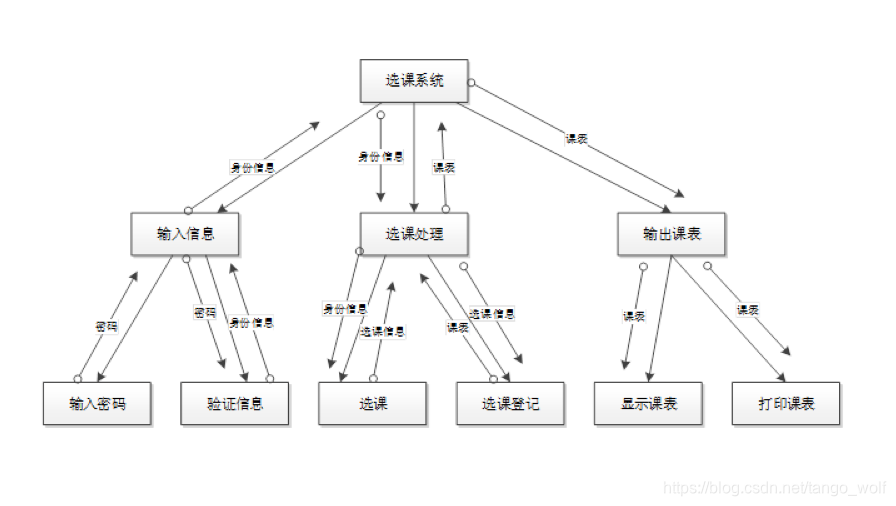
2.将下列数据流图转换成SC软件结构图。(事务流)
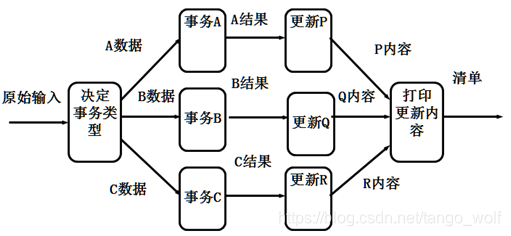
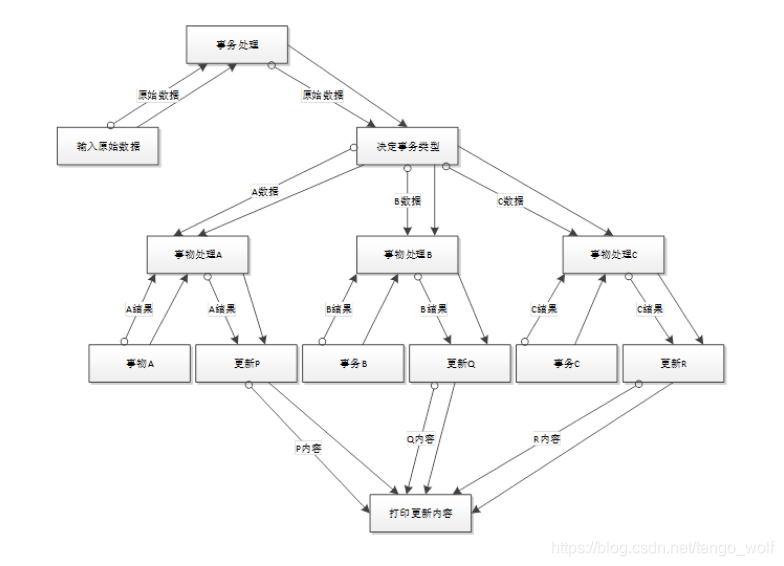
软件体系结构和设计模式
有哪些模式框架风格?特定领域的软件体系结构,分布式系统结构,七个设计模式(百分之百必考,一段文字问你要用什么设计模式以及原因)
- 这章我很多都不会,书上也看不懂,都是gpt帮我生成题目复习的
软件系统中,模式分为(体系结构模式)、(设计模式)、(惯用法)
体系结构风格定义了一个系统家族,即一个体系结构定义一个词汇表和一组约束。词汇表中包含一些构件和连接件类型,而这组约束指出系统是如何将这些构件和连接件组合起来的。体系结构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统。对体系结构风格的研究和实践为大粒度的软件复用提供了可能。
典型的体系结构风格:
数据流风格:管道/过滤器、批处理序列调用/返回风格:主程序/子程序体系结构、面向对象风格、层次结构风格仓库风格:数据库系统、超文本系统、黑板系统













风格是带有一种倾向性模式。同一个问题可以有不同的解决问题的方案或模式
特定领域的软件体系结构
- 类属模型(自下而上):编译器模型
- 参考模型(自上而下):开放式系统互联参考模型
分布式系统结构
- 多处理器体系结构
- 客户/服务器体系结构,两层C/S体系结构
- 瘦客户机
- 胖客户机
- 浏览器/服务器风格(B/S架构)
- 三层C/S体系结构,分为表示层、应用逻辑层、数据层
- 分布式对象体系结构














- 服务器:负责给其他子系统提供服务
- 客户机:向服务器请求服务
- 网络:连接客户机和服务器
优点:
- 客户机构件和服务器构件
分别运行在不同的计算机上,有利于分布式数据的组织和处理。 - 构件之间的位置是相互透明的,客户机程序和服务器程序都不必考虑对方的实际存储位置。
- 客户机侧重数据的显示和分析,服务器则注重数据的管理。
- 构件之间是彼此独立和充分隔离的。
- 将大规模的业务逻辑分布到多个通过网络连接的低成本的计算机,降低了系统的整体开销。
缺点:
- 开发成本较高。
- 在开发C/S结构系统时,大部分工作都都集中在客户机程序的设计上,增加了设计的复杂度。
- 信息内容和形式单一。
- 如果对C/S体系结构的系统进行升级,开发人员需要到现场来更新客户机程序,同时需要对运行环境进行重新配置,增加了维护费用。
- 两层C/S结构采用了单一的服务器,同时以局域网为中心,因此难以扩展到Intranet和Internet。
- 数据安全性不高。
优点:
- 客户端只需要安装浏览器,操作简单。 运用HTTP标准协议和统一客户端软件,能够实现跨平台通信。
- 开发成本比较低,只需要维护Web服务器程序和中心数据库。
缺点:
- 个性化程度比较低,所有客户端程序的功能都是一样的。
- 客户端数据处理能力比较差。
- 在B/S结构的系统中,数据提交一般以页面为单位,动态交互性不强,不利于在线事务处理。
- B/S体系结构的可扩展性比较差,系统安全性难以保障。
- B/S结构的应用系统查询中心数据库,其速度要远低于C/S体系结构。
- 模型-视图-控制器(MVC)架构:
- J2EE体系结构框架:客户层、资源层、表示层、业务层、集成层
- PCMEF与PCBMER框架
- PCMEF框架:表示-控制-中介者-实体-基础
- PCBMER框架:表示-控制-Bean-中介者-实体-资源
设计模式是前辈们经过无数次实践所总结的一些方法(针对特定问题的特定方法)
这些设计模式中的方法都是经过反复使用过的。
设计模式四个要素:模式名称、问题、解决方案、效果
七个设计模式:抽象工厂、单件、外观、适配器、职责链、中介者、观察者。(单抽出外观,中介职责适配观察
单件模式(Singleton)
定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
- 饿汉式:类初始化时,会立即加载该对象,线程天生安全,调用效率高。
- 懒汉式: 类初始化时,不会初始化该对象,真正需要使用的时候才会创建该对象,具备懒加载功能。
应用实例
- 一个班级只有一个班主任。
- Windows 在多进程多线程环境下操作文件时,避免多个进程或线程同时操作一个文件,需要通过唯一实例进行处理。
- 设备管理器设计为单例模式,例如电脑有两台打印机,避免同时打印同一个文件。
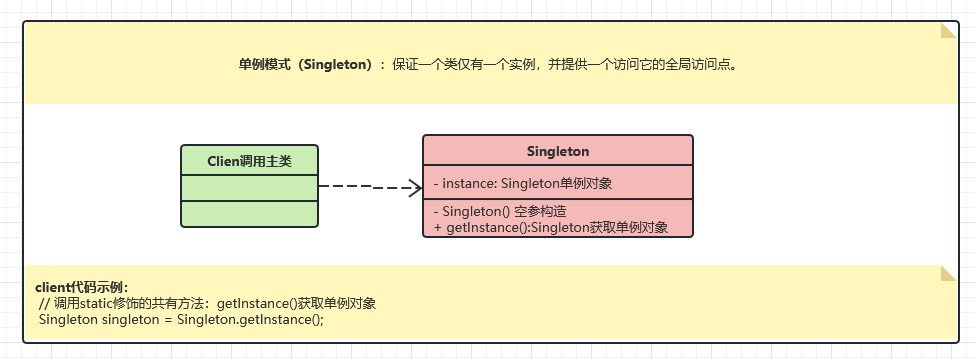
我们将创建一个 SingleObject 类。SingleObject 类有它的私有构造函数和本身的一个静态实例。
SingleObject 类提供了一个静态方法,供外界获取它的静态实例。SingletonPatternDemo 类使用 SingleObject 类来获取 SingleObject 对象。
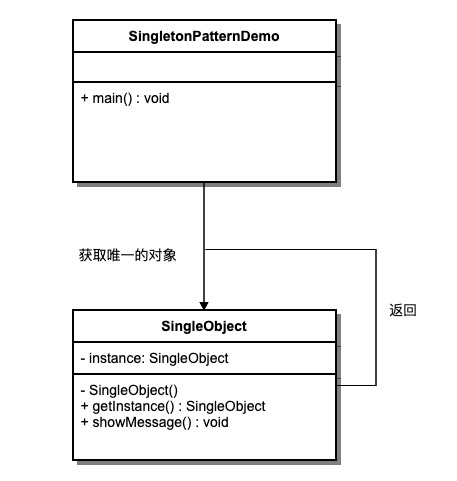
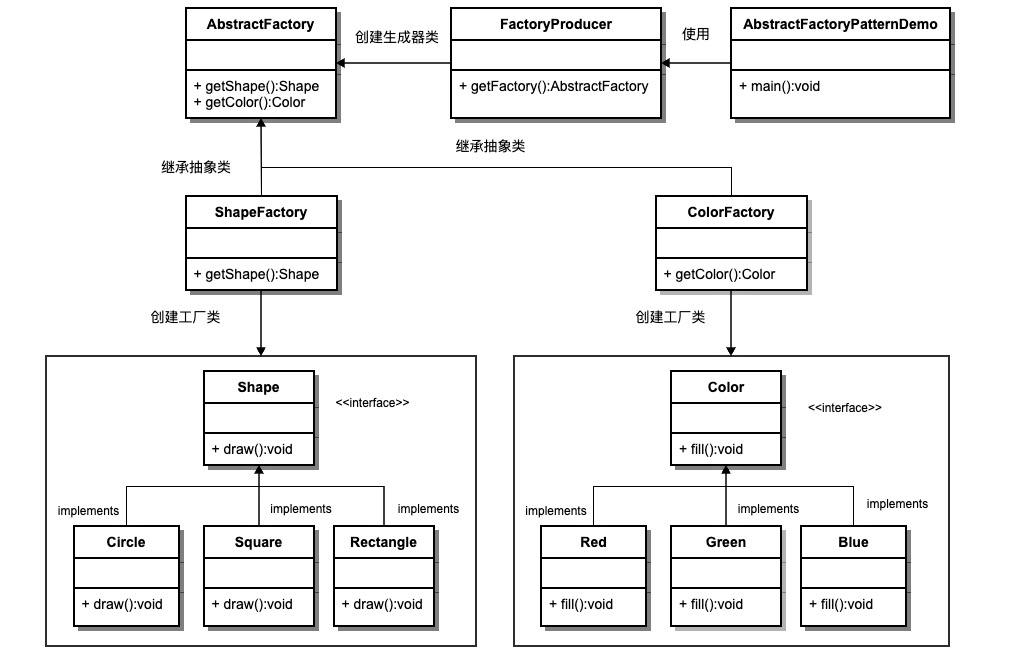
抽象工厂模式(Abstract Factory)
定义:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。用于创建一个产品族的产品。
应用实例
假设有不同类型的衣柜,每个衣柜(具体工厂)只能存放一类衣服(成套的具体产品),如商务装、时尚装等。每套衣服包括具体的上衣和裤子(具体产品)。所有衣柜都是衣柜类(抽象工厂)的具体实现,所有上衣和裤子分别实现上衣接口和裤子接口(抽象产品)。
使用场景
- QQ 换皮肤时,整套皮肤一起更换。
- 创建跨平台应用时,生成不同操作系统的程序。
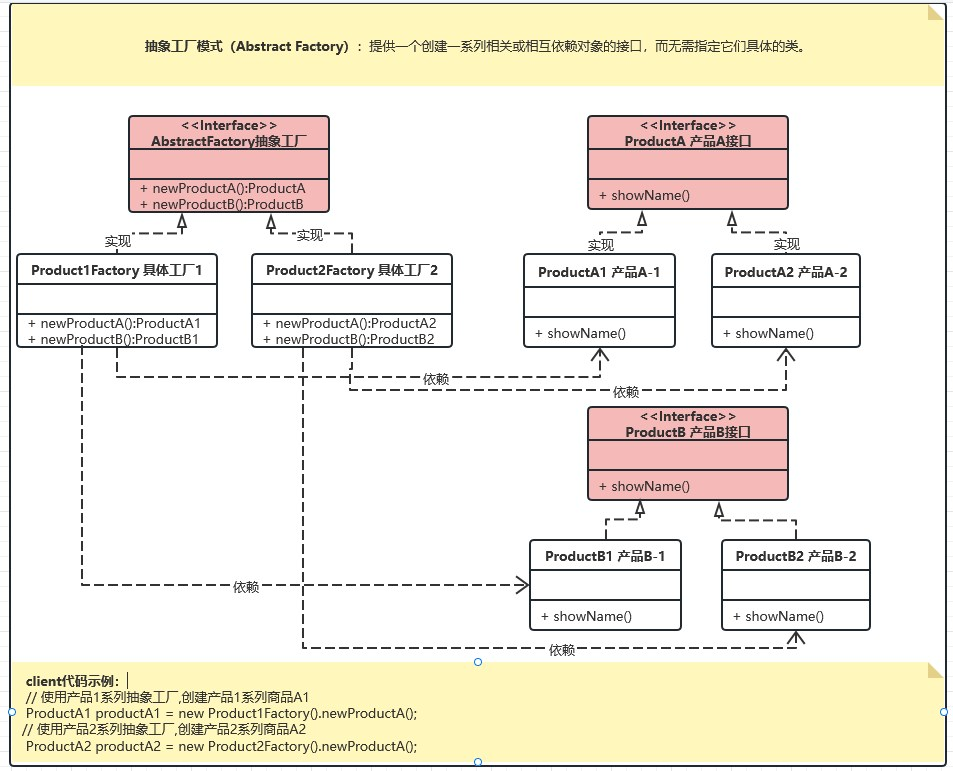
我们将创建 Shape 和 Color 接口和实现这些接口的实体类。下一步是创建抽象工厂类 AbstractFactory。接着定义工厂类 ShapeFactory 和 ColorFactory,这两个工厂类都是扩展了 AbstractFactory。然后创建一个工厂创造器/生成器类 FactoryProducer。
AbstractFactoryPatternDemo 类使用 FactoryProducer 来获取 AbstractFactory 对象。它将向 AbstractFactory 传递形状信息 Shape(CIRCLE / RECTANGLE / SQUARE),以便获取它所需对象的类型。同时它还向 AbstractFactory 传递颜色信息 Color(RED / GREEN / BLUE),以便获取它所需对象的类型。
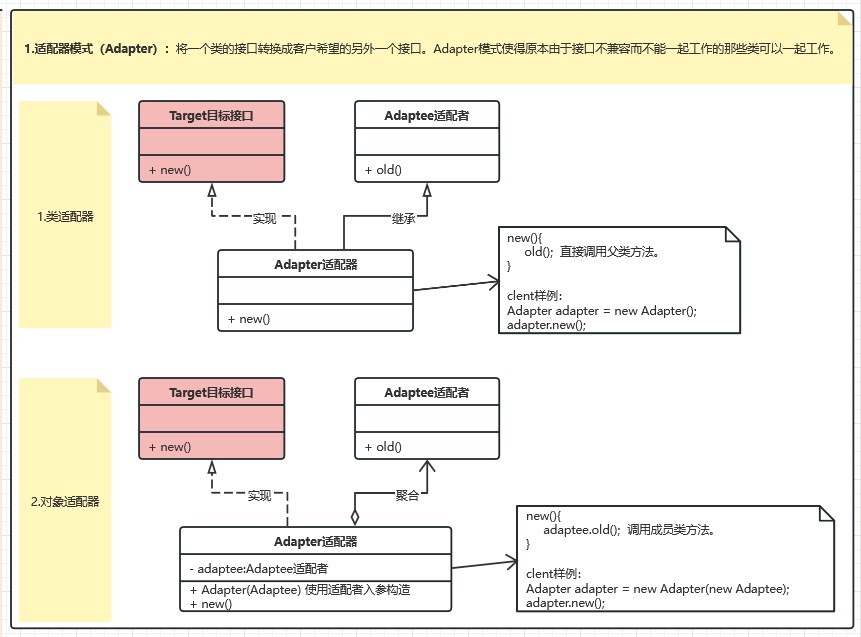
适配器模式(Adapter)
定义:将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。(这个看书上的图更好一些)
使用场景
- 需要使用现有类,但其接口不符合系统需求。
- 希望创建一个可复用的类,与多个不相关的类(包括未来可能引入的类)一起工作,这些类可能没有统一的接口。
- 通过接口转换,将一个类集成到另一个类系中。
应用实例
- 电压适配器:将 110V 电压转换为 220V,以适配不同国家的电器标准。
- 接口转换:例如,将 Java JDK 1.1 的 Enumeration 接口转换为 1.2 的 Iterator 接口。
- 跨平台运行:在Linux上运行Windows程序。
- 数据库连接:Java 中的 JDBC 通过适配器模式与不同类型的数据库进行交互。
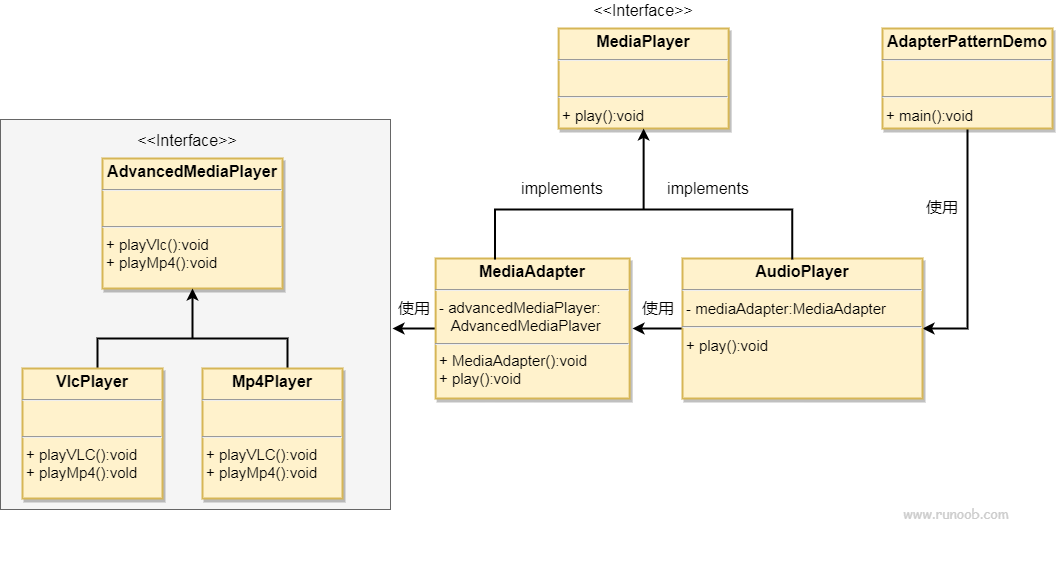
我们有一个 MediaPlayer 接口和一个实现了 MediaPlayer 接口的实体类 AudioPlayer。默认情况下,AudioPlayer 可以播放 mp3 格式的音频文件。
我们还有另一个接口 AdvancedMediaPlayer 和实现了 AdvancedMediaPlayer 接口的实体类。该类可以播放 vlc 和 mp4 格式的文件。
我们想要让 AudioPlayer 播放其他格式的音频文件。为了实现这个功能,我们需要创建一个实现了 MediaPlayer 接口的适配器类 MediaAdapter,并使用 AdvancedMediaPlayer 对象来播放所需的格式。
AudioPlayer 使用适配器类 MediaAdapter 传递所需的音频类型,不需要知道能播放所需格式音频的实际类。AdapterPatternDemo 类使用 AudioPlayer 类来播放各种格式。
类适配器可以通过多继承方式实现不同接口之间的相容和转换
对象适配器通过对象组合的技术实现接口的相容和转换(书上是组合,不是上图的聚合)
外观模式(Facade)
定义:为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
应用实例
- 医院接待:医院的接待人员简化了挂号、门诊、划价、取药等复杂流程。
- Java三层架构:通过外观模式,可以简化对表示层、业务逻辑层和数据访问层的访问
外观模式涉及以下核心角色:
- 外观(Facade):
- 提供一个简化的接口,封装了系统的复杂性。外观模式的客户端通过与外观对象交互,而无需直接与系统的各个组件打交道。
- 子系统(Subsystem):
- 由多个相互关联的类组成,负责系统的具体功能。外观对象通过调用这些子系统来完成客户端的请求。
- 客户端(Client):
- 使用外观对象来与系统交互,而不需要了解系统内部的具体实现。
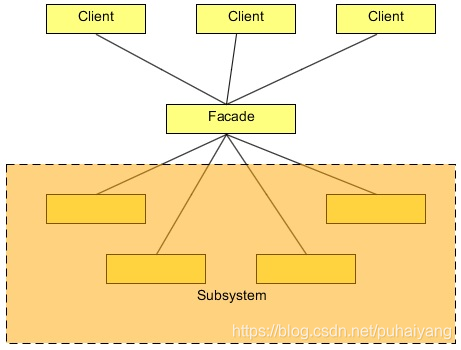
我们将创建一个 Shape 接口和实现了 Shape 接口的实体类。下一步是定义一个外观类 ShapeMaker。
ShapeMaker 类使用实体类来代表用户对这些类的调用。FacadePatternDemo 类使用 ShapeMaker 类来显示结果。
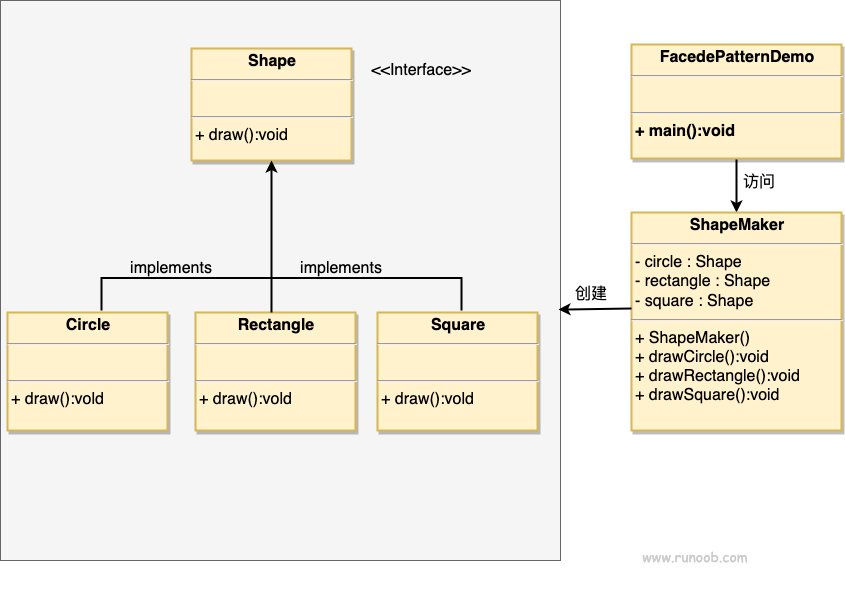
责任链模式(Chain of Responsibility)
定义:解除请求的发送者和接收者之间耦合,而使多个对象都有机会处理这个请求。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它。
应用实例
- 击鼓传花:游戏中的传递行为,直到音乐停止。
- 事件冒泡:在JavaScript中,事件从最具体的元素开始,逐级向上传播。
- Web服务器:如Apache Tomcat处理字符编码,Struts2的拦截器,以及Servlet的Filter。
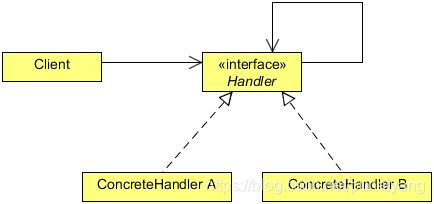
我们创建抽象类 AbstractLogger,带有详细的日志记录级别。然后我们创建三种类型的记录器,都扩展了 AbstractLogger。每个记录器消息的级别是否属于自己的级别,如果是则相应地打印出来,否则将不打印并把消息传给下一个记录器。
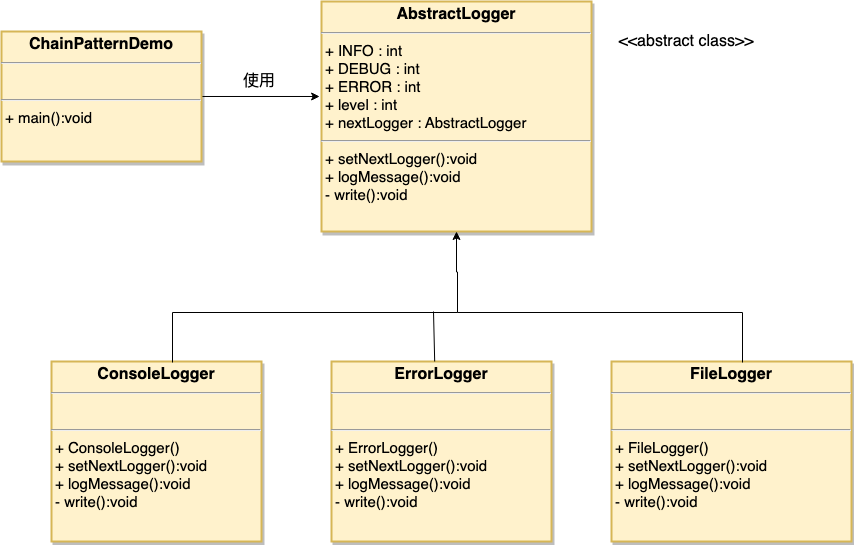
中介者模式(Mediator)
定义:用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
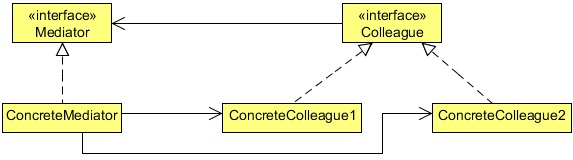
我们通过聊天室实例来演示中介者模式。实例中,多个用户可以向聊天室发送消息,聊天室向所有的用户显示消息。我们将创建两个类 ChatRoom 和 User。User 对象使用 ChatRoom 方法来分享他们的消息。
MediatorPatternDemo,我们的演示类使用 User 对象来显示他们之间的通信。

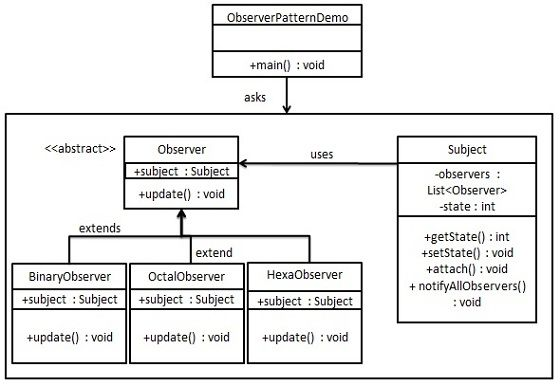
观察者模式(Observer)
定义:定义对象间的一种一对多的依赖关系,以便当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动刷新。
应用实例
- 拍卖系统:拍卖师作为主题,竞价者作为观察者,拍卖价格更新时通知所有竞价者。
- 西游记故事:菩萨洒水作为状态改变,老乌龟作为观察者,观察到这一变化。
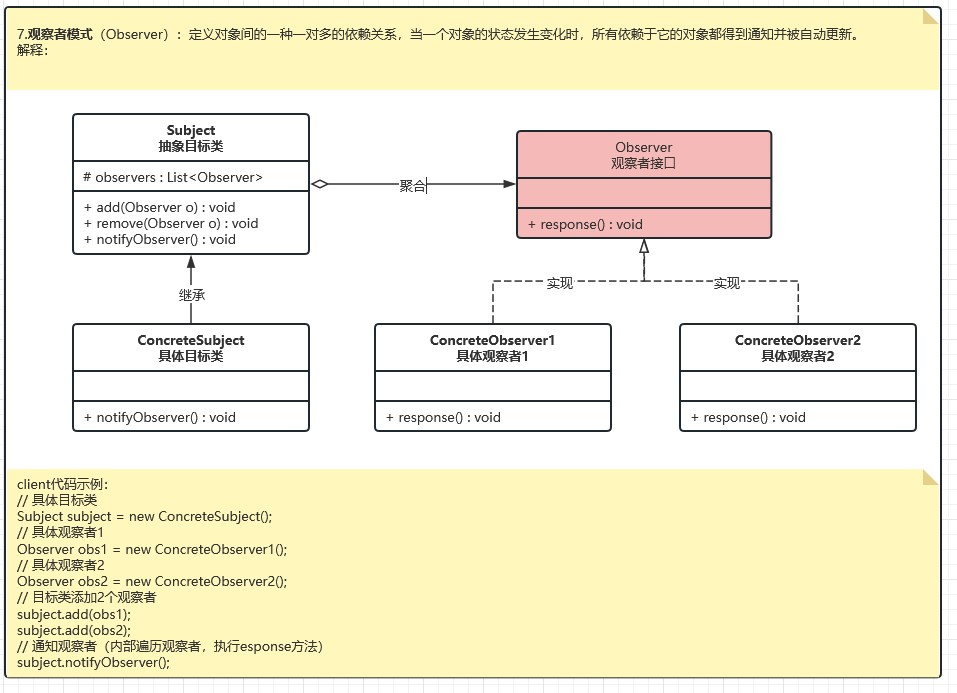
观察者模式使用三个类 Subject、Observer 和 Client。Subject 对象带有绑定观察者到 Client 对象和从 Client 对象解绑观察者的方法。我们创建 Subject 类、Observer 抽象类和扩展了抽象类 Observer 的实体类。
ObserverPatternDemo,我们的演示类使用 Subject 和实体类对象来演示观察者模式。














测试
这部分内容主要是在测试方法上,白盒法测试、黑盒法测试,以及软件测试的四个步骤:单元测试、组装测试、确认测试、系统测试。老师说一定会考黑盒法白盒法,基本路径覆盖考试也考一道题,给代码需要转变为图。对于错误推测法和因果法需要会,需要知道如何画因果图,如何转化为决策表。
1、软件测试是在软件投入生产性运行之前,对软件需求分析、设计规格说明和编码的最终复审,是软件质量控制的关键步骤。 2、软件测试是为了发现错误而执行程序的过程。 3、软件测试是根据软件开发各阶段的规格说明和程序的内部结构而精心设计一批测试用例(即输入数据及其预期的输出结果),并利用这些测试用例去运行程序,以发现程序错误的过程。
- 软件测试是为了发现错误而执行程序的过程
- 一个好的测试用例能够发现至今尚未发现的错误
- 一个成功的测试是发现了至今未发现的错误
- 应当把“尽早地和不断地进行软件测试”作为软件开发者的座右铭。
- 测试用例应由测试
输入数据和与之对应的预期输出结果这两部分组成。 - 程序员应
避免检查自己的程序。 - 在设计测试用例时,应当包括
合理的输入条件和不合理的输入条件。 - 充分注意测试中的群集现象。把Pareto原理应用于软件测试。 Pareto原理:测试发现的错误中的80%很可能是由程序中20%的模块造成的。
- 严格执行测试计划,排除测试的随意性。
- 应当对每一个测试结果作全面检查。
- 妥善保存测试计划、测试用例、出错统计和最终分析报告,为维护提供方便。

软件测试应贯穿于软件定义与开发的整个期间。需求分析、概要设计、详细设计、程序编码等各阶段所得到的文档资料,包括需求规格说明、概要设计规格说明、详细设计规格说明以及源程序,都应成为软件测试的对象。
- 确认(validation),是一系列的活动和过程,其目的是想证实在一个给定的外部环境中软件的逻辑正确性。它包括需求规格说明的确认和程序的确认,而程序的确认又分为静态确认与动态确认。
- 验证(verification),则试图证明在软件生存期各个阶段,以及阶段间的逻辑协调性、完备性和正确性。下图为软件生存期各个重要阶段之间所要保持的正确性。
软件测试分为机器测试和人工测试,机器测试分为黑盒和白盒测试;人工测试分为代码审查、走查、桌前检查
软件开发过程是一个自顶向下、逐步细化的过程,而测试过程则是依相反的顺序安排的自底向上、逐步集成的过程。低一级测试为上一级测试准备条件。 当然不排除两者平行地进行测试。
- 是否有不正确或遗漏了的功能?
- 输入能否正确地接收?
- 能否输出正确的结果?
- 是否有数据结构错误或外部信息(例如数据文件)访问错误?
- 性能上是否能够满足要求?
- 是否有初始化或终止性错误?
软件测试的目的只是发现错误,原因是软件测试可以有两个目标,一个是预防错误,一个是发现错误。由于软件开发是人的创造性劳动,人的活动不可能完美无缺,错误可能发生在任何一个阶段,因此预防错误这个目标几乎是不可实现的,所以软件测试的目标定义为只是发现错误
软件测试方法一般分动态测试和静态测试两部分组成


软件测试的目的是尽可能多发现软件中存在的错误,将测试结果作为纠错的依据
测试的关键问题是如何选择测试用例
软件测试的目的是为了发现程序中的错误
逻辑覆盖测试中,测试覆盖最弱的是语句覆盖
白盒测试
- 白盒穷举测试
- 逻辑覆盖
语句覆盖: 语句覆盖要求把每一个执行语句(矩形框)执行一次
L1(a→c→e),满足语句覆盖的测试用例为(2,0,4)
语句覆盖是最弱的逻辑覆盖标准,如果错吧 A > 1 && B == 0 错写成A > 1 B == 0测试用例依然能通过
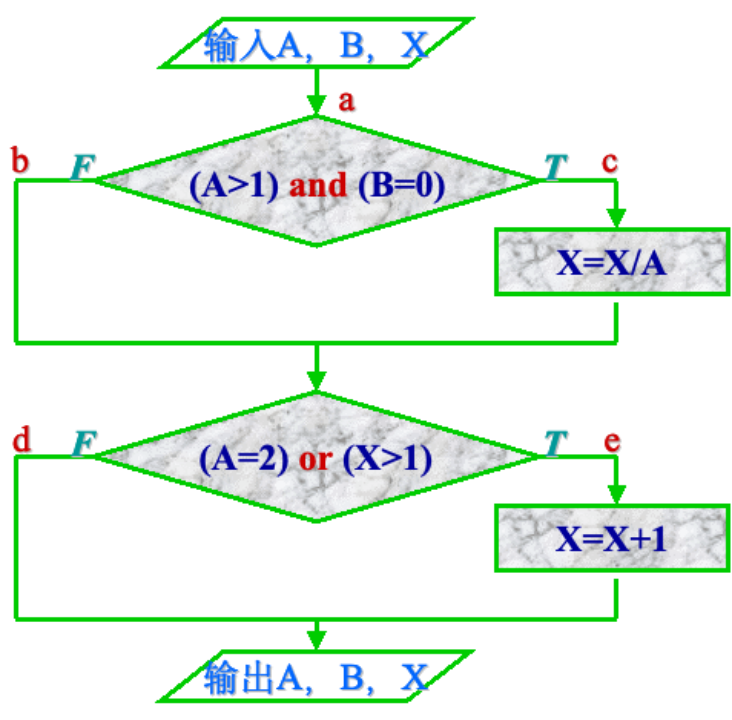
判定覆盖: 判定覆盖就是得经历每一个逻辑判断的真和假
这里就是需要经历TF+FT或者TT+FF,只需要真和假都有出现就行,不需要排列组合考虑所有情况
所以路径为ace和abd,测试用例设计为(2,0,4)和(1,1,1)
但是还是不一定查出来判断条件的错误,如果不小心把x>1错写成x<1,上面两组依旧能通过
条件覆盖
判定覆盖是把每一个分支取一次
而条件覆盖是将每一个条件的可能取值执行一次
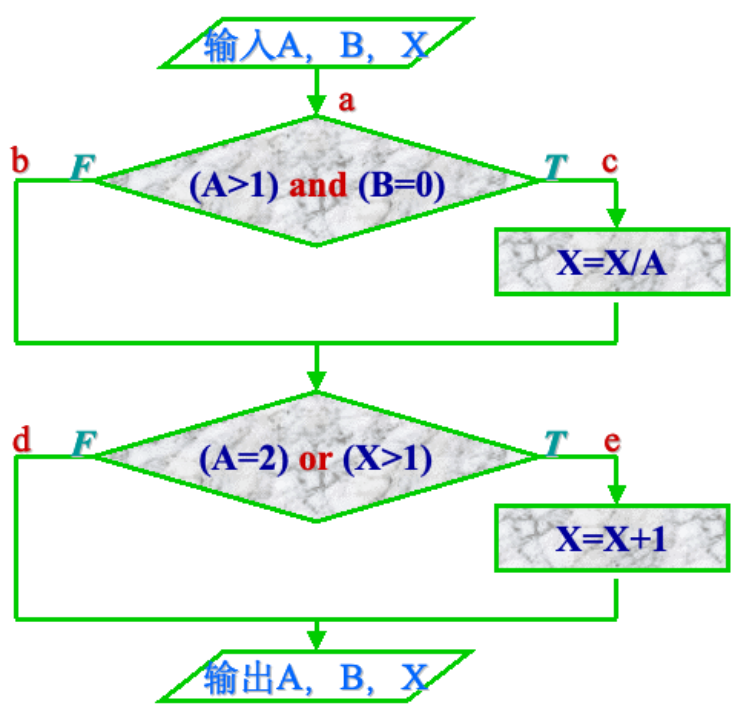


这组用例不仅条件覆盖而且还是判定覆盖

这组用例只满足条件覆盖但是没满足判定覆盖
同样不需要考虑排列组合,只需要每个条件都出现就行
判定-条件覆盖
判定—条件覆盖就是设计足够的测试用例,使得判定中每个条件的所有可能取值都至少执行一次,每个判断的所有可能判断结果至少执行一次
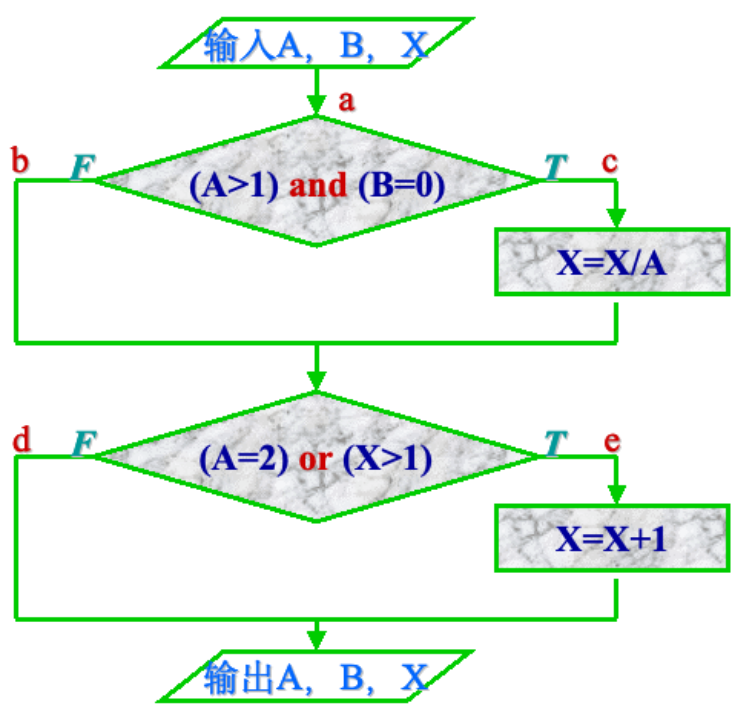

判定-条件覆盖也有缺陷。从表面上看,它测试了所有条件的取值,但事实并非如此。因为往往某些条件掩盖了另一些条件。
对于表达式(A>1) and (B=0)来说,若(A>1)的测试结果为假,往往就不再测试(B=0)的取值了。
条件组合覆盖
条件组合覆盖要求的是每个判断的所有可能条件取值组合至少执行一次

条件组合覆盖是一种相当强的覆盖准则,可以有效地检查各种可能的条件取值的组合是否正确。
它不但可覆盖所有条件的可能取值的组合,还可覆盖所有判断的可取分支,但可能有的路径会遗漏掉。
因此,满足条件组合覆盖的测试还不完全。
路径覆盖
路径测试是设计足够的测试用例,覆盖程序中所有可能的路径。

- 基本路径覆盖


循环结构分析
- 简单循环
- 零次循环:从循环入口到出口
- 一次循环:检查循环初始值
- 二次循环:检查多次循环
- m次循环:检查在多次循环
- 最大数循环:比最大次数多一次、少一次的循环。
- 嵌套循环:对最内层循环做简单循环的全部测试; 逐步外推,对其外面一层做测试; 反复进行;对全部各层循环同时取最小循环次数或者同时取最大循环测试
- 连锁循环: 如果各个循环互相独立,则可以用与简单循环相同的方法进行测试。但如果几个循环不是互相独立的,则需要使用测试嵌套循环的办法来处理。
- 非结构循环: 这一类循环应该使用结构化程序设计方法重新设计测试用例。


使用程序设计的控制结构导出测试用例的测试方法是白盒测试
白盒测试是通过分析程序的内部逻辑来设计测试用例的方法
白盒法必须考虑程序的内部结构和处理过程,以检查处理过程的细节为基础,对程序中尽可能多的逻辑路径进行测试
白盒测试是结构测试,被测对象是源程序,以程序的内部逻辑为基础设计测试用例
测试用例由输入数据和预期的输出数据两部分组成
逻辑覆盖是对程序内部有判定存在的逻辑结构设计测试用例,根据程序内部的逻辑覆盖程度和发现错误能力由强到弱的顺序,可以分为语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖、路径覆盖
每一个分支执行一次称之为判定覆盖
实际的逻辑覆盖测试中,一般以条件组合覆盖为主设计测试用例,然后补充部分用例,以达到路径覆盖测试标准
循环覆盖是对程序内部有循环存在的逻辑结构设计测试用例,通过限制循环次数来测试
基本路径覆盖是对程序内部控制流程图基础上,通过分析控制构造环路复杂性,导出基本路径集合,从而测试用例
动态测试通过运行程序发现错误,根据测试用例的设计方法不同,动态测试又分为黑盒测试和白盒测试
黑盒测试和白盒测试都是动态测试
黑盒法只在软件的接口处进行测试,依据需求规格说明书,检查软件是否满足功能要求
黑盒测试
黑盒测试是功能测试,因此设计测试用例时,需要研究需求规格说明书和概要设计说明书中有关程序功能或输入、输出之间的关系等信息,从而与测试后的结果进行分析比较。
- 等价类划分
- 如果输入数据规定了取值范围或值的个数,则可以确定一个有效等价类和两个无效等价类。
- 如果规格说明规定了数据值的集合,或者是规定了“必须如何”的条件,这时可确定一个有效等价类和 一 个无效等价类。
- 如果规格说明中规定的是一个条件数据,则可确定一个有效等价类和一个无效等价类。
- 边界值分析
- 如果输入数据规定了值的范围,则取刚好达到这个范围边界的值,以及刚好超过这个范围边界的测试输入数据
- 如果输入数据规定了值的个数,则用最大个数、最小个数、比最大个数多1、比最小个数少1的数作为测试数据。例如,一个输入文件有1~255个记录,设计测试用例时则可以分别设计有1个记录、255个记录以及0个记录和256个记录的输入文件。
- 错误推断法: 凭经验或直觉推测可能的错误,列出程序中可能有的错误和容易发生错误的特殊情况,选择测试用例。
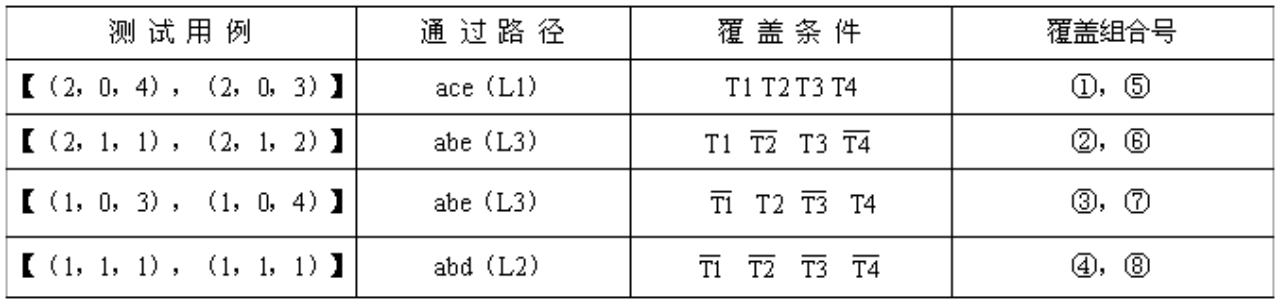
- 因果图法

因果图能够有效检测输入条件的各种组合可能引起的错误
因果图的基本原理是通过画因果图,把自然语言描述的功能说明转化为判定表,最后为每一列设计一个测试用例
黑盒测试在设计测试用例时,主要需要研究需求规划说明与概要设计说明
在用户界面层次上对软件进行测试属于黑盒测试
使用边界值分析方法设计测试用例时一般与等价类划分结合起来。但它不是从一个等价类中任选一个例子作为代表,而是将测试边界情况作为重点目标,选取正好等于、刚刚大于或刚刚小于边界值的测试数据。
黑盒测试是根据程序的功能来设计测试用例的
黑盒测试是功能测试,利用黑盒技术设计测试用例有四种方法:等价类划分、边界值分析、错误推测、因果图
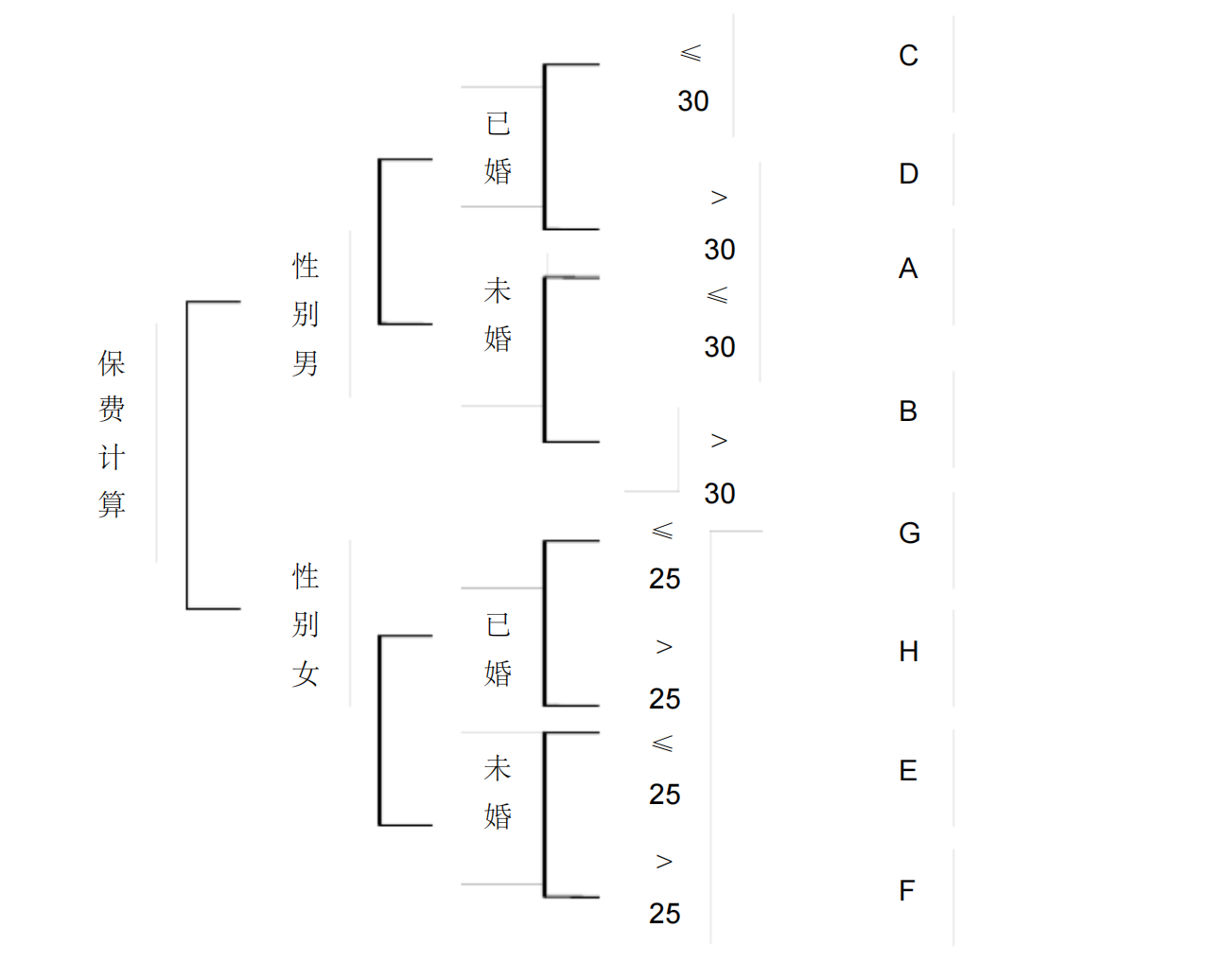
等价类划分法设计一个测试用例,使其覆盖尽可能多尚未被覆盖的合理等价类
等价类划分法设计测试用例时,如果被测程序的某个输入条件规定了取值范围,则可确定一个合理等价类和两个不合理等价类

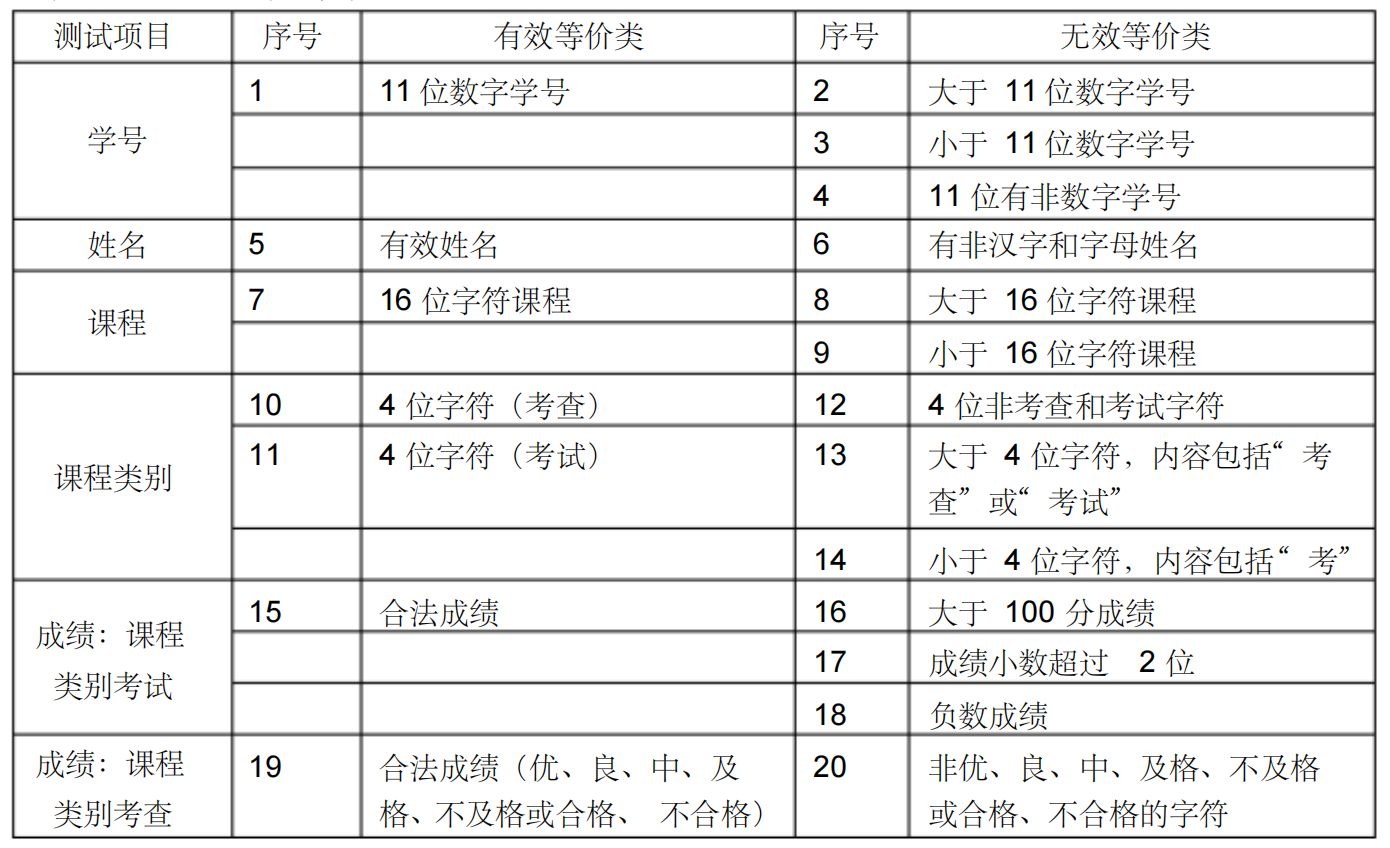
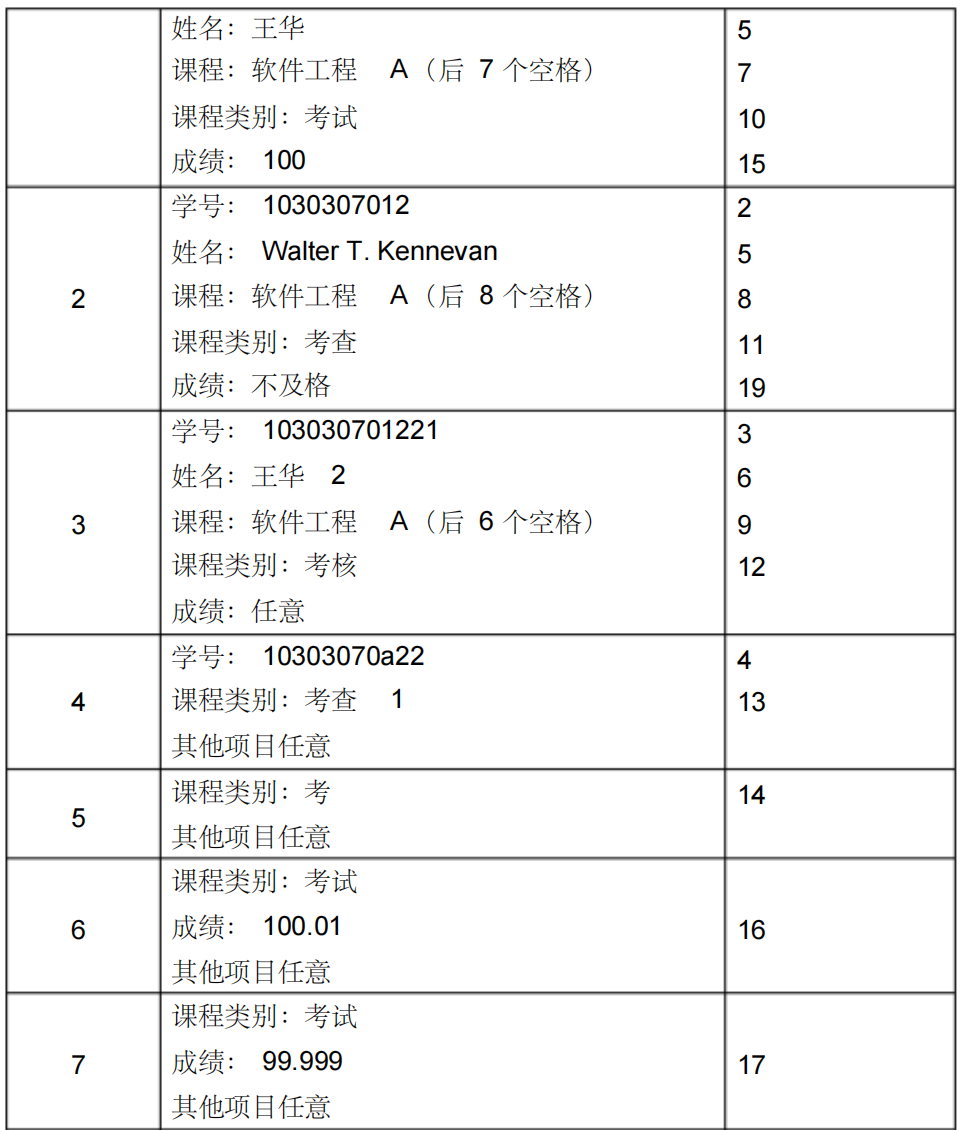

| 条件 | year<20 | y | y | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 20≤year<50 | y | y | y | y | ||||||
| year≥50 | y | y | y | |||||||
| 性别为男 | y | y | ||||||||
| 性别为女 | y | y | ||||||||
| 小学 | y | y | y | y | ||||||
| 中学 | y | y | y | y | ||||||
| 大专 | y | |||||||||
| 动作 | 脱产学习 | y | ||||||||
| 电工 | y | |||||||||
| 钳工 | y | y | ||||||||
| 车工 | y | y | ||||||||
| 技术员 | y | |||||||||
| 材科员 | y | y |

| 输入数据 | 有效等价类 | 无效等价类 | | — | — | — | | 用户名字符个数 | 长度在6到16之间(1) | 长度小于6(2) 长度大于16(3) | | 用户名字符类型 | 包含英文大小写、数字和下划线的组合,不全为数字或下划线(4) | 全是数字(5) 出现中文(6) 全是下划线(7) | | 密码长度 | 长度不少于8位(8) | 长度小于8(9) | | 密码字符类型 | 包含大小写英文字母、数字、特殊字符的组合(10) | 只包含大写英文字母(11) 只包含小写英文字母(12) 只包含数字(13) 只包含特殊字字符(14)
只包含大小写英文字母(15) 只包含大写英文字母+数字(16) 只包含小写引文字母+数字(17) 只包含大写英文字母+特殊字符(18) 只包含小写英文字母+特殊字符(19) 只包含数字+特殊字符(20)
只包含大小写英文字母+数字(21) 只包含大小写英文字母+特殊字符(22) 只包含大写英文字母+数字+特殊字符(23) 只包含小写英文字母+数字+特殊字符(24) |
| 输入数据 | 有效等价类 | 无效等价类 | | — | — | — | | 输入三个整数 | 输入三个数(1) | 只给一个数(2) 只给两个数(3) 给三个以上数(4) | | | 整数(5) | 1个整数+2个非整数(6) 2个整数+1个非整数(7) 3个非整数(8) | | | 非负数(9) | 一边为0(10) 两边为0(11) 三边为0(12) | | | 正数(13) | 一边小于0(14) 两边小于0(15) 三边小于0(16) | | 能否构成三角形三条边 | a+b>c(17) | a+b≤c(18) | | | a+c>b(19) | a+c≤b(20) | | | c+b>a(21) | c+b≤a(22) | | 是否等腰三角形 | a=b(23) | a≠b(24) | | | a=c(25) | a≠c(26) | | | b=c(27) | b≠c(28) | | 是否等边三角形 | a=b=c(29) | a≠b(30) | | | | b≠c(31) | | | | a≠c(32) |





软件测试策略
- 静态分析测试
- 生成各种表 我表示无话可说
- 静态错误分析 我想冷静分析一下错误
- 人工测试方法
- 桌前检查(自己检查) 自己桌子自己做主
- 代码评审(评审小组检查) 让别人动一动屁股,我来讲,你们查
- 走查 开会,人肉计算机


静态测试测用人工检测和计算机辅助分析检测
被测试程序不在机器上运行,而是采用人工检测和计算机辅助分析检测的手段称为静态测试
计算机辅助静态分析利用静态分析工具对测试程序进行特性分析
软件测试的手段有多种,通过人工来评审文档或程序,借以发现其中错误,该手段是静态测试
- 单元测试:主要采用白盒测试方法设计测试用例,辅之以黑盒测试的测试用例。是针对软件设计的最小单位—程序模块,进行正确性检验的测试工作。其目的在于发现各模块内部可能存在的各种差错。单元测试需要从程序的内部结构出发设计测试用例。多个模块可以平行地独立进行单元测试。
- 模块接口测试
- 局部数据测试
- 路径测试
- 错误处理测试
- 边界测试
- 组装测试(集成测试/联合测试):在单元测试的基础上,需要将所有模块按照设计要求组装成为系统
- 一次性组装方式(整体拼装)
增值式组装方式(渐增式拼装) 1. 自顶向下增值方式(这种组装方式是将模块按系统程序结构,沿控制层次自顶向下进行组装)
① 以主模块为被测模块兼驱动模块,所有直属于主模块的下属模块全部用桩模块代替,对主模块进行测试
② 采用深度优先或宽度优先的策略,逐步采用实际模块替换已用过的桩模块,再用新的桩模块代替它们的直接下属模块,与已测试的模块或子系统组织成新的子系统
③ 进行回归测试
④ 判断是否全部组装
2. 自底向上增值方式(这种组装方式是从程序模块结构的最底层的模块开始组装和测试,因为模块是自底向上进行组装,对于一个给定层次的模块,它的子模块(包括子模块的所有下属模块)已经组装并测试完成,所以不再需要桩模块)
① 由驱动模块控制最底层模块的并行测试;也可以把最底层模块组合成实现某一特定软件功能的簇,由驱动模块控制它进行测试。
② 用实际模块代替驱动模块,与它已测试的直属子模块组装成为子系统。
③ 为子系统配备驱动模块,进行新的测试。
④ 判断是否已组装到达主模块。若是则结束测试,否则执行②。
3. 混合增值方式 3. 确认测试(有效性测试):任务是验证软件的有效性,即验证软件的功能和性能及其他特性是否与用户的要求一致。确认测试一般是在模拟环境中运用黑盒测试方法,由专门测试人员和用户参加的测试。 1. 进行有效性测试 2. 软件配置复查 3. α测试和β测试(用户参与)
1. **α测试**
α测试是由**一个**用户在**开发环境下**进行的测试,也可以是公司内部的用户在模拟实际操作环境下进行的测试;
**目的**:是评价软件产品FLURPS(即功能、局域化、可使用性、可靠性、性能和支持)。
**注意!α测试不能由程序员或测试员完成。**
2. **β测试**
测试是由软件的多个用户在**一个或多个**用户的**实际使用环境**下进行的测试。这些用户是与公司签定了支持产品预发行合同的外部客户。
只有当α测试达到一定的可靠程度时,才能开始β测试。
- 验收测试
- 确认测试的结果
- 系统测试:系统测试的目的在于通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方。系统测试的测试用例应根据系统的需求分析说明书设计,并在实际使用环境下运行。
PS
自顶向下增值方式的缺点是需要建立桩模块。
自底向上增值方式的缺点是“程序一直未能作为一个实体存在,直到最后一个模块加上去后才形成一个实体”。也就是说,在自底向上组装和测试的过程中,对主要的控制直到最后才接触到。








- 驱动模块:被测模块的主程序。它接受测试数据,把这些数据传输给被测模块,最后输出测试结果
- 桩模块:存根模块,用以代替被测模块调用的子模块。桩模块可以做少量的数据操作,不需要把子模块的所有功能都带进来,但不允许什么事情都不做
被测模块、驱动模块、桩模块共同构成了一个“测试环境”






α测试时由一个用户在开发者的场所来进行的,测试的目的是寻找粗欧文的原因并修改
单元测试时,需要为被测模块设计驱动模块和桩模块
集成测试的方法有两种:非渐进式测试和渐进式测试
渐进式测试有两种不同的组装模块的方法:自顶向下结合和自底向上结合
自顶向下渐进测试不需要编写桩模块,只需要编写驱动模块,其步骤是从顶模块开始,沿着被测试程序的软件结构图的控制路径逐步向下测试,它有两种组合策略:深度优先策略和宽度有限策略
自底向上渐进测试不需要编写驱动模块,只需要编写桩模块
单元测试时,需要为被测模块设计驱动模块和桩模块
针对软件需求分析所进行的软件测试是确认测试
单元测试主要针对模块的五个基本特征进行测试:模块接口、局部数据结构、重要的执行路径、错误处理、边界条件
单元测试是发现编码错误,集成测试是发现模块的接口错误,确认测试是为了发现功能错误,系统测试是为了发现性能、质量不合要求的错误
确认测试指检查程序的功能和性能是否与需求规格说明书中的指标相符合,又称为有效性测试
在单元测试期间,通常考虑模块的局部数据结构,通常考虑模块的重要的执行路径
单元测试阶段主要涉及编码和详细设计文档
维护
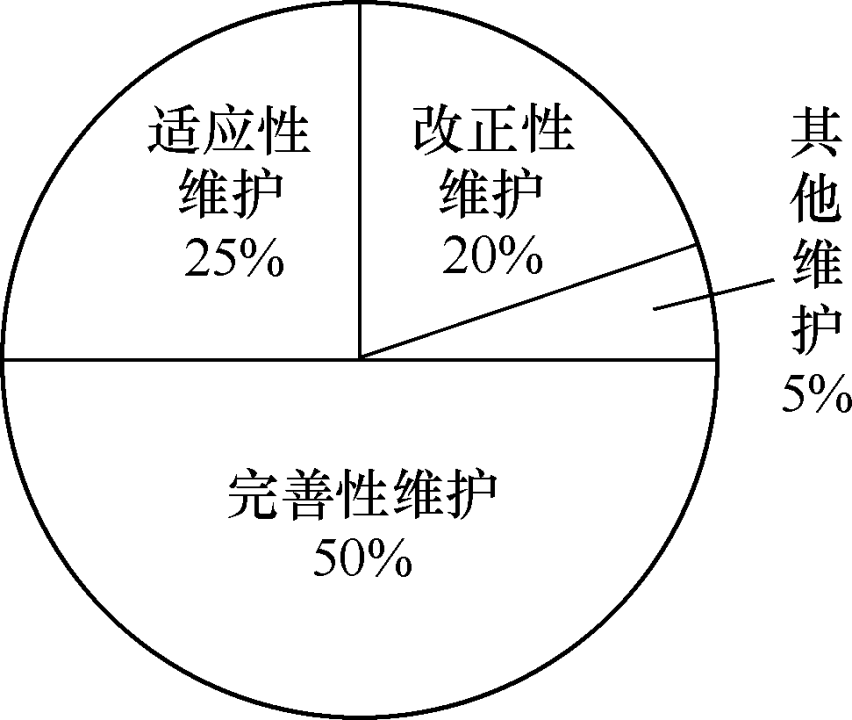
软件维护概念不需要背,但是需要知道软件维护的四个类型:改正性维护、适应性维护、完善性维护、预防性维护(需要了解这几个类型之间的区别)
因计算机硬件和软件环境的变化而做出的修改软件的过程称为完善性维护
为了提高软件的可维护性或可靠性而对软件进行修改称为预防性维护
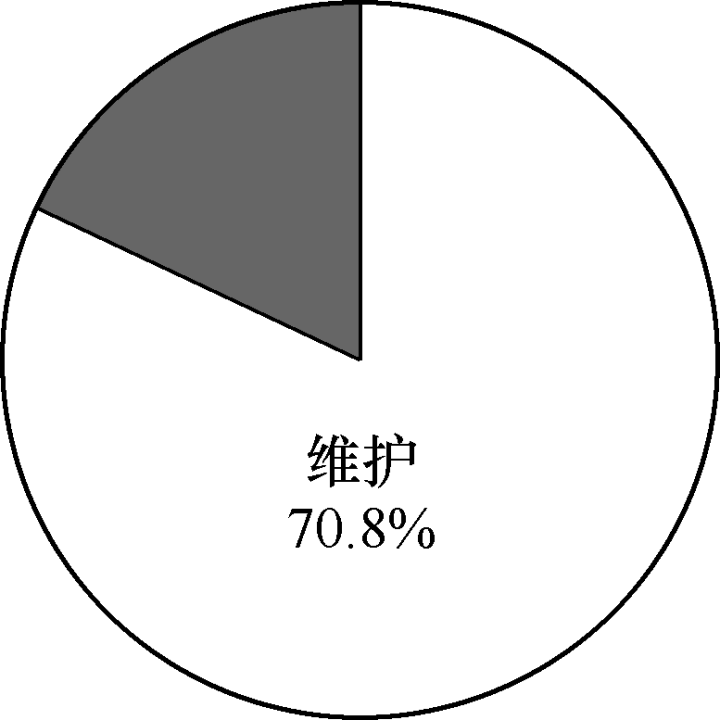
软件维护占软件生命周期的70%,完善性维护占软件维护的50%
软件维护的策略有(改正性维护)、(适应性维护)、(完善性维护)
需要记住软件维护带来了哪些新的问题以及提高软件维护性的方法
软件维护的三种副作用为(修改代码副作用)、(数据副作用)、(文档副作用)
可维护性的特性中,效率和可修改性是相互矛盾的
结构化维护和非结构化维护的主要区别是在于文档的完整性
采用手工方法开发软件只有程序而没有文档,维护困难,这是一种非结构化维护
面向维护的技术涉及软件开发的所有阶段
软件生命周期中花费的费用最多的阶段是软件维护
在整个软件维护阶段所花费的全部工作中,完善性维护所占的比例最大
软件维护是指在软件交付之后,为了改正错误和满足新的需要而修改软件的过程。
软件维护通常包括四个方面:
①改正性维护——修补系统缺陷的维护,日常维护的主要工作。
②适应性维护——使软件适应不同的操作系统(软硬件环境)。
③完善性维护——增加或修改系统功能的维护。
④预防性维护——为预防系统后期可能的实效而做的维护工作。
完善性维护的工作量占软件维护的70%







在软件维护中,影响维护工作量的因素主要有以下6种:
- 系统规模。 💩山多大啊
- 程序设计语言。 学过几个语言啊
- 系统年龄大小。 我这可是八二年的💩山了啊
- 数据库技术的应用水平。 学过王老师的数据库没?就来学软件工程啦🥵
- 所采用的软件开发技术及软件开发工程化的程度。 技术行不行啊你
- 其他:如应用的类型、数学模型、任务的难度、IF嵌套深度、索引或下标数等,对维护工作量都有影响。 好的👌,你说其他我就写其他
- 分析和理解程序
- 实施修改
- 重新验证程序
- 静态确认
- 确认测试:先对修改部分进行测试,然后隔离修改部分,测试程序的未修改部分,最后再把它们集成起来进行测试。这种测试称为回归测试。
- 维护后的验收
程序修改的副作用是指因修改软件而造成的错误或其他不希望发生的情况,有以下3种副作用:
- 修改
代码的副作用 - 修改
数据的副作用 - 修改
文档的副作用
如何控制修改副作用?(4个点)
- 按模块把
修改分组; 分组一个个砍头🔪 自顶向下地安排被修改模块的顺序; 从上到下砍- 每次修改
一个模块; 一次砍一个脑袋 - 对于每个修改了的模块,在安排修改下一个模块之前,要
确定这个修改的副作用,可以使用交叉引用表、存储映象表、执行流程跟踪等。 砍完之后确认真砍死了么,记个表确认一下




软件维护性是指当对软件实施各种类型的维护而进行修改时,软件产品可被修改的能力
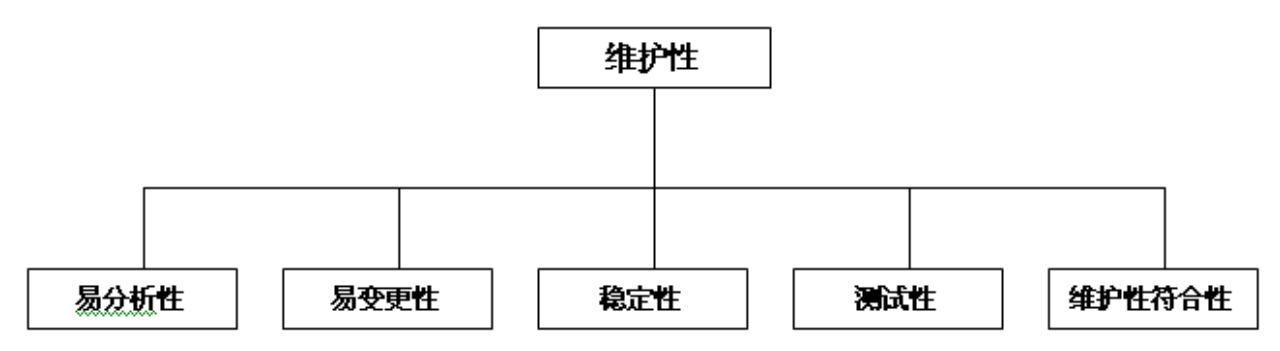
提高软件维护性的方法(3个方法)
- 使用提高软件质量的技术和工具 能不能增点牛逼技术
- 模块化 我模块化!牛逼吧🐮
- 结构化程序设计 我结构化,真棒👍
- 使用结构化程序的设计概念,提高现有系统的可维护性 我给你整个设计概念,我真厉害
- 实施开发阶段产品的维护性审查 求求你边检查边开发吧
- 检查点审查 🧐点点点点
- 验收审查 领导别整验收标准了,已经要四了 1. 需求和规范标准 2. 设计标准 3. 源代码标准 4. 文档标准
- 周期性维护审查 时不时看一看
- 对软件包进行审查 包赢的
- 改进文档 改进你🐎的文档
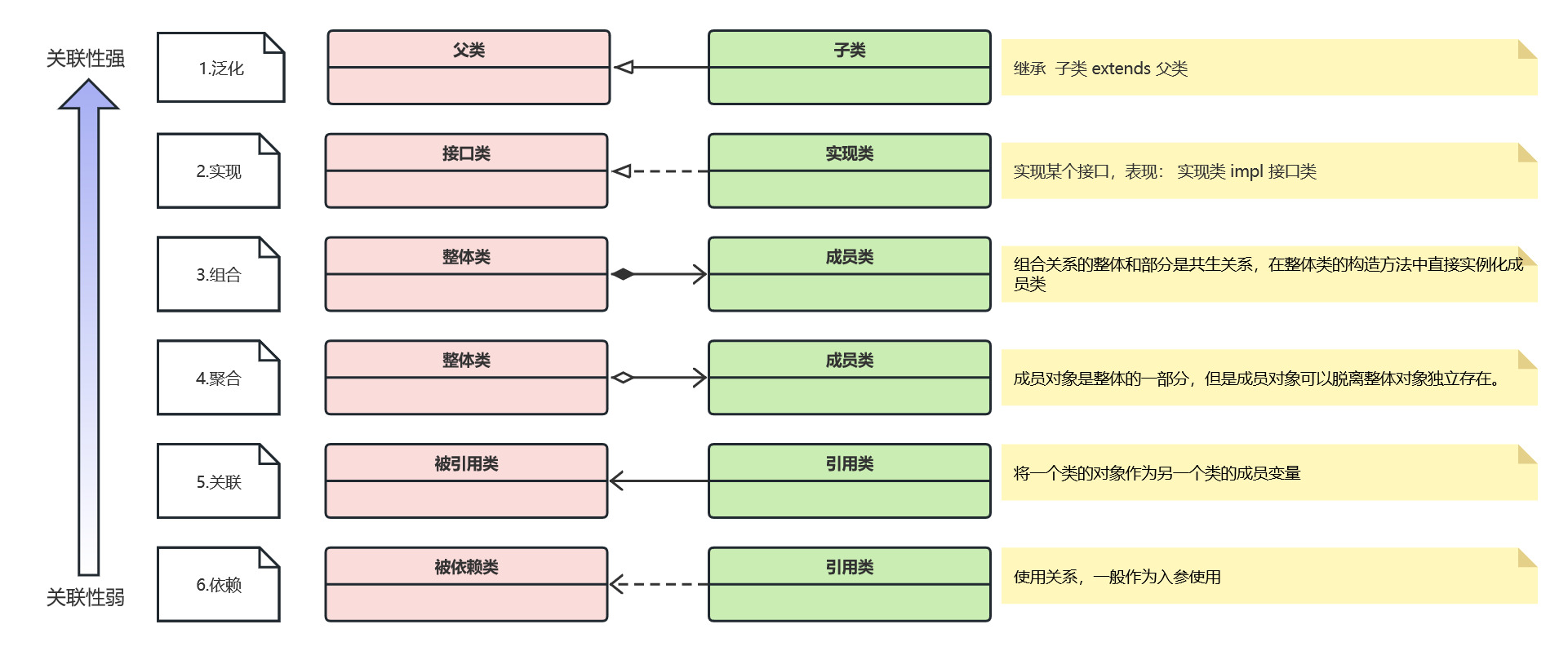
- 1.泛化:指的是继承关系,表达一般和特殊。符号:空心三角箭头的实线,箭头指向父类。(注:UML中只有泛化,继承是开发角度的描述。)
- 2.实现:指的是类与接口的关系,表达类实现了接口的特征行为。符号:带三角箭头的虚线,箭头指向接口。
- 3.组合:指的是整体与部分的关系, 但部分不能离开整体而单独存在。符号:带实心菱形的实线,菱形指向整体。
- 4.聚合:指的是整体和部分关系,且部分可以离开整体而单独存在。符号:空心菱形的实心线,菱形指向整体。
- 5.关联:指的是类和类的关系,表达一个类知道另一个类的属性和方法。符号:带普通箭头(或实心三角形箭头)的实心线。
- 6.依赖:指的是使用的关系, 即一个类的实现需要另一个类的协助, 所以要尽量不使用双向的互相依赖。符号:带箭头的虚线,指向被依赖的类。




