
分布式训练
Published:
遗憾吗?无需为往事遗憾。遗憾的是此刻
今天,是所有无以数计的日夜,我失去的、唯有痛苦的日夜,既无馈赠亦无震撼的日夜。
分布式训练
这部分内容其实我接触的挺早了, 但是现在才开始做整理
我最开始接触到分布式是Lightening架构, 当时最开始使用单机多卡的环境来训练就是用Lightening写的, 因为现在大家用Lightening的还是少, 所以后来转到自己写的DDP上
分布式训练的背景
随着深度学习模型规模的迅速增大,模型参数和输入数据集的体积使得单一 GPU 难以在合理的时间内完成模型的训练。为了更高效地处理大规模数据或训练复杂的深度学习模型,利用多个 GPU 或多个节点的并行计算变得至关重要。这正是数据并行和分布式训练技术诞生的背景。
分布式训练通过在多个设备上分配计算负载,不仅能够显著缩短训练时间,还可以进一步提高模型的可扩展性和性能。基于此,深度学习中的并行训练技术主要分为数据并行和模型并行两大类,其实现在真正流行的应该时模型并行,因为训练大模型的时候一张A100是放不下的,可能需要把模型拆成几块放在不同的显卡上,但是我现在接触的最多的还是数据并行,因为单张卡的显存太小了,只能通过增加显卡数量来加快训练的速度。
数据并行 (Data Parallelism)
在数据并行中,模型的副本被复制到每个 GPU(或节点)上,所有 GPU 共享相同的模型参数,并将输入数据划分为多个小批次(mini-batch),分配到各个设备上进行并行计算。每个 GPU 独立计算其批次的前向传播和反向传播,最后将各 GPU 上计算得到的梯度合并,并同步更新模型参数。
数据并行主要有两种实现方式:
- DataParallel:这是 PyTorch 中最早的并行方法,适用于单机多卡的训练。它通过自动划分输入数据,并在所有 GPU 之间进行前向计算和梯度求和,最后在主设备上更新模型参数。然而,由于参数的同步和复制操作集中在主设备上,DataParallel 在多卡训练时存在性能瓶颈,特别是在大规模训练时。
- DistributedDataParallel (DDP):DDP 是 PyTorch 官方推荐的多机多卡并行方式,通过将模型和数据分布到多个设备,并使用通信原语(如 NCCL、MPI)来在各个设备间同步梯度。与 DataParallel 相比,DDP 更加高效,因为它能够避免模型参数的额外复制操作,通信操作也更加并行化。
模型并行 (Model Parallelism)
与数据并行相反,模型并行将模型的不同部分划分给不同的 GPU。例如,当模型的参数过大以至于无法被单个 GPU 存储时,可以将模型的各层或各部分分配给不同的设备,彼此协作完成训练。模型并行适用于超大规模模型的训练,但相较于数据并行,其实现和调优难度较大,通信开销也更为显著。
数据并行 (Data Parallelism)训练方式
在Pytorch中有两种方式来实现数据并行:
数据并行(DataParallel,DP)
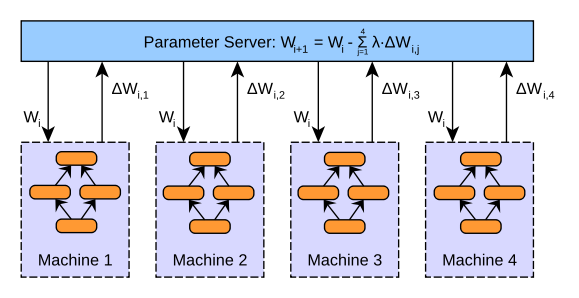
DataParallel采用参数服务器架构,其训练过程是单进程的。在训练时,会将一块GPU作为server,其余的GPU作为worker,在每个GPU上都会保留一个模型的副本用于计算。训练时,首先将数据拆分到不同的GPU上,然后在每个worker上分别进行计算,最终将梯度汇总到server上,在server进行模型参数更新,然后将更新后的模型同步到其他GPU上。这种方式有一个很明显的弊端,作为server的GPU其通信开销和计算成本非常大。它需要和其他所有的GPU进行通信,并且梯度汇总、参数更新等步骤都是由它完成,导致效率比较低。并且,随着多卡训练的GPU数量增强,其通信开销也会线性增长。如果你的数据集并不大,只有几千的规模,并且你多卡训练时的卡也不多,只有4块左右,那么DataParallel会是一个不错的选择。
以伪码方式列出了Parameter Server并行梯度下降的主要步骤:

可以看到Parameter Server由server节点和worker节点组成,其主要功能分别如下:
server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点。
在物理架构上,PS其实是和spark的master-worker的架构基本一致的,
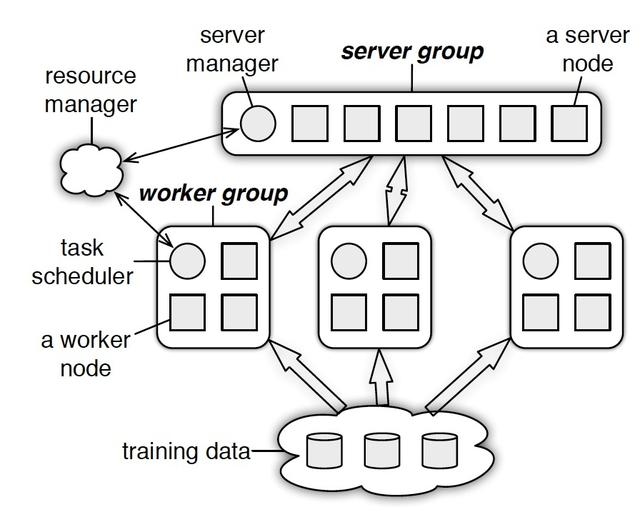
可以看到,PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
server group内部包含多个server node,每个server node负责维护一部分参数,server manager负责维护和分配server资源;
每个worker group对应一个application(即一个模型训练任务),worker group之间,以及worker group内部的worker node互相之间并不通信,worker node只与server通信。
结合PS的物理架构,PS的并行训练整体示意图
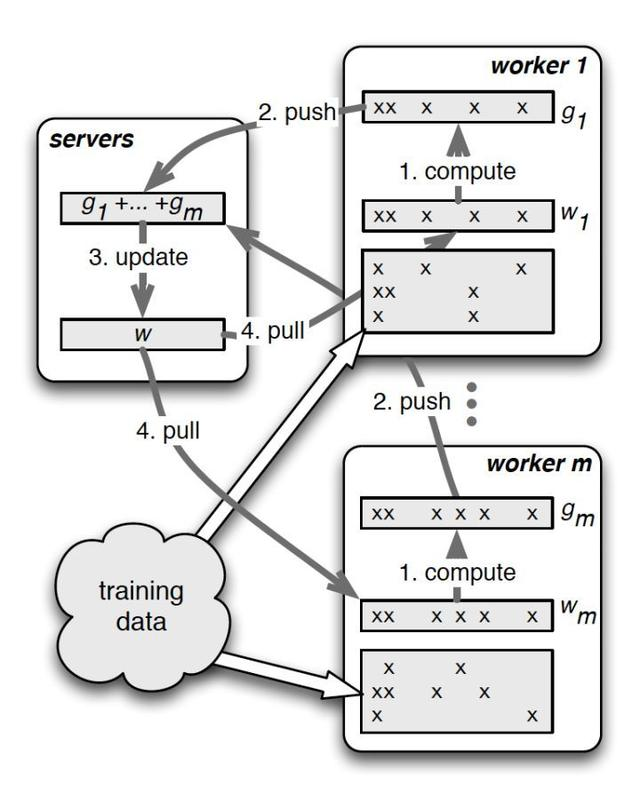
其中最关键的两个操作就是push和pull:
push:worker节点利用本节点上的训练数据,计算好局部梯度,上传给server节点;
pull:为了进行下一轮的梯度计算,worker节点从server节点拉取最新的模型参数到本地。
DataParallel 使用起来非常方便,我们只需要用 DataParallel 包装模型,再设置一些参数即可。需要定义的参数包括:参与训练的 GPU 有哪些,device_ids=gpus;用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总:
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
值得注意的是,模型和数据都需要先 load 进 GPU 中,DataParallel 的 module 才能对其进行处理,否则会报错:
# 这里要 model.cuda()
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
# 这里要 images/target.cuda()
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
分布式数据并行(DistributedDataParallel,DDP)
DDP采用Ring-All-Reduce架构,其训练过程是多进程的。如果要用DDP来进行训练,我们通常需要修改三个地方的代码:数据读取器dataloader,日志输出print,指标评估evaluate。其代码实现略微复杂,不过我们只需要始终牢记一点即可:每一块GPU都对应一个进程,除非我们手动实现相应代码,不然各个进程的数据都是不互通的。Pytorch只为我们实现了同步梯度和参数更新的代码,其余的需要我们自己实现。
DDP 的基本原理
DDP 的核心思想是将每个 GPU 作为独立的进程进行处理,每个 GPU 拥有一个模型副本,并独立执行前向传播、反向传播。DDP 的主要步骤如下:
- 数据均分:在训练开始时,数据集被均等分配到每个进程(对应每个 GPU)。每个 GPU 独立处理其分配到的数据。
- 前向传播:每个 GPU 使用自身的数据进行前向传播,计算模型输出。
- 反向传播与梯度计算:每个 GPU 计算其模型的梯度。
- 梯度同步:通过
Ring-All-Reduce算法同步各 GPU 的梯度,使得所有 GPU 拥有相同的梯度。 - 参数更新:每个 GPU 使用同步后的梯度来更新模型参数。因为所有 GPU 使用相同的梯度,模型在每个 GPU 上都是一致的。
The Communication Problem
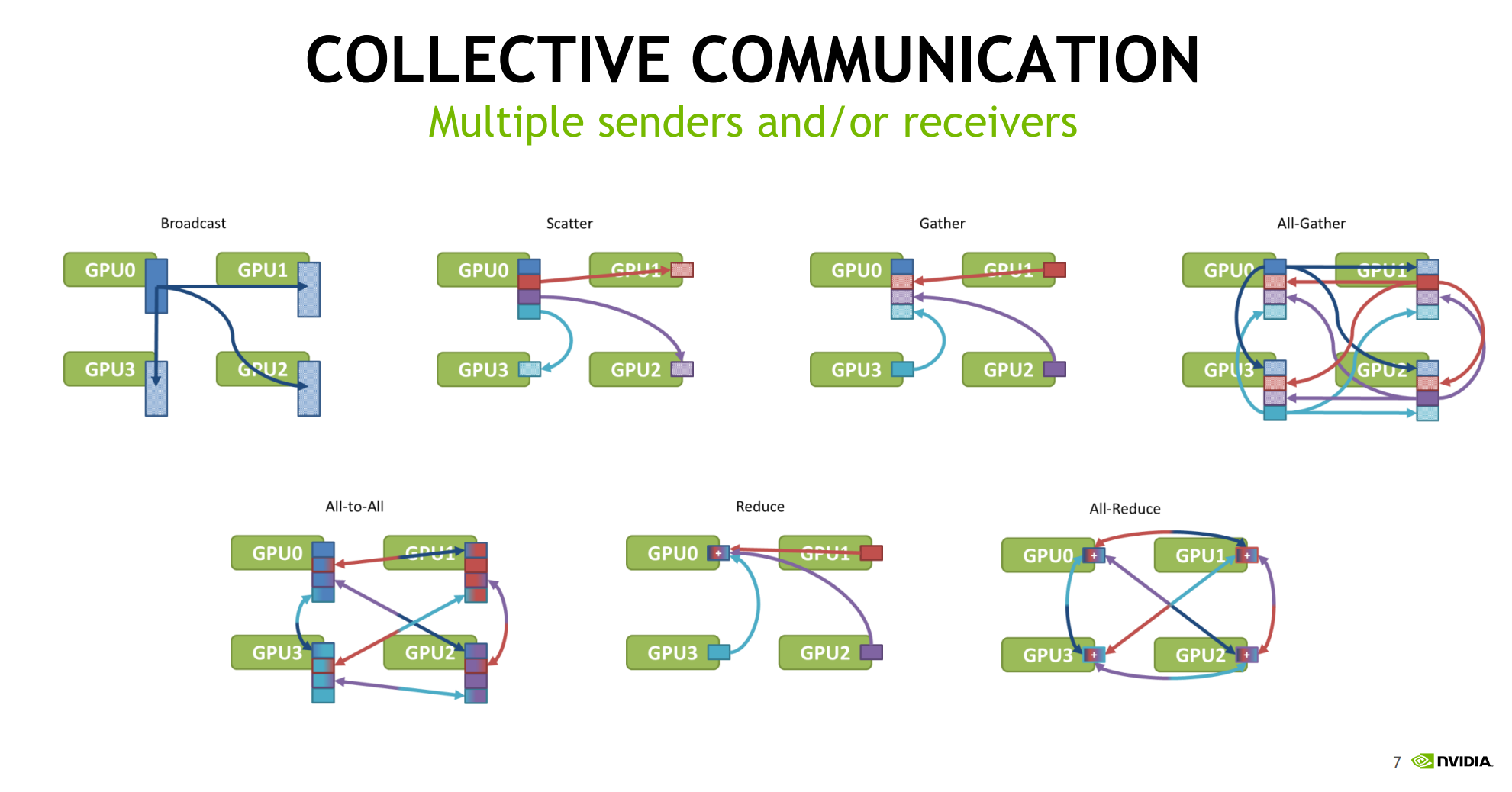
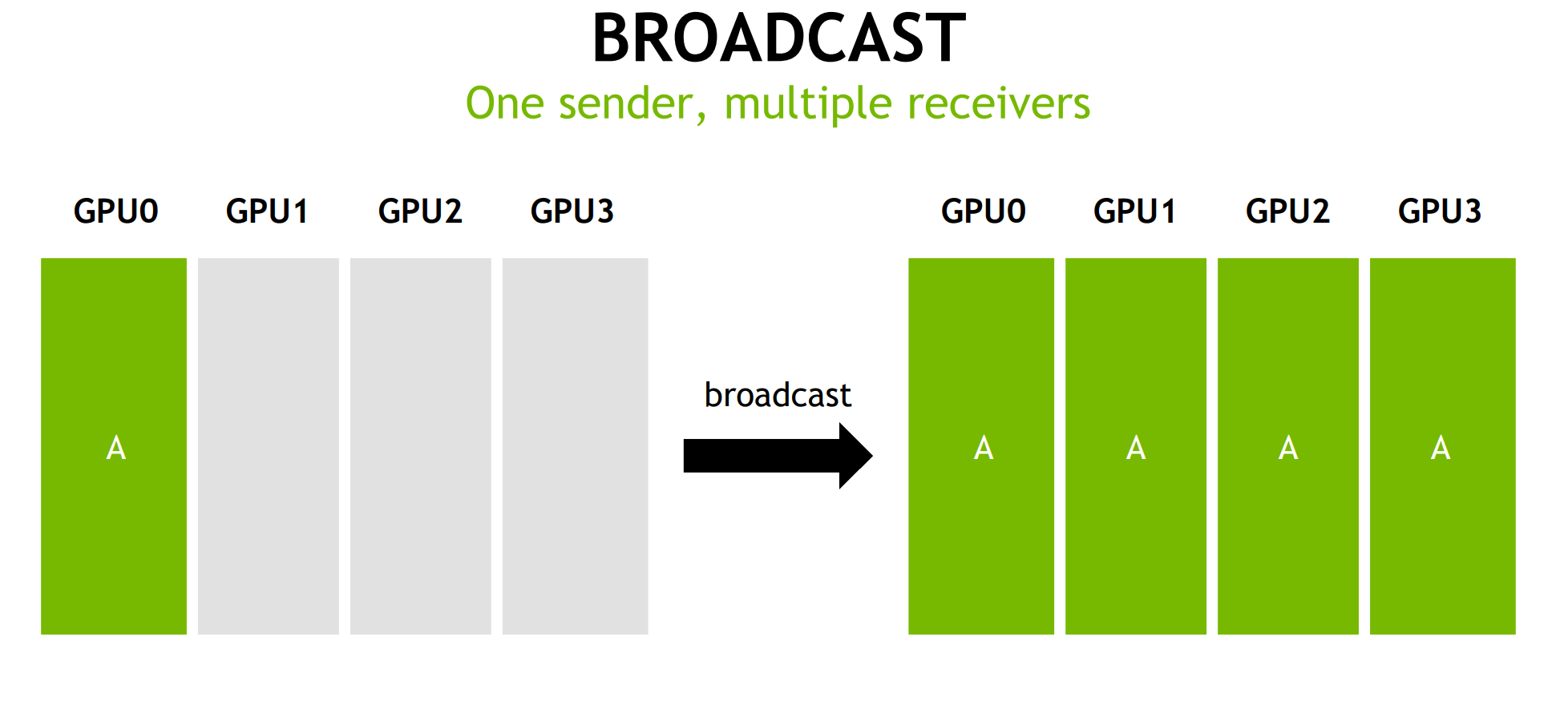
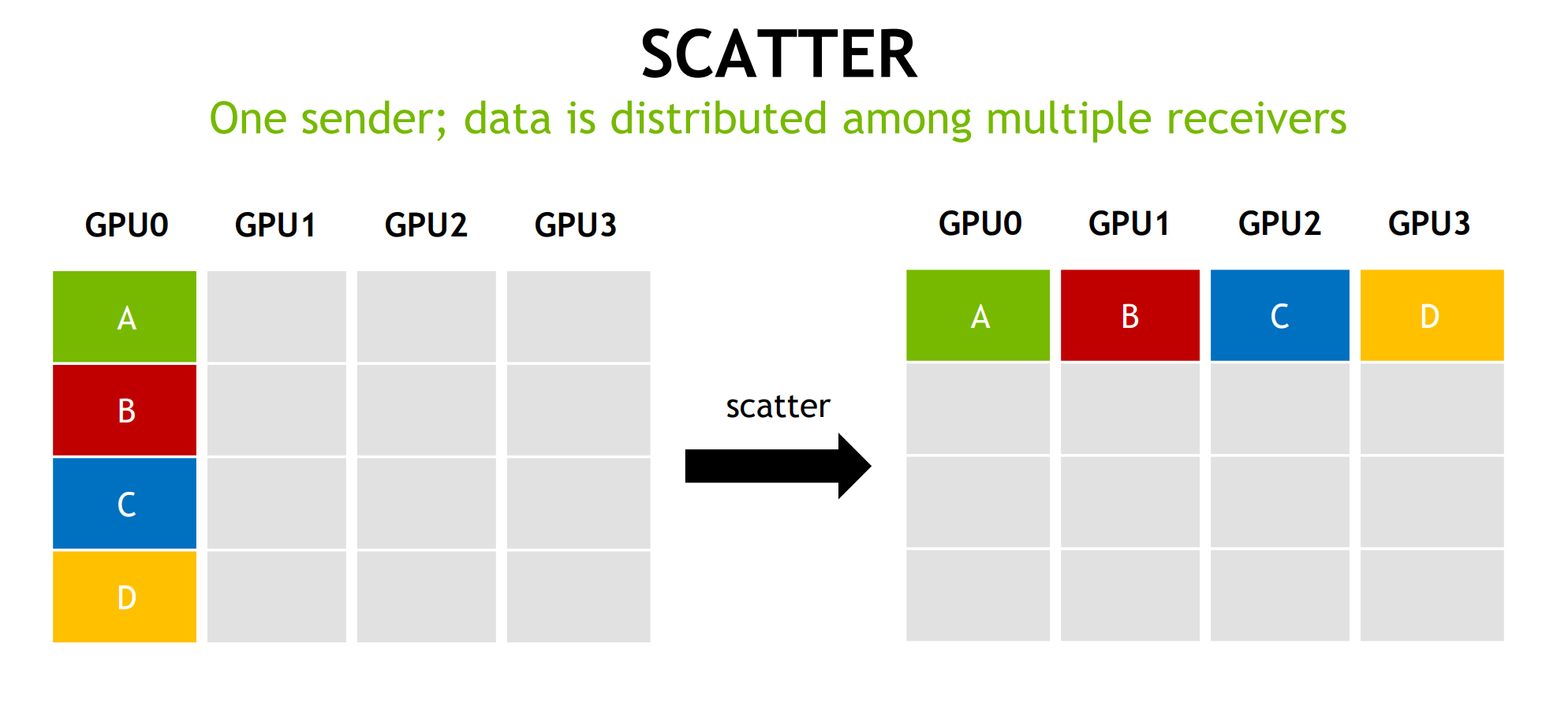
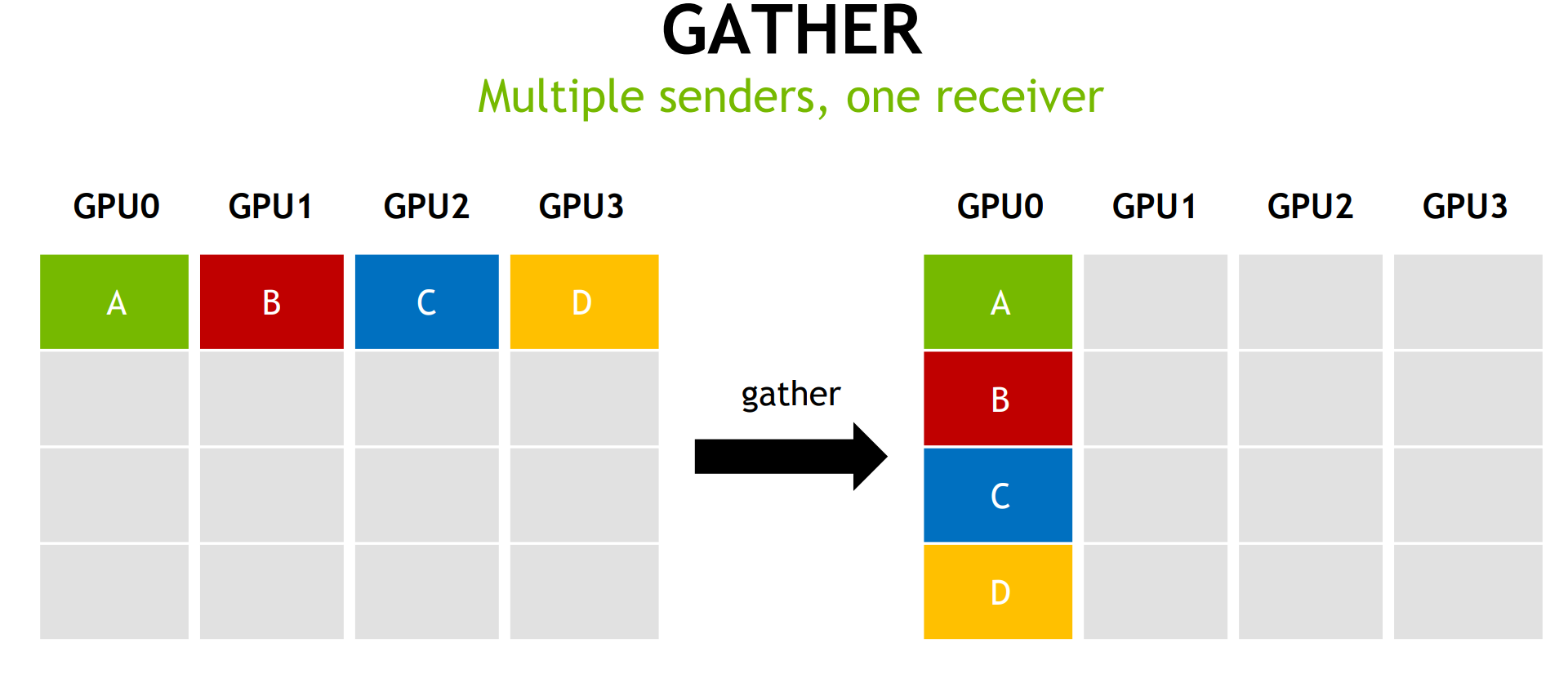
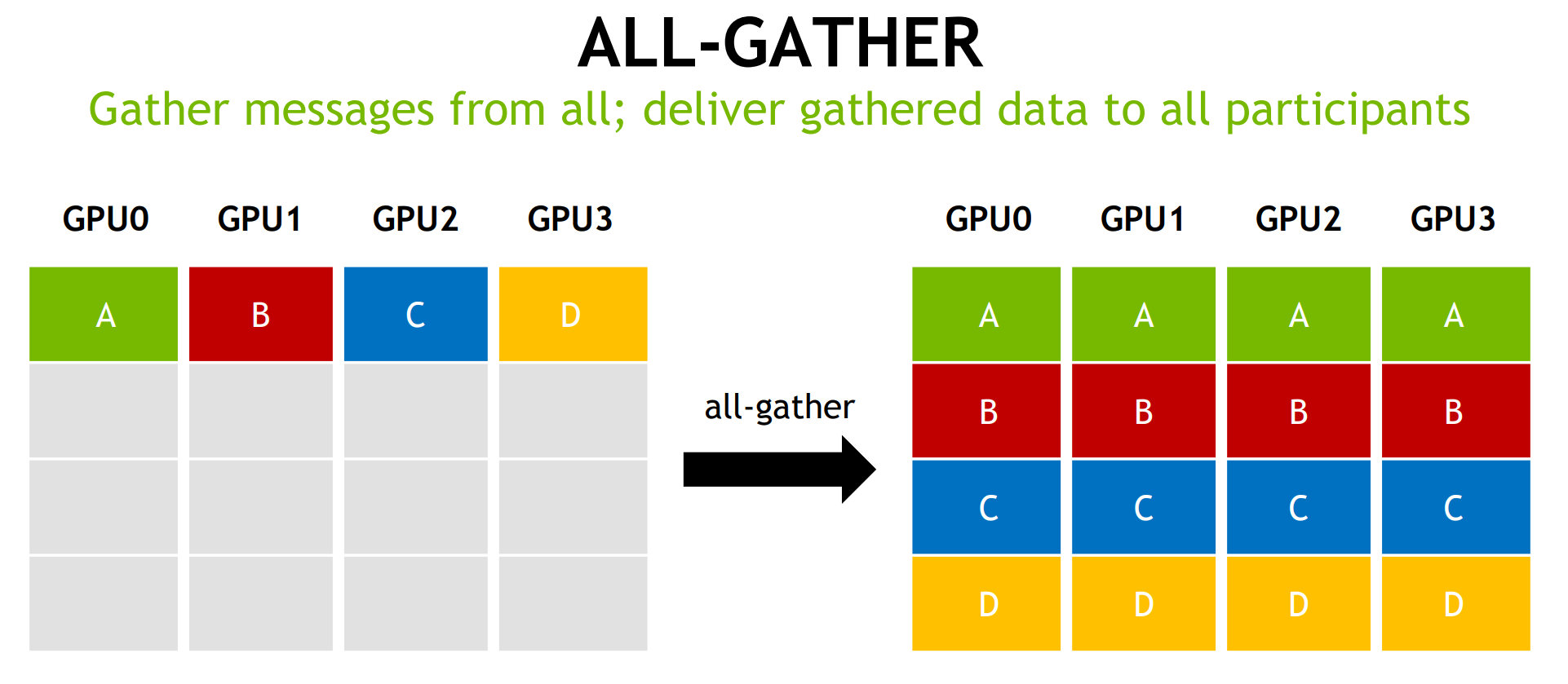
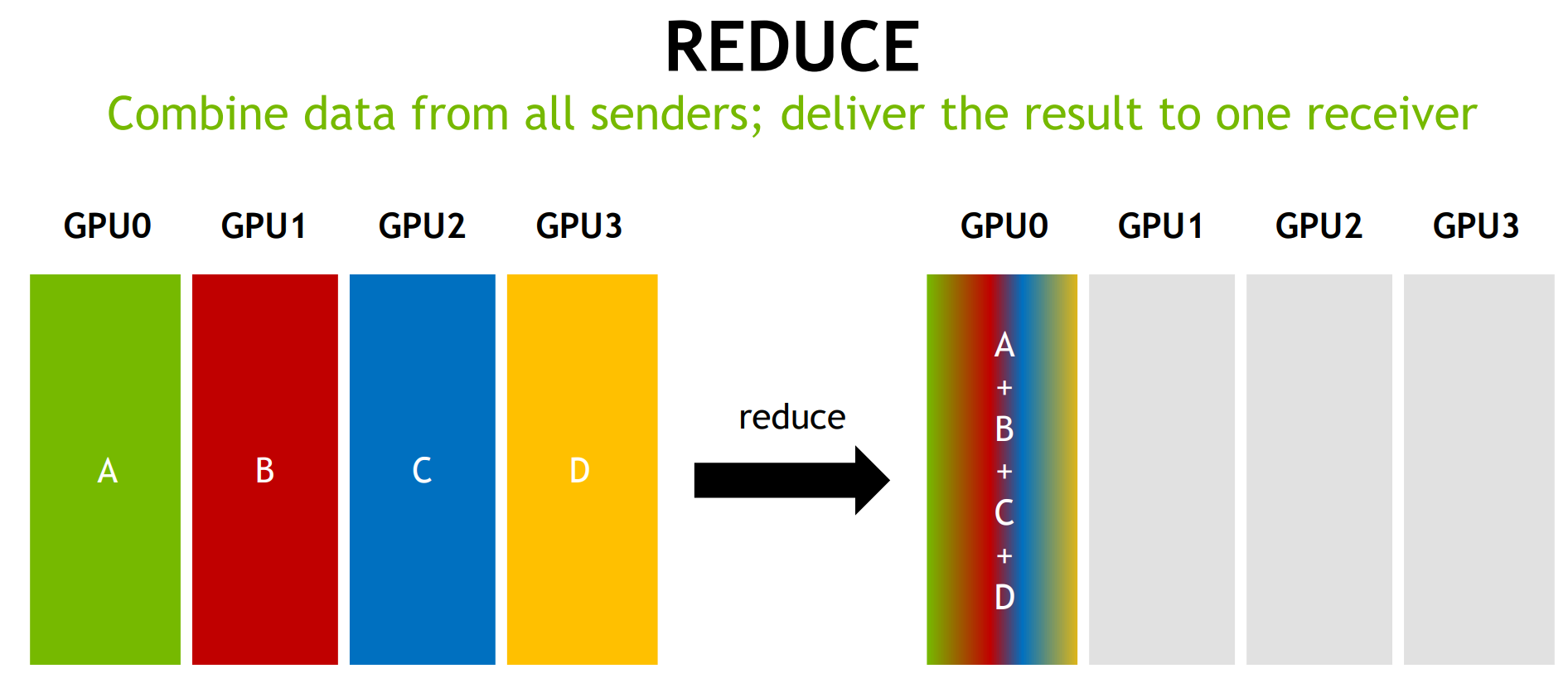
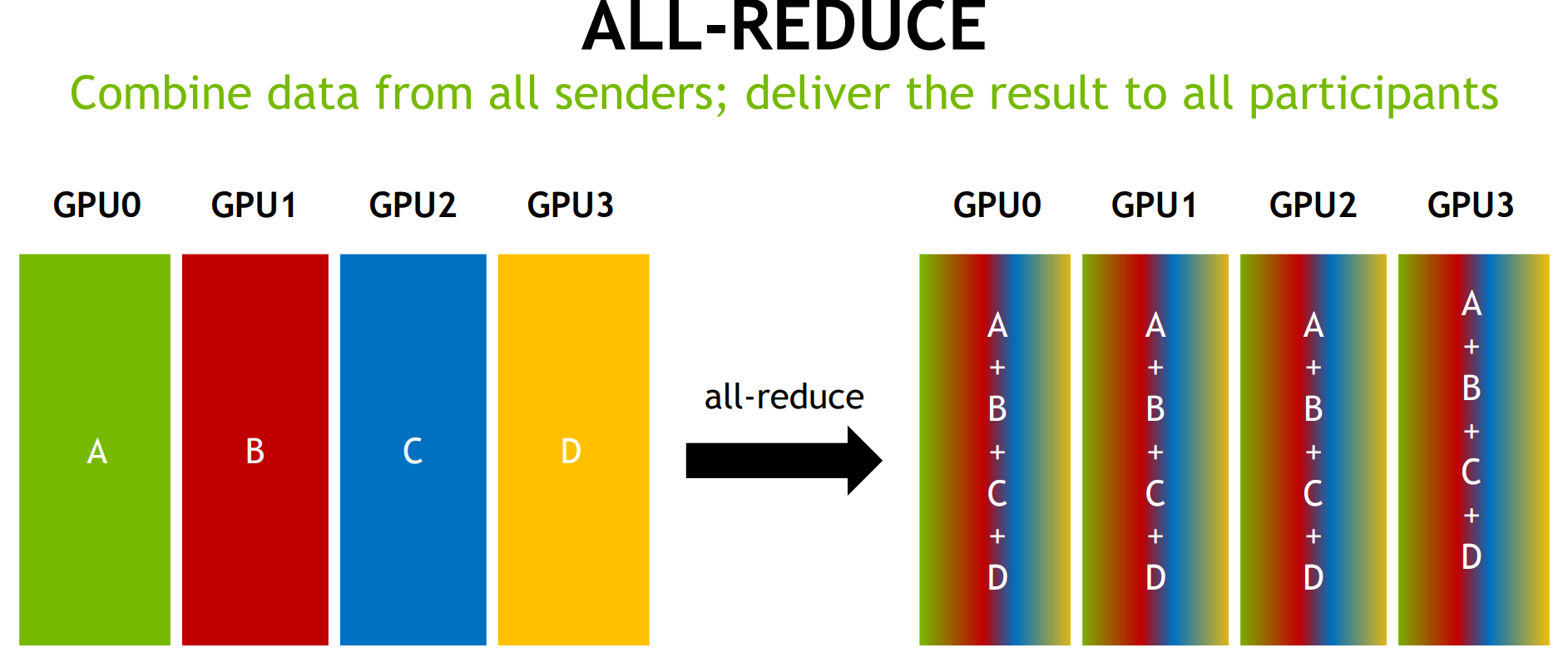

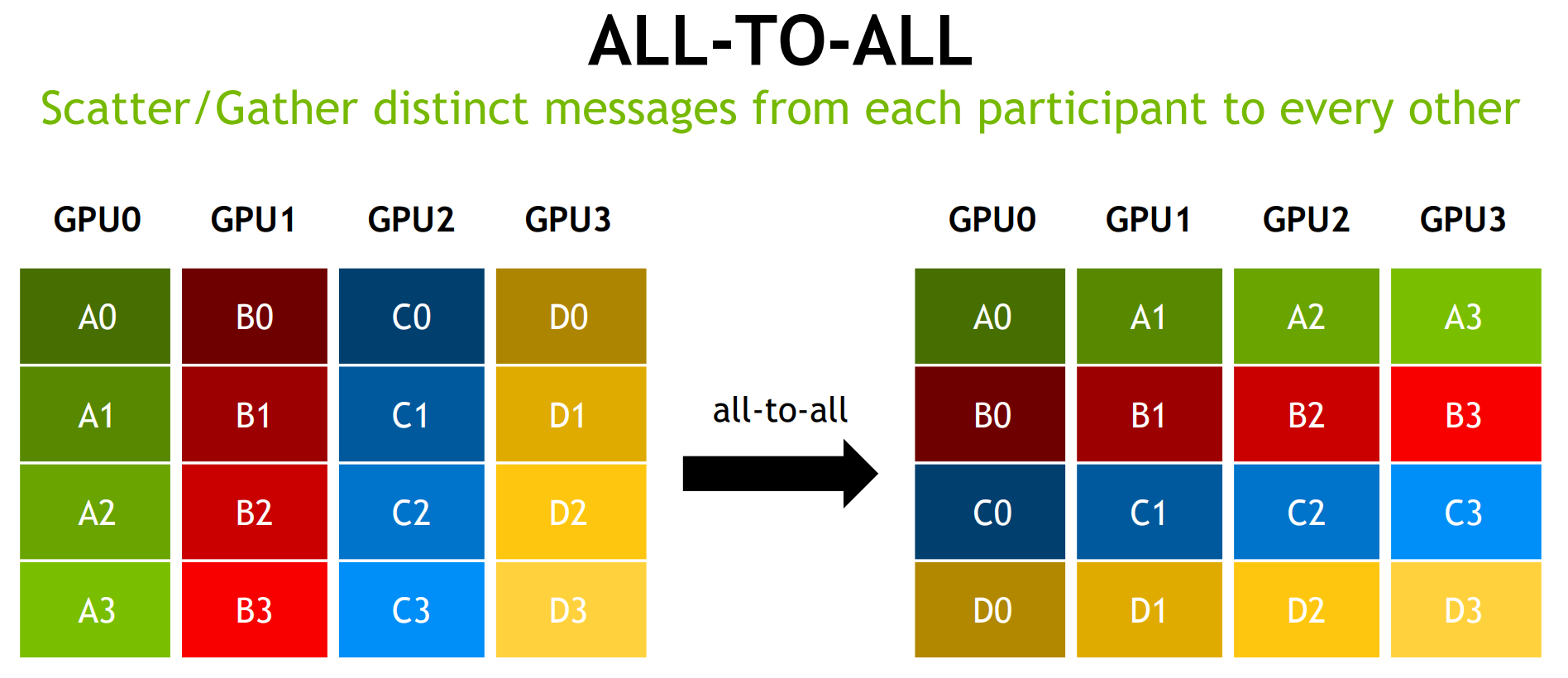
在将神经网络训练并行化到多个 GPU 上时,必须选择如何将不同的操作分配到可用的不同 GPU 上。在这里,以数据并行随机梯度下降 (SGD) 的技术为例。与标准 SGD 一样,梯度下降是使用数据子集(小批量)完成的,需要多次迭代才能遍历整个数据集。然而,在数据并行训练中,每个 GPU 都有整个神经网络模型的完整副本,并且每次迭代仅分配小批量中样本的子集。对于每次迭代,每个 GPU 都会在其数据上运行网络的前向传播,然后进行误差反向传播以计算相对于网络参数的损失梯度。最后,GPU 相互通信以平均不同 GPU 计算的梯度,将平均梯度应用于权重以获得新的权重。所有 GPU 都同步进行迭代,一旦某个 GPU 完成迭代,它必须等待所有其他 GPU 完成迭代,以便正确更新权重。这相当于在单个 GPU 上执行 SGD,但我们通过将数据分布在多个 GPU 之间并并行执行计算来获得加速。
当只有两个 GPU 和以兆字节为单位的参数时,这些 GPU 如何通信可能并不重要。但是,当模型有数十亿个参数时,梯度可能占用千兆字节的空间(因为每个参数都有一个梯度值),并且你要协调数十个 GPU,通信机制就变得至关重要。
例如,考虑最直接的通信机制。每个 GPU 都会在其小批量子集上计算梯度。然后,每个 GPU 将其梯度发送给单个 GPU,该 GPU 取所有梯度的平均值,并将平均值发送回所有其他 GPU。
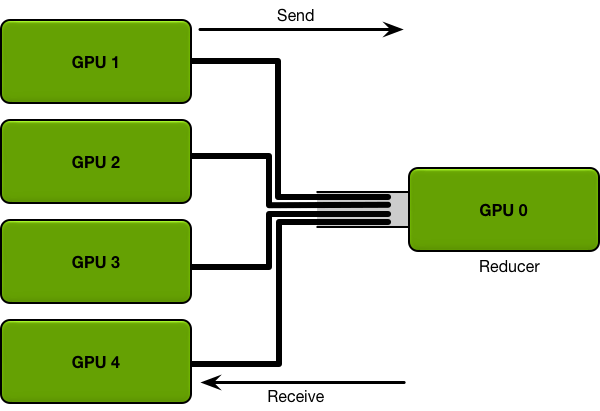
需要发送的数据越多,发送所需的时间就越长;每个通信通道都有最大吞吐量(带宽)。例如,良好的互联网连接可以提供每秒 15 兆字节的带宽,而千兆以太网连接可以提供每秒 125 兆字节的带宽。HPC 集群上的专用网络硬件(例如 Infiniband)可以在节点之间提供每秒几千兆字节的带宽。
在从单个 GPU 发送和接收数据的直接机制中,该单个 GPU 必须从所有 GPU 接收所有参数,并将所有参数发送给所有 GPU。系统中的 GPU 越多,通信成本就越高。
让我们来评估一下这种沟通策略在真实模型上的效果,比如以百度 Deep Speech 2 为模型的语音识别网络,具有三亿个可训练参数。三亿个参数,每个参数四个字节,大约是 1.2 GB 的数据。假设网络硬件可以支持每秒一 GB 的带宽;在这种情况下,如上所述将系统并行化到两个 GPU 上将使每次迭代减慢 1.2 秒。将您的训练并行化到十个 GPU 上将使每次迭代减慢 10.8 秒;随着 GPU 数量的增加,每次迭代所需的时间也会线性增长。即使每次迭代只需几秒钟,这种通信成本的线性增长也会很快使进一步的并行化变得不切实际,并降低训练效率。
一种替代方案是放弃训练算法的同步特性,并消除所有 GPU 在梯度下降迭代中同步前进的限制。然而,虽然这可以更容易并行化模型,但消除这种限制的算法(异步 SGD 的变体)可能难以调试,并且对于某些模型来说,可能会收敛到低于标准的结果,因此我们不会在本篇博文中考虑它们。
相反,我们可以通过使用高性能计算领域的分布式缩减算法并利用带宽最优环型全缩减来解决通信问题。
Ring-All-Reduce算法
上述简单通信策略的主要问题是,通信成本随系统中 GPU 数量的增加而线性增长。相比之下,Ring Allreduce 是一种通信成本恒定且与系统中 GPU 数量无关的算法,仅由系统中 GPU 之间最慢的连接决定;事实上,如果您只将带宽作为通信成本的一个因素(并忽略延迟),Ring Allreduce 是一种最佳通信算法。(当您的模型很大并且您需要多次发送大量数据时,这是一个很好的通信成本估算。)
Ring Allreduce 中的 GPU 排列成逻辑环。每个 GPU 应该有一个左邻居和一个右邻居;它只会将数据发送到其右邻居,并从其左邻居接收数据。
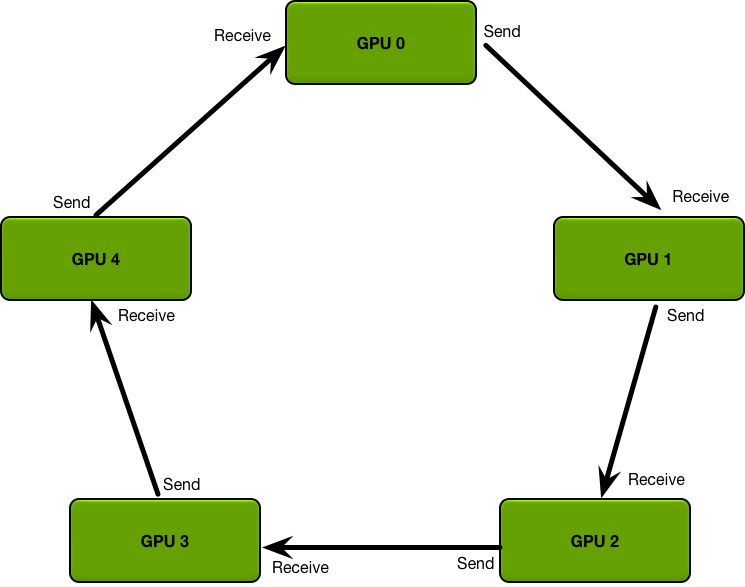
该算法分为两个步骤:首先是scatter-reduce,然后是allgather。在scatter-reduce步骤中,GPU 将交换数据,以便每个 GPU 最终获得最终结果的一部分。在allgather步骤中,GPU 将交换这些数据块,以便所有 GPU 最终获得完整的最终结果。
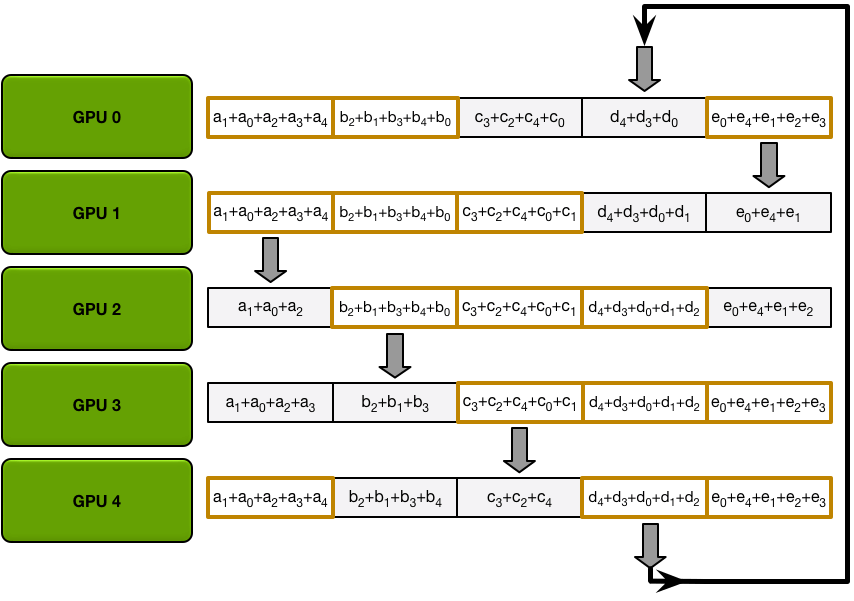
The Scatter-Reduce
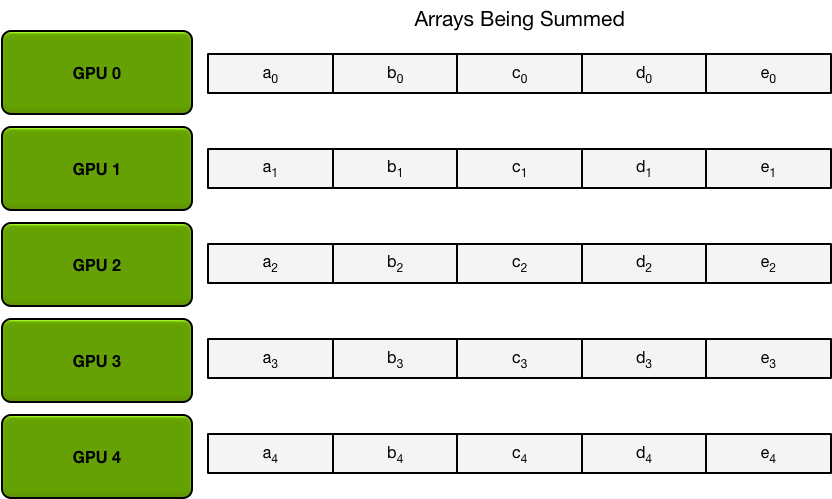
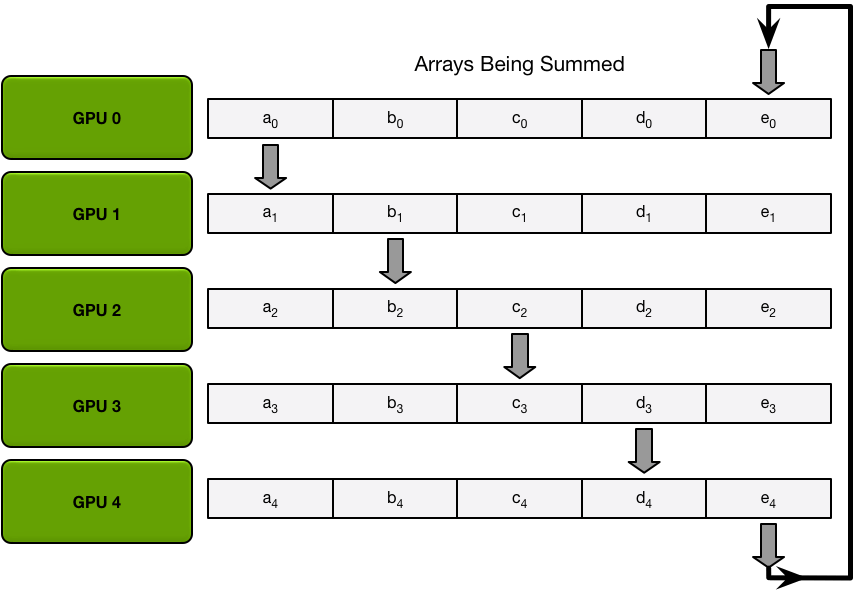
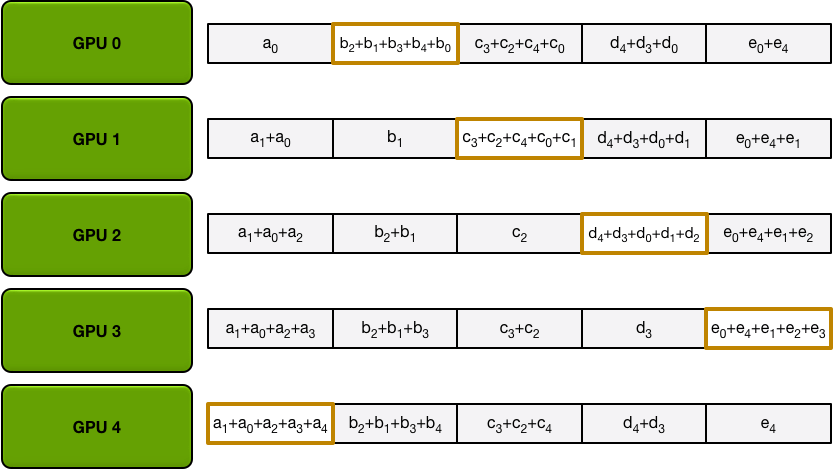
为了简单起见,我们假设目标是对单个大型浮点数数组的所有元素逐个求和;系统中有 N 个 GPU,每个 GPU 都有一个相同大小的数组,并且在 allreduce 结束时,每个 GPU 都应该有一个相同大小的数组,其中包含原始数组中数字的总和。
首先,GPU 将阵列分成 N 个小块(其中 N 是环中的 GPU 数量)。
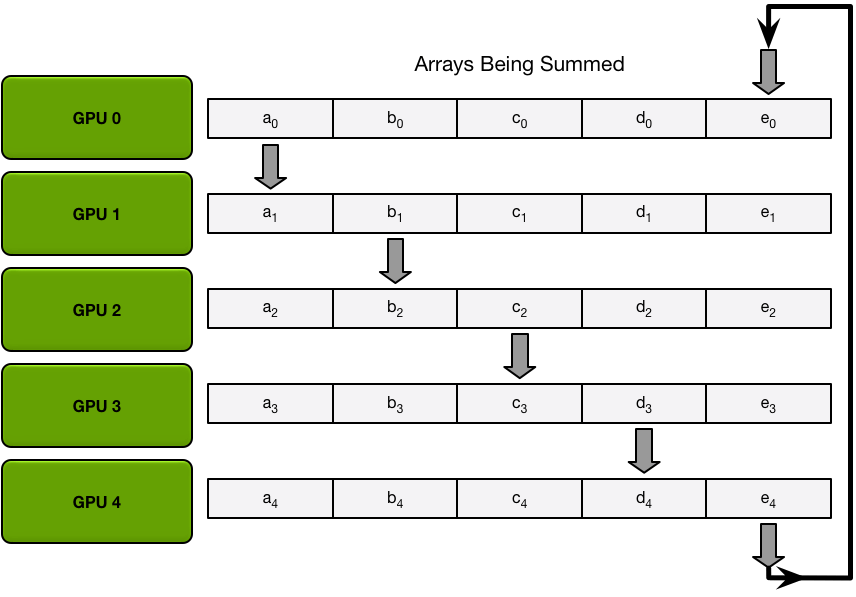
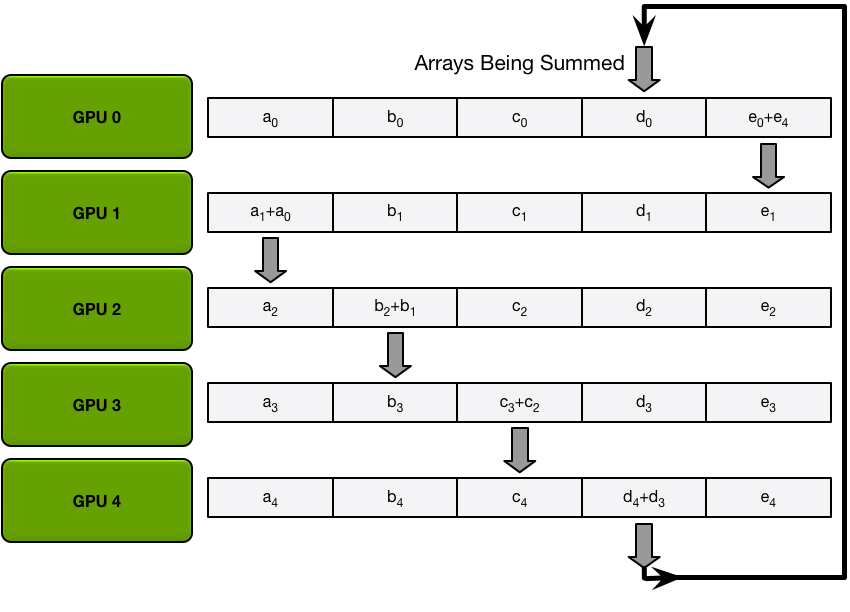
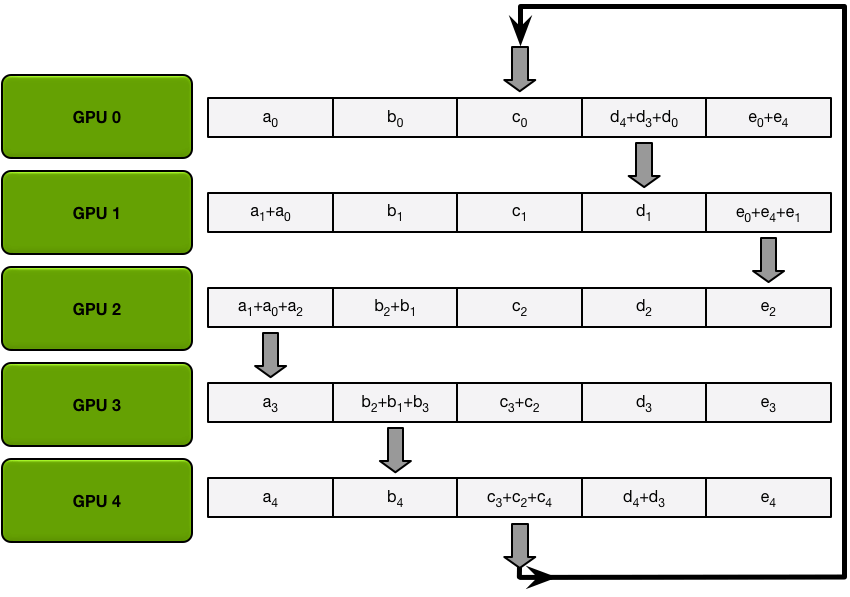
接下来,GPU 将执行 N-1 次scatter-reduce迭代;在每次迭代中,GPU 会将其一个块发送到其右侧邻居,并从其左侧邻居接收一个块并累积到该块中。每个 GPU 发送和接收的块在每次迭代中都不同;第 n 个 GPU 首先发送块 n 并接收块 n – 1,然后从那里向后继续,每次迭代发送它在上一次迭代中收到的块。
例如,在第一次迭代中,上图中的五个 GPU 将发送和接收以下块:
| 图形处理器 | 发送 | 收到 |
|---|---|---|
| 0 | 区块 0 | 第4部分 |
| 1 | 区块 1 | 区块 0 |
| 2 | 第 2 部分 | 区块 1 |
| 3 | 第 3 部分 | 第 2 部分 |
| 4 | 第4部分 | 第 3 部分 |
第一次发送和接收完成后,每个 GPU 将拥有一个由两个不同 GPU 上的同一块的总和组成的块。例如,第二个 GPU 上的第一个块将是第二个 GPU 和第一个 GPU 上该块的值的总和。
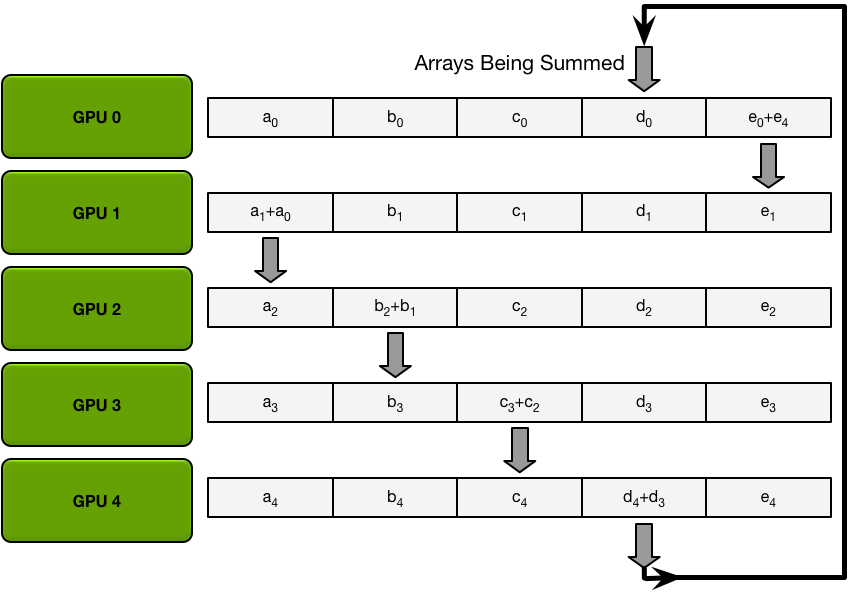
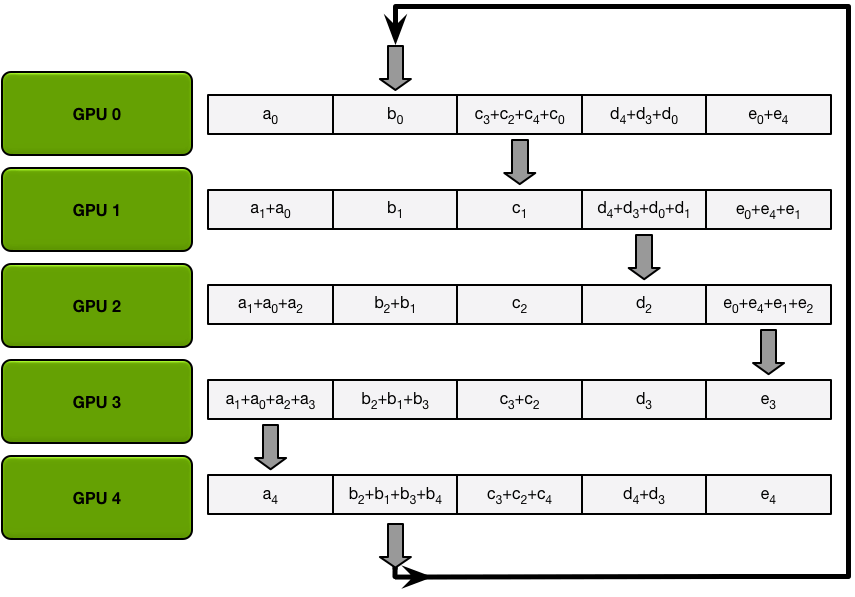
在接下来的迭代中,该过程将继续,到最后,每个 GPU 将有一个块,其中包含所有 GPU 中该块中所有值的总和。下图展示了所有数据传输和中间结果,从第一次迭代开始,一直持续到分散-减少完成。
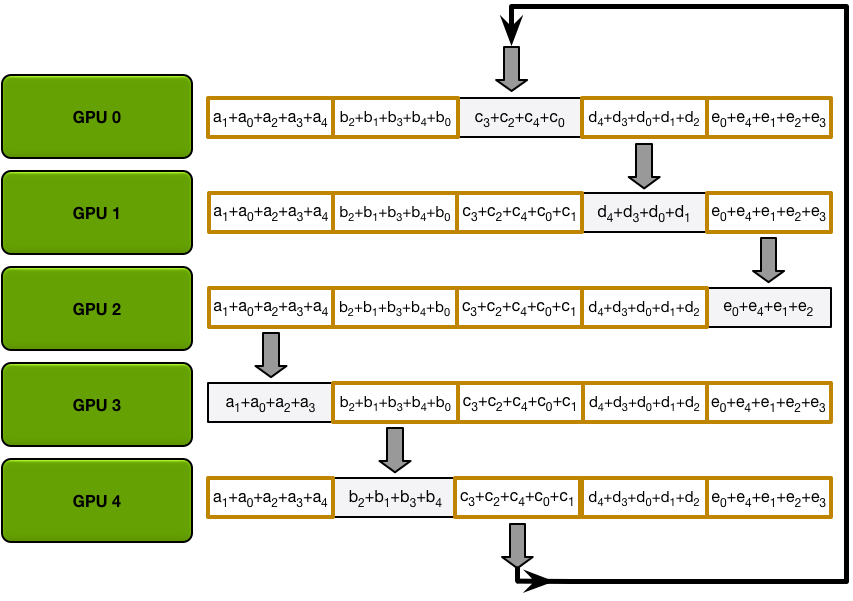
The Allgather
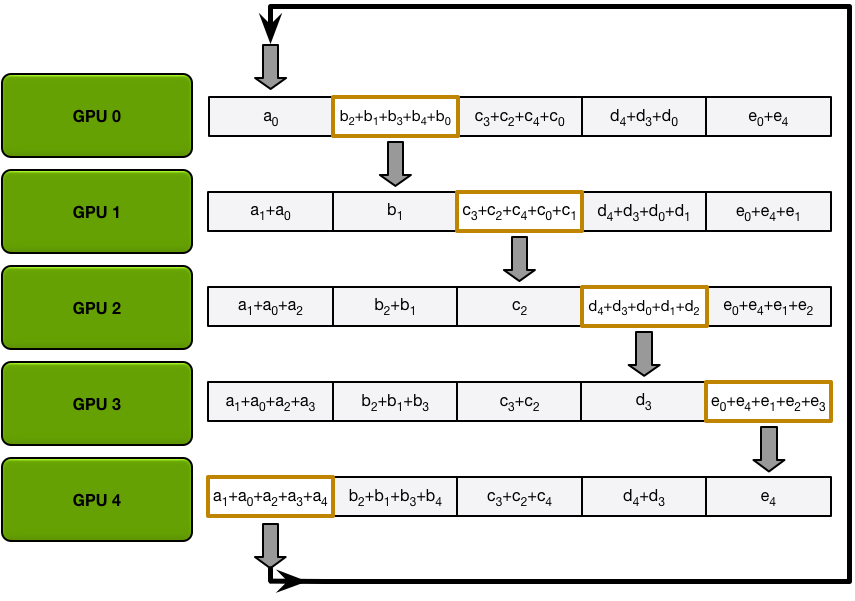
分散-归约步骤完成后,每个 GPU 都有一个值数组,其中一些值(每个 GPU 一个块)是包含所有 GPU 贡献的最终值。为了完成 allreduce,GPU 必须交换这些块,以便所有 GPU 都具有所有必要的值。
环形全聚集过程与散射-减少过程完全相同(发送和接收 N-1 次迭代),不同之处在于 GPU 不会累积收到的值,而是直接覆盖块。第 n 个 GPU 首先发送第 n+1 个块并接收第 n 个块,然后在未来的迭代中始终发送刚刚收到的块。
例如,在我们的五 GPU 设置的第一次迭代中,GPU 将发送和接收以下块:
| 图形处理器 | 发送 | 收到 |
|---|---|---|
| 0 | 区块 1 | 区块 0 |
| 1 | 第 2 部分 | 区块 1 |
| 2 | 第 3 部分 | 第 2 部分 |
| 3 | 第5部分 | 第 3 部分 |
| 4 | 区块 0 | 第5部分 |
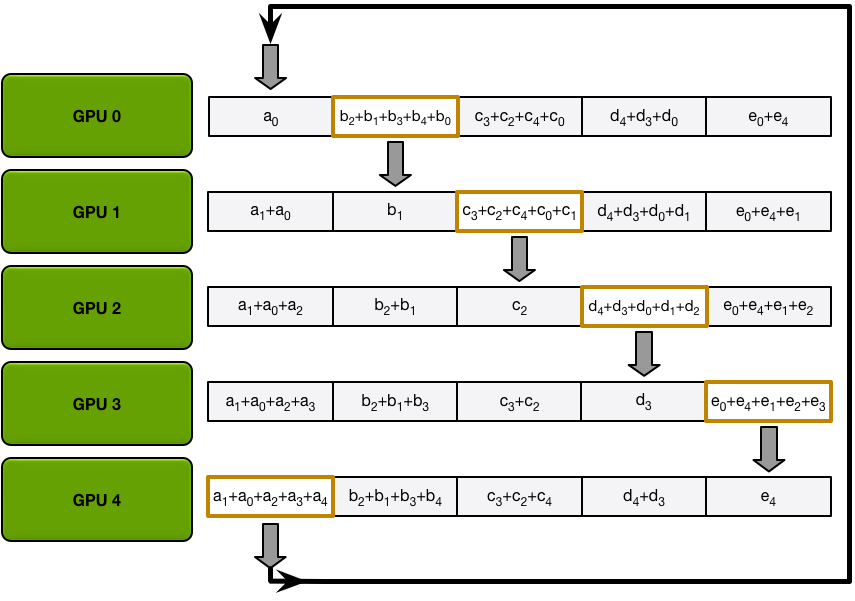
第一次迭代完成后,每个 GPU 将拥有最终数组的两个块。
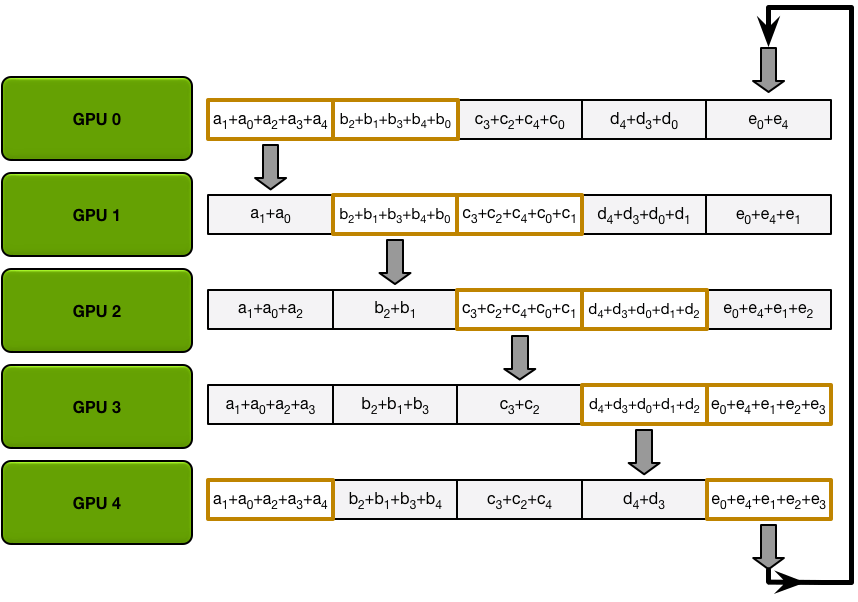
在接下来的迭代中,该过程将继续,到最后,每个 GPU 将拥有整个阵列的完整累积值。下图展示了所有数据传输和中间结果,从第一次迭代开始,一直持续到全部收集完成。

在 DDP 中,Ring-All-Reduce 算法是一种高效的梯度同步方式,能够显著减少通信开销。该算法的流程如下:
- 环形架构:所有 GPU 按照环形顺序相连,每个 GPU 只需要与它相邻的两个 GPU 通信。
- 梯度传输与聚合:每个 GPU 将自身计算的梯度与相邻 GPU 的梯度进行聚合,并将结果传递给下一个 GPU。这个过程在整个环形链中进行。
- 最终同步:经过 N 次通信后(N 为 GPU 数量),每个 GPU 都将拥有聚合后的梯度值,此时每个 GPU 上的梯度数据完全同步。
由于 Ring-All-Reduce 算法只在相邻 GPU 间进行通信,且通信量与 GPU 数量无关,因此其通信开销相较于 DP 的主设备集中式架构要小得多。如果你的训练数据达到了十万这个量级,并且需要使用4卡及以上的设备来进行训练,DDP将会是你的最佳选择。
使用 torch.distributed 加速并行训练
在 pytorch 1.0 之后,官方终于对分布式的常用方法进行了封装,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟了~

与 DataParallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,我们只需要编写一份代码,torch 就会自动将其分配给 n 个进程,分别在 n 个 GPU 上运行。
与 DP 不同,DDP 是多进程架构,每个 GPU 对应一个独立的进程。为了正确使用 DDP,需要修改几处代码:
Dataloader 的分布式处理:使用
torch.utils.data.DistributedSampler对数据集进行划分,确保每个进程处理不同的批次数据:train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler)初始化进程:使用
torch.distributed.init_process_group初始化分布式进程组,设置通信后端为NCCL(GPU) 或GLOO(CPU):torch.distributed.init_process_group(backend='nccl')DDP 包装模型:将模型封装成 DDP 格式:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)日志输出与评估:由于每个进程是独立的,因此需要通过设置某些进程(通常为 rank=0)来输出日志和进行评估,以避免重复输出。
完整的分布式训练代码框架:
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSampler
def setup_ddp(rank, world_size):
dist.init_process_group(backend='nccl', rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def train(rank, world_size):
setup_ddp(rank, world_size)
# 设置分布式数据加载
dataset = ...
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, batch_size=batch_size, sampler=sampler)
# 模型和优化器
model = DDP(model.cuda(rank), device_ids=[rank])
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环
for epoch in range(epochs):
sampler.set_epoch(epoch)
for data, target in dataloader:
data = data.cuda(rank)
target = target.cuda(rank)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
world_size = torch.cuda.device_count()
torch.multiprocessing.spawn(train, args=(world_size,), nprocs=world_size)
分布式训练中的其他关键技术
- 数据并行 (Data Parallelism):数据并行通过划分数据集来实现并行化,即将输入数据切分成不同的小批量,分配给不同的 GPU 或节点处理。
- 梯度同步 (Gradient Synchronization):为了在多个设备间保持模型参数的一致性,梯度同步是分布式训练的关键步骤。通常采用 All-Reduce 操作,将每个设备上的梯度聚合,再将结果广播回每个设备。这个其实是我后来意识到的,比如我计算Dice系数的时候其实每张卡都会对各自的Batch来算一次,可能不同的卡计算出来高低是不一样的,所以这种情况我们需要做检查来让结果更高一些?
- 学习率调度 (Learning Rate Scheduling):分布式训练中常用 SGDR(Stochastic Gradient Descent with Warm Restarts) 等学习率调度方法,在学习率随时间衰减的同时,周期性地进行“冷启动”,从而避免局部最优问题。
- 混合精度训练 (Mixed Precision Training):通过使用半精度浮点数(FP16)进行前向和反向计算,同时保持参数更新的精度(FP32),混合精度训练能够大幅降低计算和内存开销,提高训练速度。在 PyTorch 中,可以使用 apex 工具进行混合精度训练。Apex的安装和使用可能对Pytorch版本有要求,其实这部分我还没有使用过, 我用的其实是Pytorch自带的Autocast, 这部分因为采用半精度浮点型所以可能造成loss计算过程中某一步溢出, 需要定位自己转化为FP32?
torch.multiprocessing
Python 的 multiprocessing 模块是一个用于创建并发处理的库,它允许我们通过多进程并行处理任务。这与 Python 的线程不同,multiprocessing 创建的是多个进程(而不是线程),因此每个进程都有独立的内存空间,这避免了 Python 的 GIL(全局解释器锁)对并发执行的限制。我现在使用的就是multiprocessing写的DDP
多进程并行的优势
- 规避 GIL:Python 的全局解释器锁 (GIL) 会限制多线程的并行计算能力,特别是在 CPU 密集型任务中。
multiprocessing使用多个独立进程,可以有效绕过 GIL,充分利用多核 CPU 或多个 GPU。 torch.multiprocessing 进行多进程控制。绕开 torch.distributed.launch 自动控制开启和退出进程的一些小毛病~ - 进程隔离:每个进程拥有独立的内存空间和资源,进程之间相互独立,避免了多线程共享数据导致的资源竞争问题。
- 跨多 GPU 并行:在深度学习任务中,
multiprocessing经常用于创建与每个 GPU 关联的独立进程,实现高效的分布式训练。
multiprocessing 的基本功能
- 创建进程
- 使用
multiprocessing.Process类来启动新进程,定义每个进程要执行的任务(即 target 函数)。
- 使用
- 进程同步
multiprocessing提供了锁(Lock)、信号量(Semaphore)、事件(Event)等用于进程间的同步操作,确保多个进程能够协调运行。
- 进程通信
- 通过管道(Pipe)和队列(Queue)实现不同进程间的数据传输。
- 进程池
- 使用
multiprocessing.Pool来管理多个进程,特别适合需要频繁创建和销毁进程的任务。
- 使用
基本使用方法
1、创建并启动进程multiprocessing.Process 是创建新进程的基本方法。以下是一个简单的例子:
import multiprocessing
def worker(num):
print(f'Worker: {num}')
if __name__ == '__main__':
processes = []
for i in range(5):
p = multiprocessing.Process(target=worker, args=(i,))
processes.append(p)
p.start()
for p in processes:
p.join() # 确保所有进程完成后才退出
在上面的例子中,创建了 5 个进程,分别执行 worker 函数。p.start() 启动进程,p.join() 等待进程结束。
2、使用进程池multiprocessing.Pool 提供了更高效的进程管理方式,可以控制一定数量的进程并复用它们。
import multiprocessing
def worker(num):
print(f'Worker: {num}')
if __name__ == '__main__':
with multiprocessing.Pool(4) as pool: # 创建一个进程池,最大进程数为 4
pool.map(worker, range(10)) # 将任务分配给进程池中的进程
- 进程池会复用进程,避免频繁创建和销毁进程的开销。
3、进程间通信
Queue:用于进程间安全地传递数据。
from multiprocessing import Process, Queue
def worker(q):
q.put("Hello from worker")
if __name__ == '__main__':
q = Queue()
p = Process(target=worker, args=(q,))
p.start()
print(q.get()) # 从队列中取出数据
p.join()
Pipe:用于在两个进程间建立双向通信管道。
from multiprocessing import Process, Pipe
def worker(conn):
conn.send("Message from worker")
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(child_conn,))
p.start()
print(parent_conn.recv()) # 接收来自子进程的消息
p.join()
4、进程同步multiprocessing.Lock 和 multiprocessing.Semaphore 等同步工具可以用于控制多个进程的并发执行,避免数据竞争。
from multiprocessing import Process, Lock
def worker(lock, num):
lock.acquire()
print(f'Worker: {num}')
lock.release()
if __name__ == '__main__':
lock = Lock()
processes = []
for i in range(5):
p = Process(target=worker, args=(lock, i))
processes.append(p)
p.start()
for p in processes:
p.join()
在分布式训练中的应用
在 PyTorch 的分布式训练中,multiprocessing 是一种重要工具,通常用于创建多个 GPU 的独立进程。例如,在使用 torch.distributed 时,通常使用 torch.multiprocessing.spawn 来启动多个 GPU 进程,每个进程分别处理各自的训练任务。
以下是一个使用 multiprocessing 和 torch.distributed 的例子:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
def cleanup():
dist.destroy_process_group()
def train(rank, world_size):
setup(rank, world_size)
# 创建模型并包装成 DDP 模型
model = ...
ddp_model = DDP(model.cuda(rank), device_ids=[rank])
# 数据加载器和优化器
train_loader = ...
optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.01)
for epoch in range(epochs):
for data, target in train_loader:
data = data.cuda(rank)
target = target.cuda(rank)
output = ddp_model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
world_size = torch.cuda.device_count()
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
mp.spawn:负责创建多个进程,并确保每个进程在独立的 GPU 上运行。torch.distributed:用于在多个进程之间同步模型参数和梯度。
分布式评估(Distributed Evaluation)
分布式训练是深度学习中常用的技术,用于加速模型的训练,但对于评估阶段也同样适用。在分布式训练的设置下,我们常常希望能将多个 GPU 或进程中的评估结果汇总,计算全局的指标,如准确率、损失等。这就需要用到 PyTorch 提供的分布式通信 API,其中
all_reduce和barrier是最常用的两个功能。
问题背景
在分布式训练中,每个 GPU(或者每个进程)会处理不同的数据子集,并独立进行前向传播、梯度计算和反向传播。由于每个 GPU 处理的数据不同,评估时每个 GPU 也会产生各自的损失和准确率等指标。因此我们需要一种机制,将这些不同 GPU 的评估结果聚合起来,得出全局的评估指标。
具体来说,常见的需求有:
- 多 GPU 上的评估结果汇总:每个 GPU 独立地计算评估指标后,如何将这些结果同步并汇总?
- 加速推理过程:希望利用多个 GPU 来并行执行推理任务,从而加速评估过程。
分布式评估核心 API
all_reduce:这是 PyTorch 中用于将不同进程中的张量进行聚合操作的 API。可以指定不同的操作符(如求和、求平均等),它能够在所有进程之间共享数据并执行相应的操作。barrier:同步所有的进程,使得所有进程在某个点上等待,直到所有进程都到达这个点后再继续执行。这通常用于确保所有进程在进行一些同步操作(如模型评估汇总)之前已经完成必要的计算。
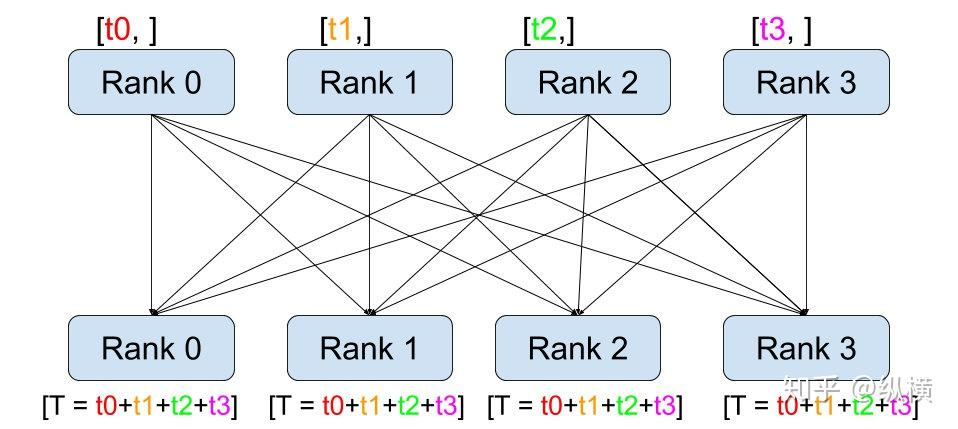
如上图所示,它的工作过程包含以下三步:
- 在调用
all_reduce(tensor, op=...)后,当前进程会向其他进程发送tensor(例如 rank 0 会发送 rank 0 的 tensor 到 rank 1、2、3) - 同时,当前进程接受其他进程发来的
tensor(例如 rank 0 会接收 rank 1 的 tensor、rank 2 的 tensor、rank 3 的 tensor)。 - 在全部接收完成后,当前进程(例如rank 0)会对当前进程的和接收到的
tensor(例如 rank 0 的 tensor、rank 1 的 tensor、rank 2 的 tensor、rank 3 的 tensor)进行op(例如求和)操作。
如何汇总不同 GPU 上的评估结果?
假设你在多 GPU 上进行了分布式训练,接下来想要汇总每个 GPU 上的评估指标。下面的步骤介绍如何通过 all_reduce 实现这一过程。
步骤 1:评估每个 GPU 的结果
每个 GPU(或进程)会独立评估它所处理的子集,并计算出相关指标。例如,假设我们在每个 GPU 上都计算了损失和准确率:
# 每个 GPU 的评估结果(以 loss 为例)
local_loss = torch.tensor([loss_value]).cuda()
步骤 2:使用 all_reduce 汇总所有 GPU 的结果
使用 torch.distributed.all_reduce 来汇总不同 GPU 上的评估结果。all_reduce 是一种所有进程之间的同步操作,能够对多个 GPU 的张量进行指定的操作,如求和、求平均等。
import torch.distributed as dist
# 初始化分布式环境(假设已经完成)
# dist.init_process_group(backend='nccl')
# 汇总各个 GPU 的损失
dist.all_reduce(local_loss, op=dist.ReduceOp.SUM)
# 汇总后得到的 local_loss 是所有 GPU 的损失之和
global_loss = local_loss.item() / dist.get_world_size()
dist.ReduceOp.SUM:表示将所有 GPU 的损失求和。dist.get_world_size():返回进程数(即 GPU 数),用来计算平均损失。
类似的,也可以汇总准确率或其他指标。
步骤 3:同步进程
在汇总评估结果时,通常需要确保所有进程都完成了它们的任务,才能继续进行汇总操作。torch.distributed.barrier() 可以强制所有进程等待,直到所有进程都到达同一状态。
# 等待所有进程都完成了各自的评估计算
dist.barrier()
barrier 主要用于进程间的同步,确保所有进程都准备好后再继续执行后续代码。
分布式推理与测试
分布式推理不仅可以加速推理过程,还能让多个 GPU 并行处理大规模数据集上的推理任务。在训练和推理时,我们可以使用分布式技术将数据切分到不同的 GPU 上并行处理。
步骤 1:构建分布式推理的 DataLoader
与训练类似,推理时也需要使用 DistributedSampler 来均衡地将数据分配到多个 GPU。
from torch.utils.data.distributed import DistributedSampler
# 在推理时创建分布式 DataLoader
test_dataset = ...
test_sampler = DistributedSampler(test_dataset)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, sampler=test_sampler, batch_size=batch_size)
步骤 2:分布式推理流程
每个 GPU 处理自己的数据子集,并计算模型的输出、损失和其他相关评估指标。
model.eval() # 切换模型到评估模式
total_loss = 0.0
# 遍历数据集
for data, target in test_loader:
data, target = data.cuda(), target.cuda()
with torch.no_grad():
output = model(data)
loss = criterion(output, target)
total_loss += loss.item()
# 本地的 total_loss 是该 GPU 上的累计损失
local_loss = torch.tensor([total_loss]).cuda()
步骤 3:汇总推理结果
与前面的步骤类似,通过 all_reduce 将所有 GPU 的推理结果进行汇总。
# 汇总所有 GPU 的损失
dist.all_reduce(local_loss, op=dist.ReduceOp.SUM)
# 计算全局损失
global_loss = local_loss.item() / dist.get_world_size()
这种方式不仅可以加速推理任务,还能确保每个 GPU 都有效地参与计算。
分布式评估中的常见操作符
all_reduce 支持的常见操作符包括:
dist.ReduceOp.SUM:对各个 GPU 的张量求和。dist.ReduceOp.AVG:对张量求平均值(手动除以world_size)。dist.ReduceOp.MIN:找到所有张量中的最小值。dist.ReduceOp.MAX:找到所有张量中的最大值。
可以根据需求选择适合的操作符。例如,评估损失时通常选择求和,然后除以 GPU 数目;而对于准确率,可以直接求平均值。
Apex 与混合精度训练
Apex 是 NVIDIA 开源的工具,专为加速 PyTorch 模型训练而设计,特别是混合精度训练。使用 Apex 可以有效减少显存占用,提升计算速度,尤其是在 GPU 资源有限的情况下。这段整理内容将详细解释 Apex 在混合精度训练及分布式训练中的应用。
1. 混合精度训练的核心概念
混合精度训练结合了 16 位半精度(float16)和 32 位单精度(float32),在不影响模型准确度的前提下减少计算成本。Apex 的 amp.initialize 提供了一个简单的接口来实现这一功能。
Apex 的混合精度训练流程:
amp.initialize:这个函数用于包装模型和优化器。它会根据定义的精度模式自动管理模型的参数。amp.scale_loss:这个函数用于动态缩放 loss,防止由于浮点数的精度过低导致梯度下溢的现象。
from apex import amp
# 模型和优化器初始化
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
这里的 opt_level 允许用户选择不同的混合精度优化策略,常见选项包括:
O0:纯 FP32 训练,未使用混合精度。O1:混合精度训练,主要计算在 FP16,保持参数更新在 FP32。O2:混合精度训练,更多计算在 FP16,需要手动管理模型中某些层的精度。O3:纯 FP16 训练。
2. Apex 与分布式训练
在分布式训练中,Apex 的 DistributedDataParallel (DDP) 模块是 PyTorch 原生 DDP 的改进版本,优化了 NCCL 后端的通信操作。与 PyTorch 相比,Apex 在 API 上更加简洁,自动管理了一些参数传递。
from apex.parallel import DistributedDataParallel
# 使用 apex.parallel.DistributedDataParallel
model = DistributedDataParallel(model)
相比 PyTorch 原生 DDP,Apex 的 DDP 自动处理了部分设备配置,例如 device_ids 和 output_device,减少了配置代码的复杂度。
3. 损失函数缩放与反向传播
在正向传播过程中,Apex 提供 amp.scale_loss 来进行动态的损失缩放。在使用 FP16 训练时,损失值容易变得过小或过大,因此需要对其进行缩放以确保反向传播中的数值稳定性。
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
4. 分布式训练的代码结构
使用 Apex 进行分布式训练时,整体流程与 PyTorch 基本一致。主要区别在于模型和损失计算的包装。
完整代码示例:
import torch
import argparse
import torch.distributed as dist
from apex import amp
from apex.parallel import DistributedDataParallel
# 初始化分布式环境
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
# 初始化 NCCL 通信后端和 CUDA 设备
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
# 准备数据集与数据加载器
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
# 模型与优化器初始化
model = ...
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 使用 apex 进行混合精度初始化
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
# 分布式训练
model = DistributedDataParallel(model, device_ids=[args.local_rank])
# 训练循环
for epoch in range(100):
for batch_idx, (images, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# 前向传播与损失计算
output = model(images)
loss = criterion(output, target)
# 反向传播与梯度更新
optimizer.zero_grad()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()