
混合精度(Mixed Precision)的尝试
Published:
长夜未尽。刚刚有星升起,又落了下去。大地寂静,静得甚至可以听见湖水流动的声音。大门上的灯笼,轻经地在微风中摇曳,灯光也更暗了。
混合精度
这部分东西我之前其实没有接触过, 今天抽出时间来学习一下这一方面, 因为这两天炼丹炼的火热, 我需要学习一下小trick, 用了之后我感觉是训练曲线收敛更快更加光滑了? 但是会不会导致最后的效果不尽人意?
什么是混合精度?
混合精度(Mixed Precision)在深度学习中是一种通过在训练神经网络时同时使用16位(FP16)和32位(FP32)浮点数的技术。该方法通过减少模型计算中的精度需求来提高计算效率,并且可以显著加快训练速度,同时减少内存占用。
PyTorch 1.6 增加了对混合精度训练(包括自动混合精度训练)的 API 支持。使用这些核心曾经需要手动将降低精度的操作写入模型中。如今,torch.cuda.amp API 可用于实现自动混合精度训练,并且只需五行代码即可获得巨大的加速!
TLDR:torch.cuda.amp混合精度训练模块可将大型模型训练作业的速度提高 50-60%。
混合精度的工作原理
在计算机工程中,十进制数(例如1.0151或 )566132.8通常表示为浮点数。由于我们可以拥有无限精确的数字(例如π),但存储它们的空间有限,因此我们必须在精度(在开始舍入之前我们可以在数字中包含的小数位数)和大小(我们使用多少位来存储数字)之间做出妥协。
浮点数的技术标准 IEEE 754设定了以下标准:
- fp64,又称双精度或“双精度”,最大舍入误差为~2^-52
- fp32,又称单精度或“单精度”,最大舍入误差为~2^-23
- fp16,又称半精度或“半”,最大舍入误差为~2^-10
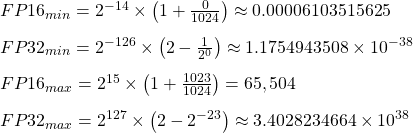
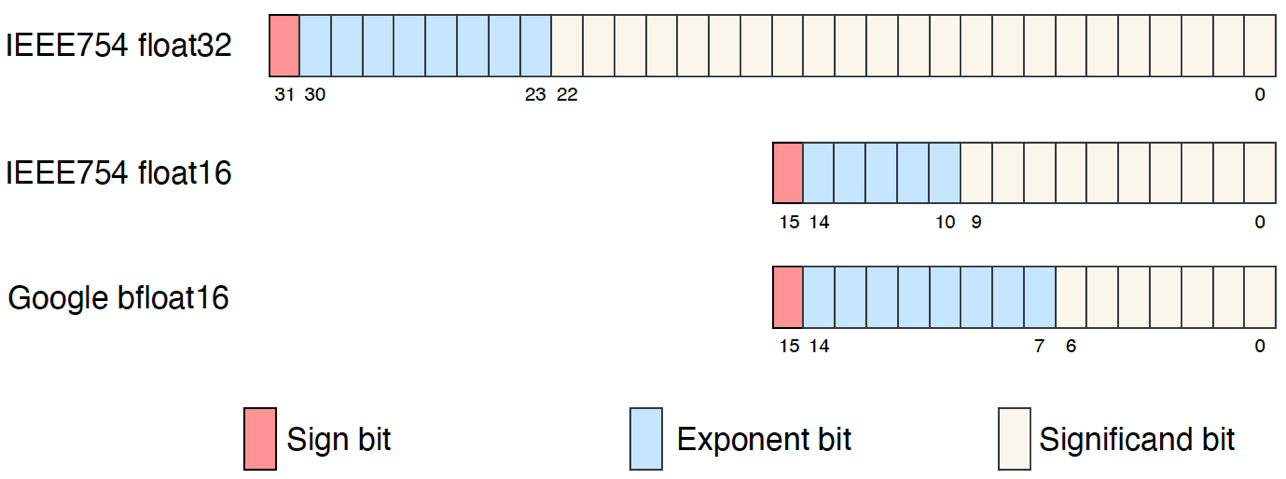
Python 使用fp64浮点类型。PyTorch 对内存更加敏感,因此将fp32其用作默认类型dtype。
混合精度训练背后的基本思想很简单:将精度减半,将训练时间减半 (fp32 → fp16)。它涉及在前向传递之前将权重从 FP32 转换为 FP16。
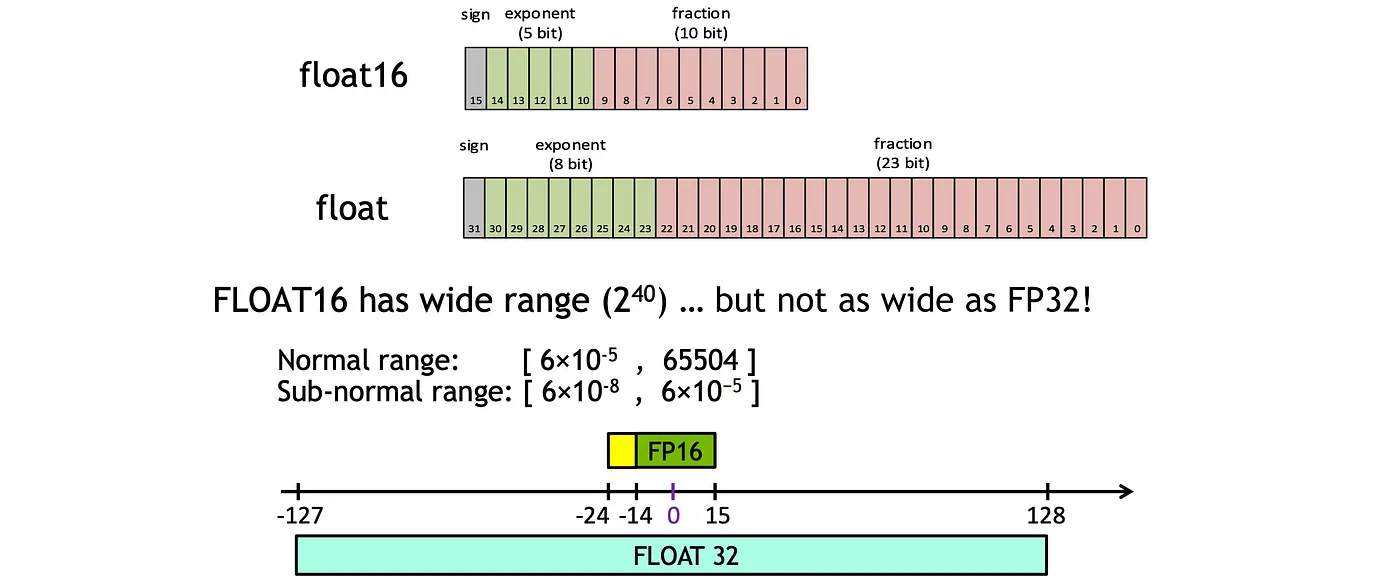
如上所示,FP16 只会覆盖 FP32 的一个子范围。超出的范围的值将被截断。具体来说,当值太小时,它们会在 FP16 中截断为零。
转换之后,前向和后向传递均在 FP16 中完成,具有更快的运行速度和更少的内存带宽。然而,梯度可能会非常小,特别是在与学习率相乘之后。因此,FP32 中的主权重副本可用,并且权重更新在 FP32 中完成。然后在执行前向和后向传递时,它会转换回 FP16。这允许主权重不断增加或缩小,即使转换后的权重值可能相同。
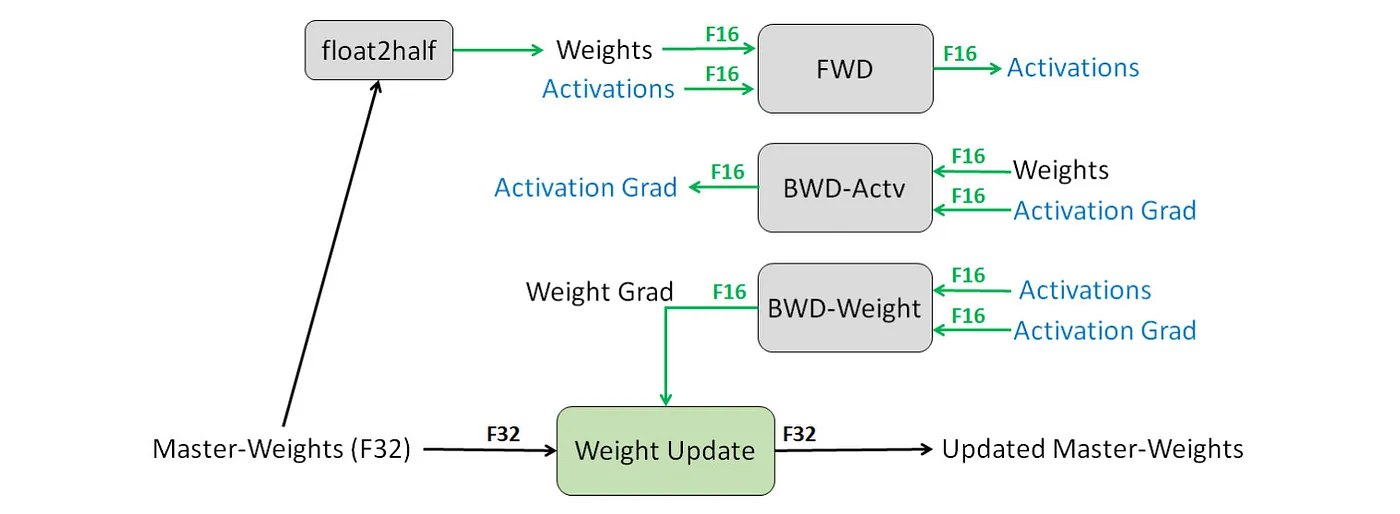
困难的部分是安全地做到这一点。
请注意,浮点数越小,产生的舍入误差就越大。对“足够小”的浮点数执行的任何操作都会将值舍入为零!这被称为下溢,这是一个问题,因为在反向传播过程中创建的许多梯度更新值都非常小,但仍然不为零。反向传播过程中的舍入误差累积会将这些数字变成零或 nan;这会导致不准确的梯度更新并阻止网络收敛。
2018 年 ICLR 论文Mixed Precision Training发现,简单地使用fp16处处小于的梯度更新会“吞噬”2^-24其示例网络所做的所有梯度更新的 5% 左右:
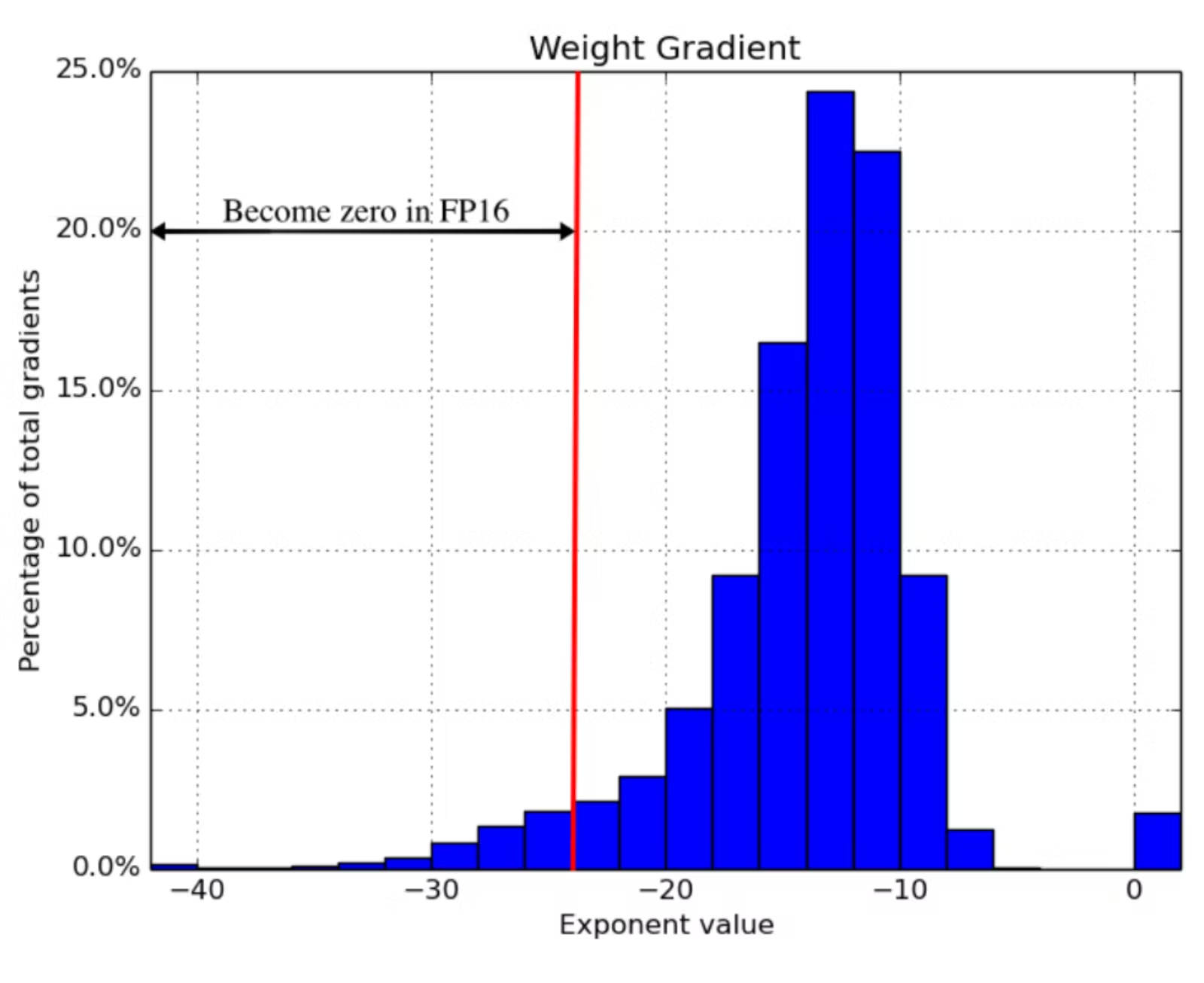
然而,在 FP16 计算中,反向传播中的梯度可能太小并被截断为 0。下图表明,在物体检测中,SSD 模型中 50% 的梯度可以被忽略。
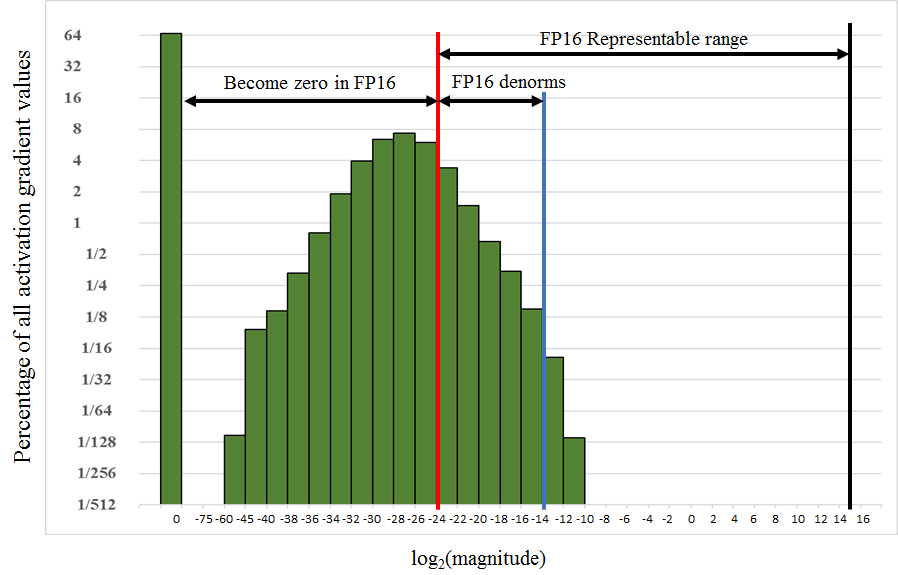
在单精度下训练 Multibox SSD 检测网络时记录的激活梯度直方图。Y 轴是所有值的对数刻度百分比。X 轴是绝对值的对数刻度,以及零的特殊条目。例如,在此训练中,66.8% 的值为零,而 4% 的值介于 $2 ^{-32}$和 $2^{-30}$之间。
混合精度训练是一组技术,可让您使用fp16而不会导致模型训练发散。它是三种不同技术的组合。
一是保留权重矩阵的两个副本,一个“主副本”在 中fp32,另一个半精度副本在 中fp16。梯度更新使用矩阵计算,fp16但应用于fp32矩阵。这使得应用梯度更新更加安全。
第二,不同的向量运算会以不同的速率累积误差,因此要区别对待。有些运算在 中始终是安全的fp16,但其他运算仅在 中可靠fp32。不要在fp16中运行整个神经网络fp16,而是将某些部分分成两半运行,将其他部分分成单个运行。这种混合dtypes就是这种技术被称为“混合精度”的原因。
第三,使用损失缩放。损失缩放意味着在执行反向传播之前将损失函数的输出乘以某个标量。损失值的乘性增加会导致梯度更新值的乘性增加,从而将许多梯度更新值“提升”到安全2^-24阈值以上fp16。只需确保在应用梯度更新之前撤消损失缩放,并且不要选择太大的损失缩放,以免产生无穷大的权重更新(溢出),导致网络向另一个方向发散。
将这三种技术结合起来,作者们能够在显著加快的时间内训练各种网络并使其收敛。

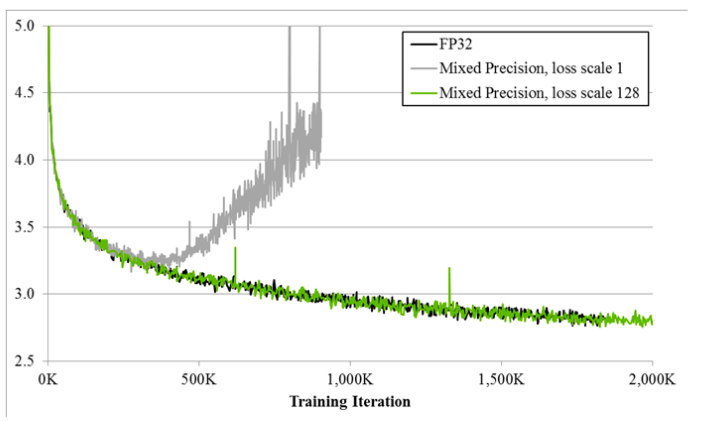
使用混合精度训练的效果可以在上面的绘图中看到。它详细说明了使用三种不同精度格式时大型LSTM英语语言模型的训练曲线:FP32、损失比例为 1 的混合精度和损失比例为 128 的混合精度。Y 轴是训练损失,我们可以用它来查看没有损失缩放的混合精度(灰色)在一段时间后如何发散,而有损失缩放的混合精度(绿色)与单精度模型(黑色)相匹配。这清楚地表明,具有损失缩放的混合精度训练可以实现与单精度 FP32 几乎相同的性能。
张量核如何工作的?
混合精度训练能够显著节省内存(FP16矩阵的大小是FP32矩阵的一半),但如果没有NVIDIA GPU中的张量核心支持,仅依靠混合精度并不能有效加速模型训练。要实现真正的加速,芯片上需要具备能够高效处理半精度计算的硬件,这就是张量核心的用武之地。
张量核心是一种专为矩阵计算设计的特殊处理单元,优化了一个特定的运算:将两个矩阵相乘,并将结果加到第三个矩阵上。这种操作称为融合乘法加法(FMA, Fused Multiply-Add),是许多深度学习计算的核心运算。具体而言,张量核心可以高效地执行4x4 FP16矩阵乘法并将结果存储为FP32。这种高效的矩阵运算作为基本构建块,能够用来加速更大的FP16矩阵乘法运算。
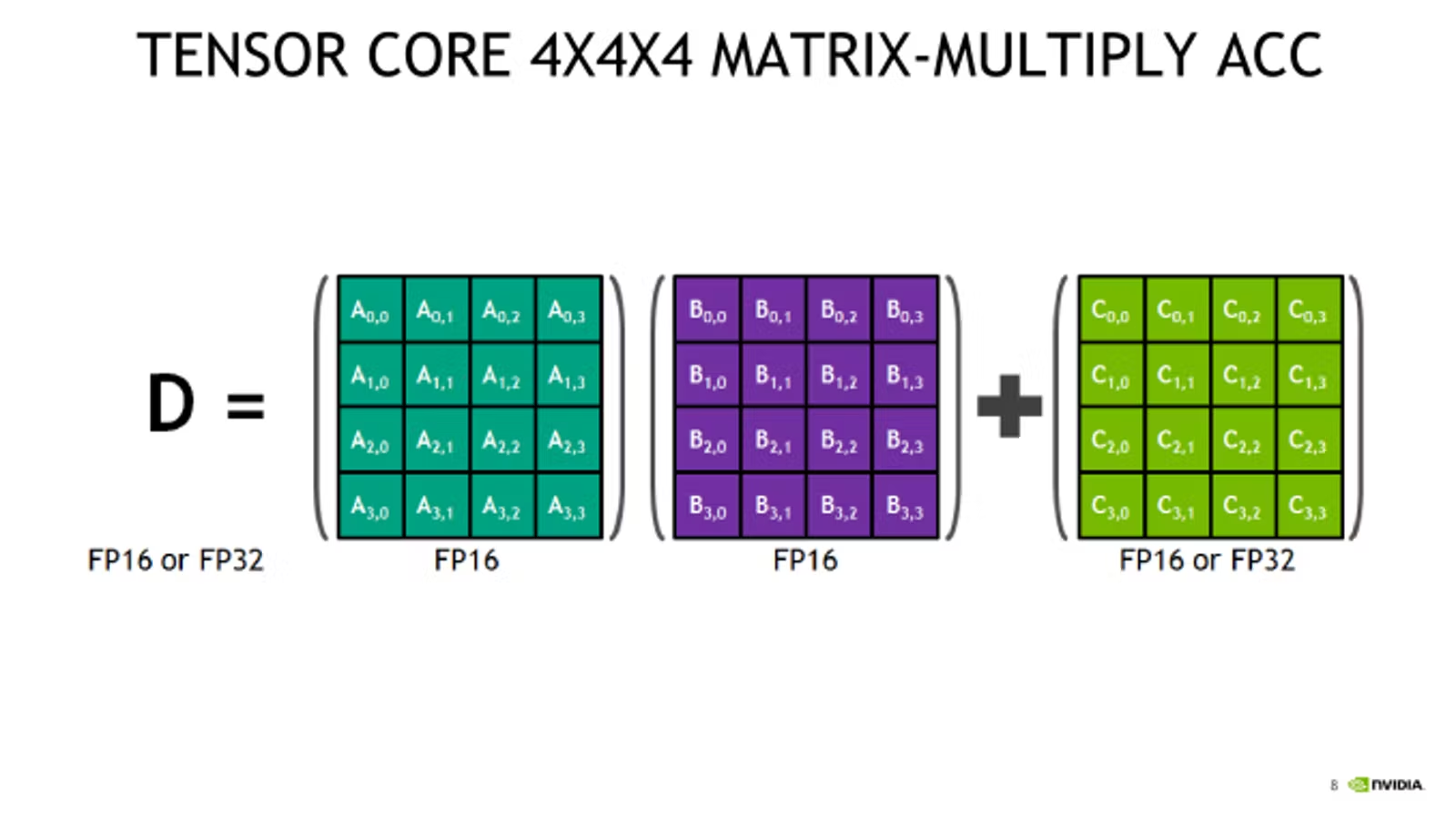
由于神经网络中的反向传播过程基本上依赖于矩阵乘法,因此张量核心非常适合网络中的大多数计算密集型层。这使得它在加速深度学习模型的训练过程中发挥关键作用,尤其是在卷积神经网络(CNN)、Transformer等大规模神经网络中。
然而,要真正利用张量核心的加速能力,输入矩阵必须是FP16格式。如果你在支持张量核心的GPU上进行训练,而没有使用混合精度训练,默认情况下PyTorch模型会以FP32进行计算,这意味着张量核心将保持闲置,GPU无法充分发挥其性能潜力。
Tensor Core最早在2017年底随着Volta架构的发布引入,并在后续的Turing架构中得到了改进。最新的Ampere架构进一步增强了张量核心的性能。常见的支持张量核心的GPU型号有Volta V100(5120个CUDA核心,600个张量核心)和T4(2560个CUDA核心,320个张量核心),这两款GPU在云端租赁中也比较常见,广泛用于深度学习训练任务。
使用张量核心的另一个关键点是固件的版本支持。尽管自CUDA 7.0起张量核心操作就已被支持,但早期版本的实现存在一些BUG,因此建议使用CUDA 10.0或更新版本,以确保能够充分利用张量核心的性能。
Pytorch 自动混合精度的工作原理
混合精度训练技术本质上可以通过手动调整实现:将网络的部分计算转换为FP16格式,并自行实现损失缩放。然而,PyTorch的自动混合精度(AMP, Automatic Mixed Precision)使这一过程变得简单易行,只需学习几个新的API即可:torch.cuda.amp.GradScaler和torch.cuda.amp.autocast。这两个API极大地简化了混合精度训练的实现,能够显著提升性能,同时保持模型的精度。
self.train()
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32)
optimizer = torch.optim.Adam(self.parameters(), lr=self.max_lr)
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer, self.max_lr,
cycle_momentum=False,
epochs=self.n_epochs,
steps_per_epoch=int(np.ceil(len(X) / self.batch_size)),
)
batches = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(X, y),
batch_size=self.batch_size, shuffle=True
)
# NEW: 使用 GradScaler 实现损失缩放
scaler = torch.cuda.amp.GradScaler()
for epoch in range(self.n_epochs):
for i, (X_batch, y_batch) in enumerate(batches):
X_batch = X_batch.cuda()
y_batch = y_batch.cuda()
optimizer.zero_grad()
# NEW: 使用 autocast 自动处理混合精度计算
with torch.cuda.amp.autocast():
y_pred = model(X_batch).squeeze()
loss = self.loss_fn(y_pred, y_batch)
# NEW: 利用 GradScaler 对损失进行缩放
scaler.scale(loss).backward()
lv = loss.detach().cpu().numpy()
if i % 100 == 0:
print(f"Epoch {epoch + 1}/{self.n_epochs}; Batch {i}; Loss {lv}")
# NEW: 使用 GradScaler 进行优化器步骤
scaler.step(optimizer)
scaler.update()
scheduler.step()
GradScaler:动态损失缩放
在混合精度训练中,损失缩放是至关重要的。因为在FP16模式下,梯度的范围会显著缩小,极小的梯度可能被舍入为零,导致模型无法有效训练。GradScaler是PyTorch用于动态调整损失缩放的工具,它可以防止梯度溢出或下溢,同时动态调整损失乘数。
GradScaler从一个较大的初始缩放因子开始,并根据训练过程中是否出现梯度溢出情况来调整缩放因子。例如,当GradScaler检测到梯度更新中存在inf值时,它会丢弃该批次的更新,并将缩放因子减半。相反,如果梯度稳定,缩放因子会逐渐加倍,直到找到合适的值。
这个调整过程类似于指数退避算法,能够动态调整训练过程中合适的损失乘数。GradScaler的默认参数如下:
torch.cuda.amp.GradScaler(
init_scale=65536.0, growth_factor=2.0, backoff_factor=0.5,
growth_interval=2000, enabled=True
)
其中:
• init_scale=65536.0:初始损失乘数(2¹⁶)。 • growth_factor=2.0:每次乘数增加的倍数。 • backoff_factor=0.5:当检测到溢出时,乘数的减少倍数。 • growth_interval=2000:成功批次的数量,触发增长倍数的时间间隔。
GradScalar需要控制梯度更新计算(检查溢出)和优化器(将丢弃的批次变为无操作)来实现其行为。这就是为什么loss.backwards()被 替换scaler.scale(loss).backwards(),optimizer.step()被 替换scaler.step(optimizer)。
值得注意的是,GradScalar它将检测并阻止溢出(因为inf总是不好的),但它无法检测并阻止下溢(因为0通常是合法值)。如果您选择init_scale的 太低,而growth_interval太高,您的网络可能会在GradScalar干预之前下溢并发散。出于这个原因,选择一个非常大的起始值可能是一个好主意,并且使用默认值init_scale=65536(2¹⁶),这似乎是 PyTorch 所遵循的方法。
最后,请注意,这GradScalar是一个有状态的对象。使用此功能对模型进行检查点操作需要将其与模型权重一起写入磁盘并从磁盘读取。使用state_dict和load_state_dict对象方法(PyTorch 文档中介绍)可以轻松完成此操作。
autocast:操作级别的精度控制
自动混合精度训练难题的另一半是torch.cuda.amp.autocast上下文管理器. autocast能够根据操作的类型,在FP16和FP32之间切换精度,从而在保证数值稳定性的同时加速模型训练。例如,矩阵乘法和卷积操作在FP16中是安全的,因此会被autocast转换为FP16执行;而对数、指数等可能引入数值不稳定的操作则会在FP32中执行。
下图展示了autocast如何处理PyTorch中的不同操作:

此列表主要包含两个内容:矩阵乘法和卷积。linear其中还包含简单函数。

这些操作在 中是安全的fp16,但具有向上转换规则,以确保在给定fp16和 的混合fp32输入时它们不会中断。请注意,此列表包括另外两个基本线性代数运算:矩阵/向量点积和向量叉积。

对数、指数、三角函数、正则函数、离散函数和(大)和在 中是不安全的fp16,必须在 中执行fp32。
纵观整个列表,大多数层都会从自动转换中受益,因为它们内部依赖于基本的线性代数运算,但大多数激活函数则不会。卷积层脱颖而出,可能是最大的赢家。
启用自动转换非常简单。您需要做的就是使用autocast上下文管理器包装模型的前向传递:
with torch.cuda.amp.autocast():
y_pred = model(X_batch).squeeze()
loss = self.loss_fn(y_pred, y_batch)
以这种方式包装前向传递会自动启用后向传递(例如loss.backwards())上的自动转换,因此您无需调用autocast两次。
自动混合精度的优势
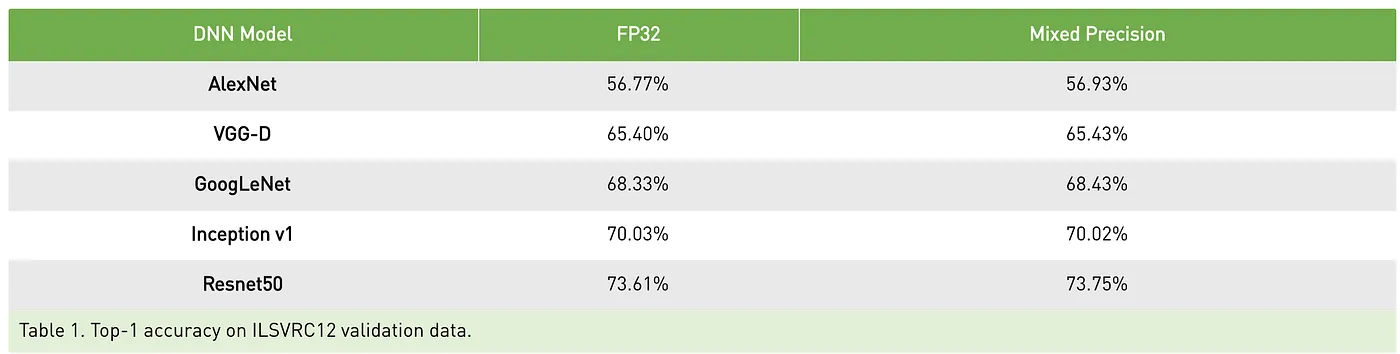
使用PyTorch的AMP不仅可以显著减少内存使用,还可以加快模型的训练速度,同时维持数值精度。结合GradScaler和autocast,混合精度训练几乎无需额外调整即可与标准FP32训练无缝集成,甚至可以与多GPU训练(如DistributedDataParallel或DataParallel)一同使用。我现在的工作是都迁移到混合精度训练上了.
性能
至此,我们已经了解了什么是混合精度、什么是张量核以及实现自动混合精度的 PyTorch API 如何工作。剩下的就是查看一些实际性能基准!
作者通过 Spell API 使用 V100(上一代张量核心)和 T4(当前一代张量核心)训练了三个非常不同的神经网络,一次使用自动混合精度,一次不使用。我分别使用了 AWS EC2 实例、p3.2xlarge最新g4dn.xlarge的 PyTorch 1.6 nightly 和 CUDA 10.0。所有模型都收敛得相当好,例如,所有模型在混合精度和原始网络之间的训练损失方面均无差异。
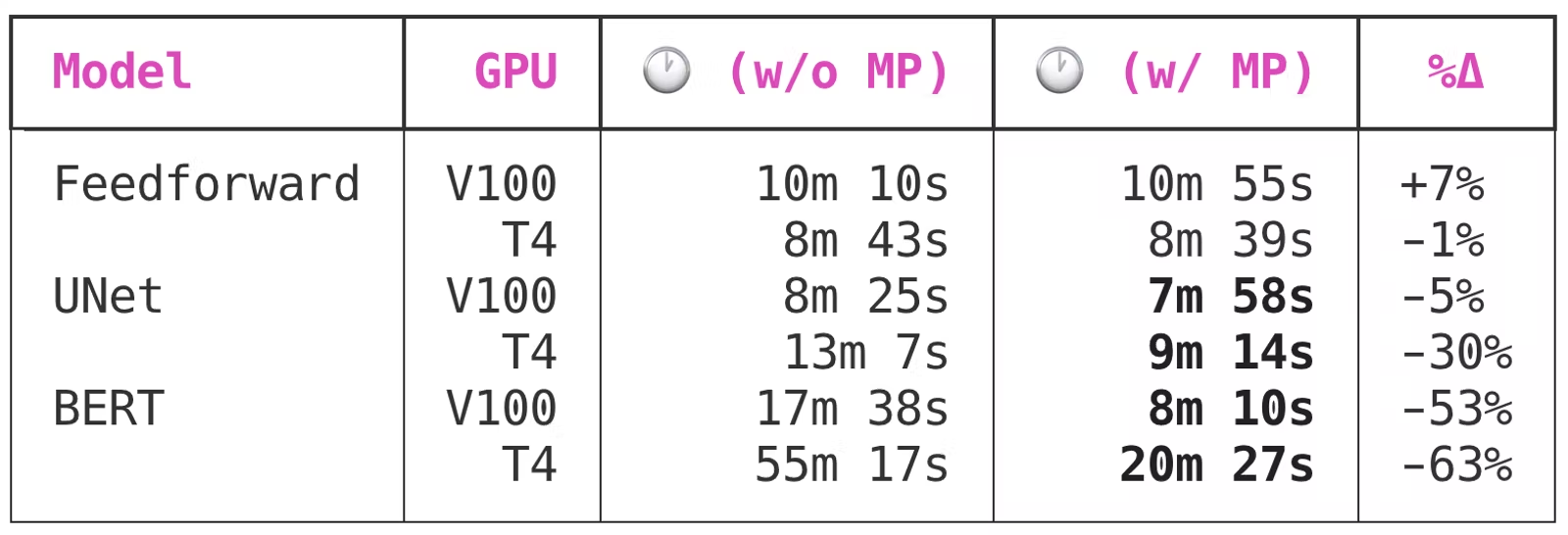
由于前馈网络非常小,因此它无法从混合精度训练中受益。
UNet 是一个中型卷积模型,总共有 7,703,497 个参数,启用混合精度训练后,该模型获得了显著的好处。有趣的是,虽然 V100 和 T4 都受益于混合精度训练,但 T4 的好处要大得多:前者节省了 5% 的时间,而后者节省了高达 30% 的时间。
BERT 是一个大型模型,使用混合精度训练节省的时间从“不错”变成了“必须具备”。自动混合精度将使在 Volta 或 Turing GPU 上训练的大型模型的训练时间缩短 50% 到 60%!
这是一个非常非常大的好处,特别是当你考虑到所需的最小复杂性时——模型训练脚本只需要四到五个 LOC。在我看来:
混合精度应该是您对模型训练脚本进行的首要性能优化之一。
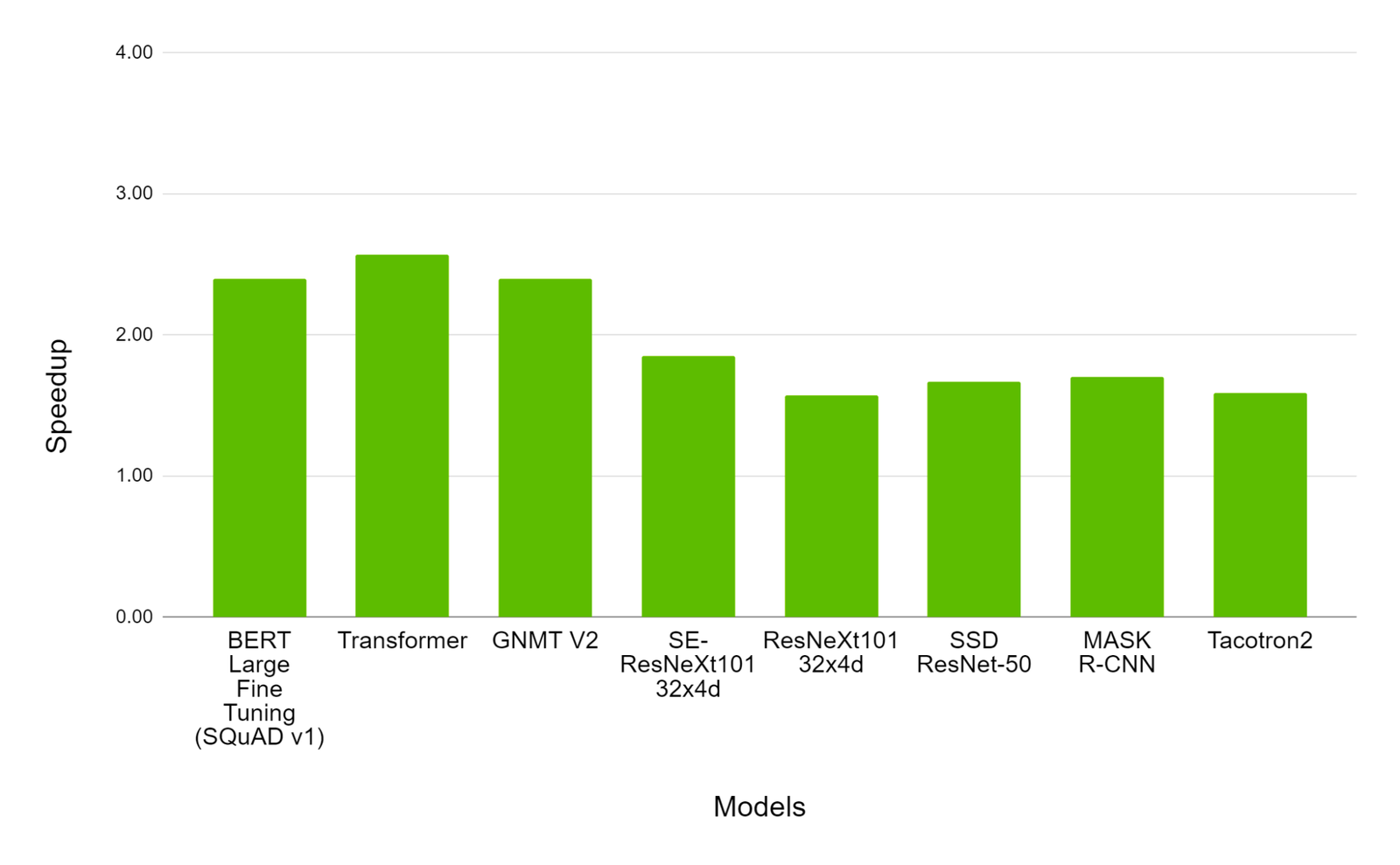
NVIDIA 8xA100 与 8xV100 GPU 上的混合精度训练性能。条形图表示 A100 相对于 V100 的加速系数。越高越好。
我们可以看到,A100 的加速效果比 V100 的加速效果高出约 150% 到约 250%。这再次表明,A100 不仅在深度学习任务方面具有优势,而且微架构的进步和 Tensor Core 技术的相应升级如何影响训练时间。
那么内存怎么样?
fp16矩阵的大小是fp32内存中矩阵的一半,因此混合精度训练的另一个优势是内存使用率。GPU 内存的瓶颈比 GPU 计算要小得多,但优化仍然很有价值。内存使用效率越高,GPU 上可以容纳的批处理大小就越大。
当计算机只有几兆字节的 RAM 时,曾经考虑过通过压缩内存来加倍 RAM 的概念。在 GPU 中,我们实际上并不是将 GPU 内存加倍,而是可以缩小数据大小。具体来说,我们使用 16 位数学运算而不是 32 位浮点运算。这减少了内存占用和内存负载。半精度计算也更快。由于有些操作仍以 32 位形式进行,因此节省的内存将在 1/3 到 1/2 之间。
PyTorch 在模型训练过程开始时预留一定量的 GPU 内存,并在训练作业期间保留该内存。这可以防止其他进程在训练中期预留过多的 GPU 内存,从而导致 PyTorch 训练脚本因 OOM 错误而崩溃。
以下是启用混合精度训练对 PyTorch 内存预留行为的影响:
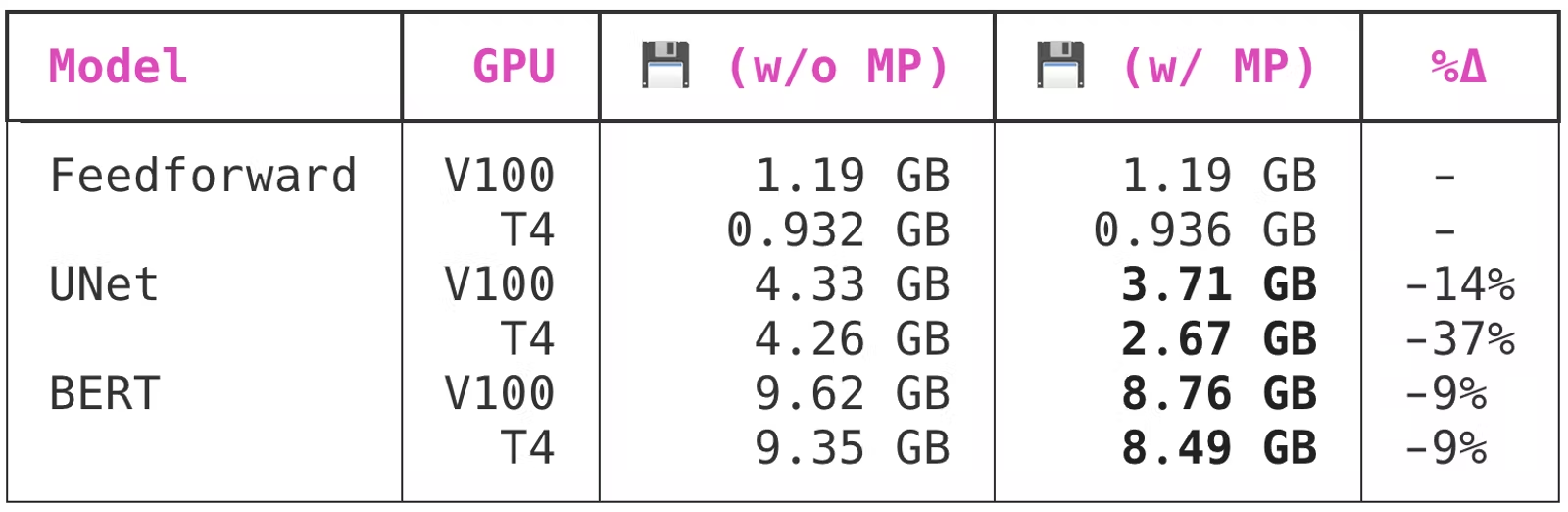
有趣的是,虽然两个较大的模型都从转换为混合精度中受益,但 UNet 从转换中受益比 BERT 多得多。