
学习率和优化器追根溯源
Published:
在四天之内,他给了我一生,给了我整个宇宙,把我分散的部件合成了一个整体。
关于优化器和学习率的选择考虑
到底选择什么优化器? 模型效果不好的话, 那些情况下可能是优化器选择不好?
于是我打算追根溯源一下,看一下这几个算法分别都是基于什么想法什么顺序提出的,为我的论文选一个最美丽的优化方法
- Adam 算法:它结合了动量和RMSProp的思想,通常表现良好,但可能在某些情况下不收敛或错过全局最优解。推荐的超参数是:β1=0.9, β2=0.999, ε=10^-8, 学习率η=10^-3或5×10^-4。然而,Adam 可能不适用于所有情况,特别是当数据非常稀疏时。
- SGD:最基本的优化器,没有复杂的动量或自适应学习率机制。它可能需要更多的调参,但在某些情况下,SGD加上动量(SGDM)可能会比 Adam 表现更好,尤其是在模型需要更细致地探索参数空间时。
- AdaGrad:适用于稀疏数据,但可能不适合处理非常稠密的梯度,因为它会累积所有的历史梯度平方。
- RMSProp:类似于 AdaGrad,但它的分母会衰减,因此不会累积所有历史梯度的信息,这使得它在处理稠密梯度时表现更好。
- AdamW:是 Adam 的变种,它修正了权重衰减的问题,使得权重衰减可以正确地应用于模型参数。这使得 AdamW 在某些任务中比原始的 Adam 表现更好。
- 二阶算法:如 L-BFGS,通常适用于小批量或全批量的深度学习,但在实际应用中较少使用,因为大多数深度学习任务使用的是小批量方法。
关于学习率改进的一些思考
学习率策略应该怎么选? 固定学习率会不会到头来才是刺激它一直学习
- 分段常数衰减(Piecewise constant decay):在训练的不同阶段设置不同的学习率,这种方法简单且易于实现,允许在训练过程中根据需要调整学习率。
- 指数衰减(Exponential decay):学习率按照指数规律递减,即每个epoch后学习率乘以一个小于1的常数因子。
- 阶梯衰减(Step decay):在训练过程中的特定milestones(如每30个epochs)降低学习率。
- 余弦退火(Cosine annealing):学习率按照余弦函数的形式进行调整,模仿训练过程中的“预热”和“退火”过程。
- 自适应学习率调整:如Adam、AdaGrad等优化器,它们根据参数的更新历史自动调整每个参数的学习率。
- OneCycle策略:最近提出的一种策略,它结合了高学习率和低学习率的优点,先快速提高学习率至一定值,然后再降低,形成一个周期。
- 超级收敛(Super-convergence):结合AdamW优化器和1Cycle策略,可以在更短的时间内达到更好的训练效果。
- ReduceLROnPlateau:当模型的性能指标(如验证集上的loss)不再提升时,降低学习率。
随便一搜就有这么多, 到底都有什么区别, 都是用来干嘛的呢?
学习率
学习率控制优化器达到损失函数最小值的步长。
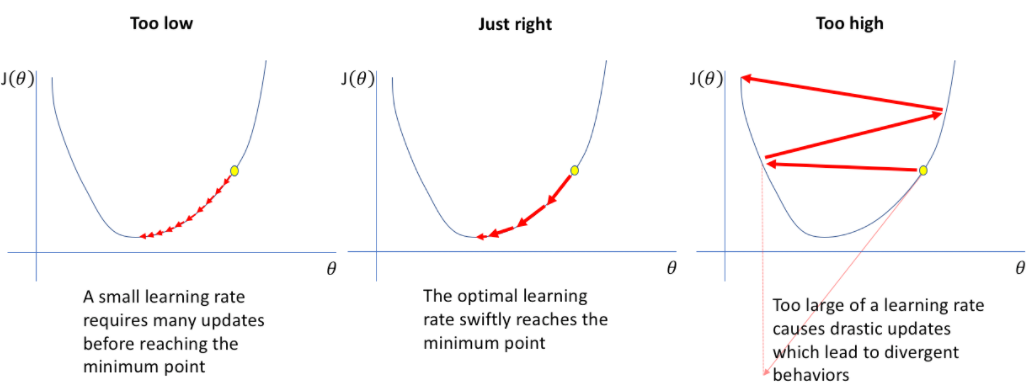
- 学习率较大时(右侧),算法学习速度快,但也可能导致算法在最小值附近震荡甚至跳过最小值。更糟糕的是,高学习率等于大量权重更新,这可能导致权重溢出;
- 相反,如果学习率较小(左侧),权重的更新会很小,这将引导优化器逐渐趋向最小值。但是,优化器可能需要很长时间才能收敛,或者陷入停滞状态或不良的局部最小值;
- 好的学习率是覆盖率和过冲(中间)之间的权衡。它不会太小,以便我们的算法可以快速收敛,也不会太大,以便我们的算法不会在没有达到最小值的情况下来回跳跃。
所有优化器都有一个学习率超参数,它是影响模型性能的最重要的超参数之一。
在最简单的情况下,学习率保持不变。然而,人们很早就发现,选择一个较大的初始学习率,然后随着时间的推移缩小它,可以得到收敛得更好、性能更好的模型。这被称为学习率退火(或衰减)。
在模型训练的早期阶段,模型仍在向梯度空间迈进,较大的学习率有助于它更快地找到所需的粗值。
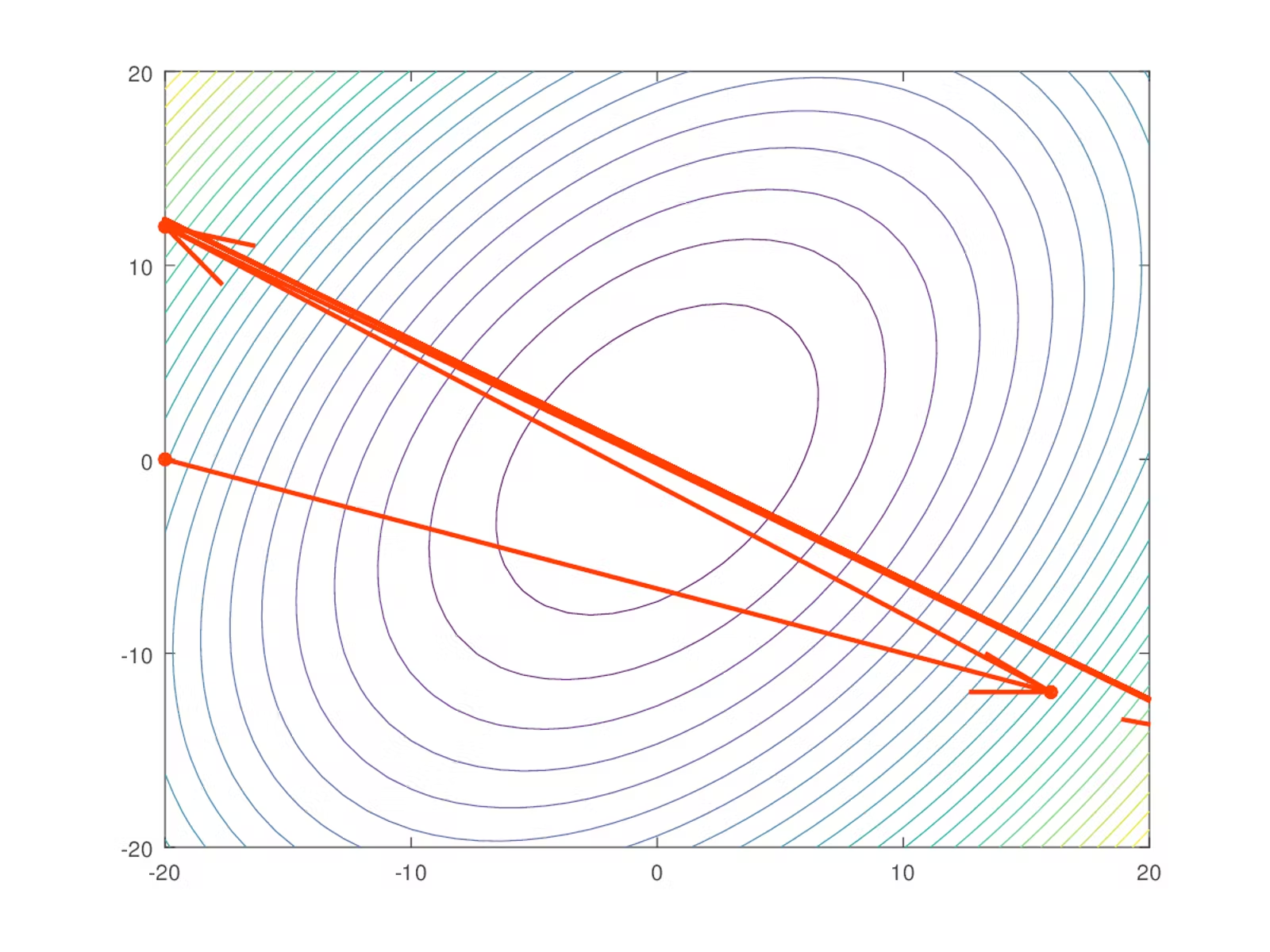
在模型训练的后期,情况正好相反。模型已经具有大致正确的梯度;它只需要一点额外的推动力来找到最后几个百分点的性能。较大的梯度不再合适,因为它会“超越”最优点。模型不会收敛到全局成本最小值,而是会在其周围反弹:
学习率决定了在每步参数更新中,模型参数有多大程度(或多快、多大步长)的调整
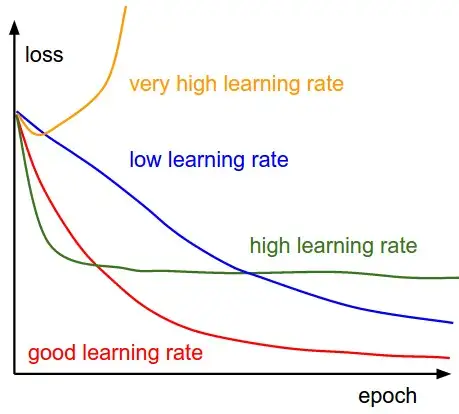
这一观察导致了第一个著名的学习率调度程序ReduceLROnPlateau的流行。ReduceLROnPlateau是一种基于性能下降的学习率调整策略,它在PyTorch中通过torch.optim.lr_scheduler.ReduceLROnPlateau实现。该策略以step_size、patience和cooldown作为输入参数。
在训练过程中,模型会完成每一批训练,并检查模型性能是否有所提高。具体来说,这个检查是基于一些性能指标(如验证集上的损失或准确率)来进行的。如果模型性能在连续patience个批次内没有提升,那么学习率就会降低,通常降低为原来的1/10。这样的调整有助于模型跳出局部最优解,进一步优化模型性能。其实这个方法和我现在思考的事差不多的,学习率的衰减应该是基于模型表现而不能只是简单的基于epoch数。不然可能Loss降低的太快,模型还没来得及学习到有用的东西,就开始进入了慢步走的小learning rate的状态,导致之后训练会变慢很多。
冷却期(cooldown)是指在学习率降低后,需要等待一段时间再进行下一次学习率的调整。这是为了避免学习率调整过于频繁,给模型足够的稳定时间。冷却期过后,此过程会再次重复,直到最后一批训练完成。
EarlyStopping是一种防止过拟合的技术,它通过监控验证集上的性能指标,在模型性能不再提升时提前终止训练。这种技术可以与ReduceLROnPlateau结合使用,以进一步提高模型的泛化能力和性能。
这项技术在几乎所有尝试过的情况下,都能将性能提升一到两个百分点。因此,在深度学习领域,ReduceLROnPlateau与SGD(随机梯度下降)优化器的某种组合,以及EarlyStopping策略,一直是最先进的技术之一,直到2015年左右。
因为2015年提出了Adam:A Method For Stochastic Optimization, 这篇论文提出了自适应优化器
自适应优化器避免使用单独的学习率调度程序,而是将学习率优化直接嵌入到优化器本身中。Adam实际上更进一步,根据每个权重管理学习率。换句话说,它为模型中的每个自由变量赋予自己的学习率。Adam实际分配给此学习率的值是优化器本身的实现细节,而不是您可以直接操纵的东西。
Adam与ReduceLROnPlateau相比,有 两个 引人注目 的 优势.
- 模型性能。这是一个更好的优化器,句号。简而言之,它可以训练更高性能的模型。
- Adam几乎不需要参数。Adam确实有一个学习率超参数,但算法的自适应特性使其非常稳健 - 除非默认学习率偏离一个数量级,否则改变它不会对性能产生太大影响。
Adam并不是第一个自适应优化器(这个荣誉属于Adagrad,于 2011 年发布)但它是第一个足够强大和足够快速以供通用使用的优化器。发布后,Adam立即超越SGD+ReduceLROnPlateau成为大多数应用程序中最先进的优化器。Adamw从那时起,我们看到了改进的变体(如 ),但它们尚未Adam在通用用途上取代最原始的Adam。
如何设置和调整学习率
调整学习率的套路通常是:
- 先设置一个初始学习率。这个初始学习率应该让损失尽可能快地降低。
- 然后训练过程中按照一定的schedule降低学习率;或用算法根据实际训练情况,自适应地调整学习率。
另外,在正式开始训练之前, 还应该有一小段热身的过程。热身的原因是一开始模型参数是完全随机的,需要谨慎地更新参数,不能一上来就用初始学习率。
神经网络的损失景观(如下图所示)是网络参数值的函数,用于量化在对给定数据集执行推理(预测)时使用特定参数值配置所产生的“误差”。即使对于非常相似的网络架构,这种损失景观看起来也可能大不相同。下图来自一篇名为Visualizing the Loss Landscape of Neural Nets论文,该论文展示了网络中的残差连接如何产生更平滑的损失拓扑。
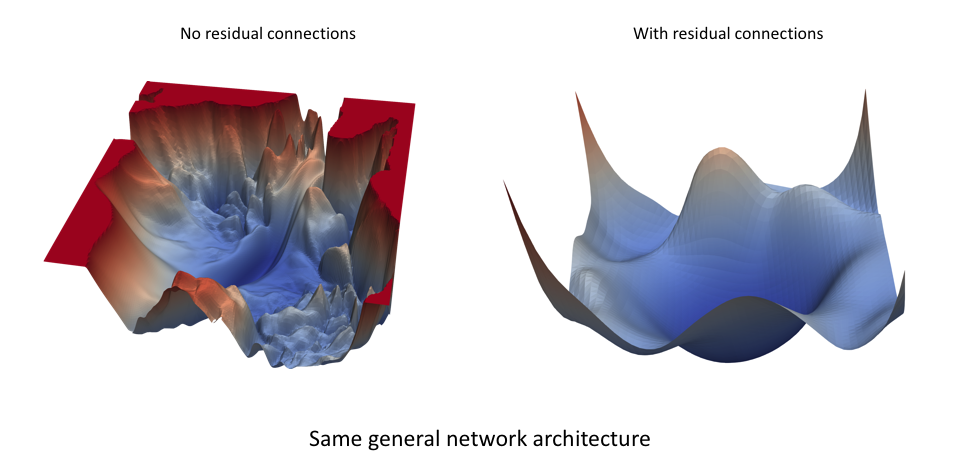
最佳学习率将取决于损失景观的拓扑结构,而损失景观又取决于模型架构和数据集。虽然使用默认学习率(即深度学习库设置的默认值)可能会提供不错的结果,但您通常可以通过搜索最佳学习率来提高性能或加快训练速度。我希望您在下一节中看到这是一项相当容易的任务。
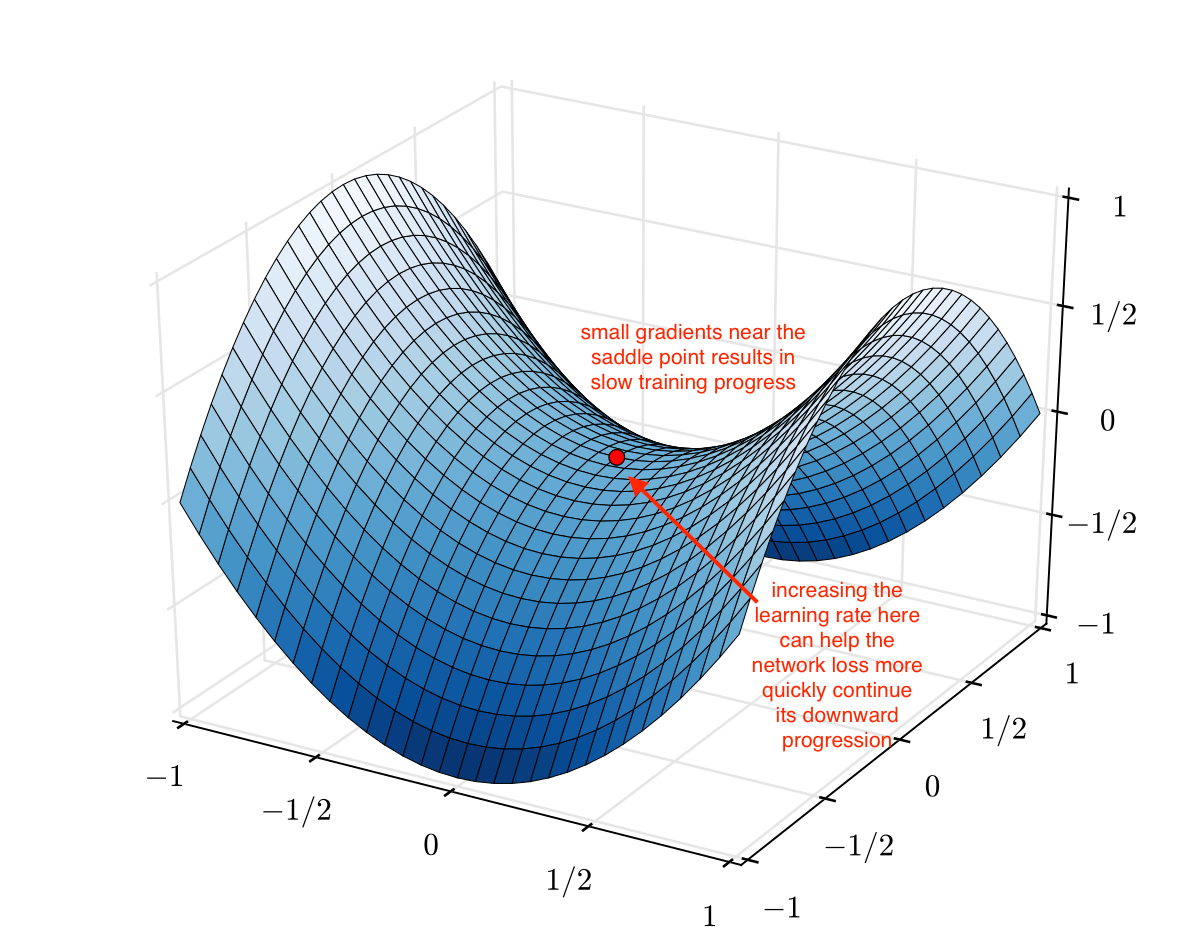
提高学习率还可以实现“更快速地穿越鞍点平台”。如下图所示,鞍点处的梯度可能非常小。由于参数更新是梯度的函数,因此我们的优化步骤非常小;此时提高学习率可能很有用,可以避免在鞍点处停留太久。
基本步骤如下:
- 以学习率为自变量,在定义域内,随着训练步数增加,学习率从小到大增加;
- 画出损失或准确率随学习率变化的曲线。
- 如果是损失变化曲线,选择损失下降最快的学习率作为初始学习率。如果是准确率变化曲线,当精确度增长开始变平或者锯齿状抖动时,就是最大的学习率。
我们希望学习率能够大幅降低网络损失。我们可以通过进行一个简单的实验来观察这一点,在每个小批量之后逐渐增加学习率,记录每次增量的损失。这种逐渐增加可以是线性的,也可以是指数级的。
对于太低的学习率,损失可能会减少,但幅度非常小。进入最佳学习率区域时,您会观察到损失函数快速下降。进一步增加学习率会导致损失增加,因为参数更新会导致损失“反弹”,甚至偏离最小值。请记住,最佳学习率与损失的最大下降相关,因此我们主要对分析图的斜率感兴趣。
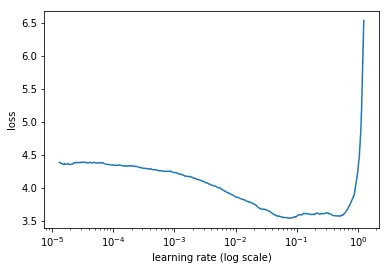
损失随学习率变化的例子如下:
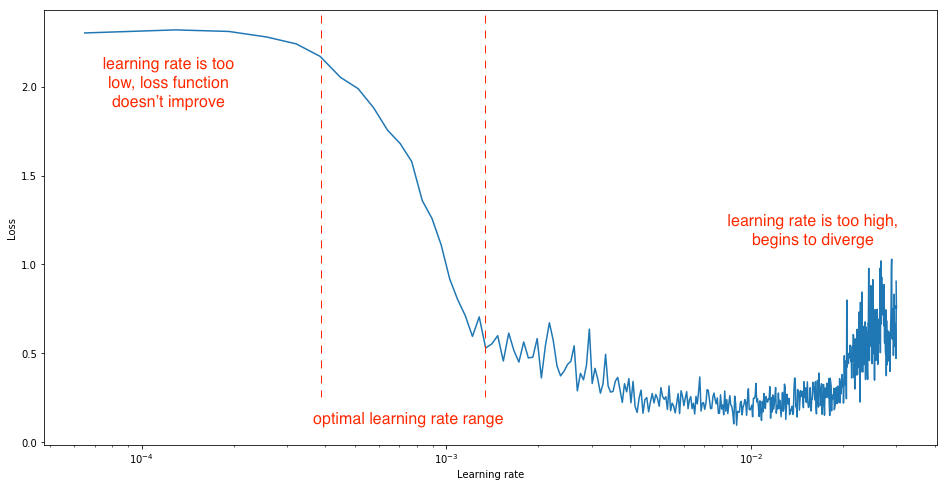
这个例子中,学习率在0.001到0.01时,损失下降最快。
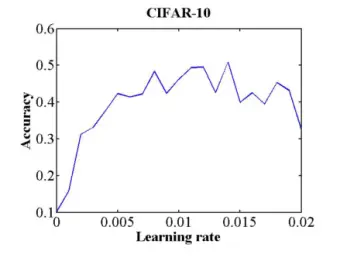
准确率随学习率变化的例子如下:
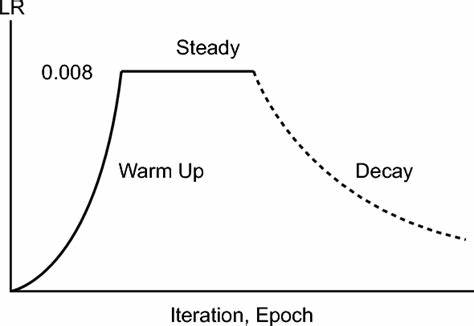
这个例子中,学习率0.006时,准确率开始平稳波动,0.006就应该用作初始学习率。
学习率热身
学习率的热身,即Warm-up,是指在神经网络训练开始时使用一个较小的学习率进行初步训练,然后再逐渐调整到预设的学习率的过程。
学习率热身的目的
- 减少初始振荡
模型在训练初期,由于权重参数的随机初始化,网络通常处于不稳定状态。如果一开始就使用较大的学习率,可能导致权重更新幅度过大,网络的损失函数出现剧烈波动,甚至导致无法收敛。学习率热身通过从较小的学习率逐步增大,使模型权重逐步适应更新,有效避免了这种不稳定现象。
- 加速后期收敛
当模型在初始阶段已经通过小学习率找到了较好的参数区域,后续可以使用较大学习率迅速更新权重,加速收敛。同时,这种方式也能避免训练过程中陷入局部最优解。
- 适应复杂模型的训练
在大型模型或复杂任务的训练中,学习率热身尤其有用。它允许模型通过较低学习率阶段逐步进入稳定状态,尤其适合预训练模型和包含大量参数的深度网络。
学习率热身的实现方法
- 恒定热身(Constant Warmup)
在预热阶段,使用一个固定的小学习率训练模型。当预热阶段结束后,切换至正常的预设学习率。
优点:
• 简单易实现,计算量低。
缺点:
• 学习率在热身结束后存在突变,可能导致后续训练的不稳定。
适用场景:常用于较简单的任务,模型结构不复杂时。
- 线性热身(Linear Warmup)
学习率从 0 线性增加到预设学习率,预热阶段结束后保持不变。该策略可以在训练初期逐步增加学习率,使模型在进入主训练阶段时平滑过渡。
优点:
• 学习率逐渐增加,能有效缓解训练初期的不稳定。
缺点:
• 在热身结束时,学习率的快速增大仍可能导致收敛速度变化。
适用场景:适合绝大多数深度学习任务,特别是中型到大型模型。
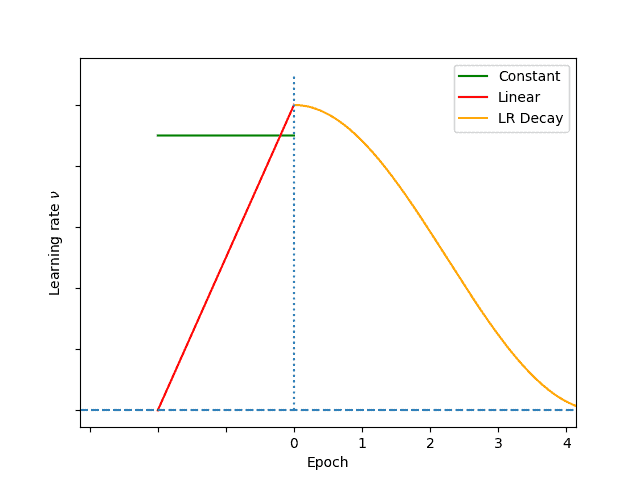
- 余弦热身(Cosine Warmup)
学习率在预热阶段按照余弦函数曲线增加,这种方式使得学习率在预热的后半阶段更加平滑地接近预设值。
优点:
• 过渡平滑,学习率变化较为自然,避免突变带来的影响。
缺点:
• 计算较复杂,尤其在超大规模训练时可能带来额外计算成本。
适用场景:复杂任务和模型,特别是需要更精确控制学习率过渡的场景。
此启发式方法还有其他替代方案,例如使用名为RAdam的优化器。这个相对较新的优化器可以更好地控制梯度方差,这在模型以高 LR 进行训练时是必需的。RAdam 可检测方差不稳定性并平稳地更改 LR,以避免在最早的训练步骤中出现发散。
学习率调度方法
学习率调度方法是优化神经网络训练过程中的关键策略,它通过动态调整学习率来提高模型的收敛速度和性能。主要的三类学习率调度方法包括:基于时间的学习率调度、基于步骤的学习率调度和指数学习率调度。下面将详细介绍这三种方法。
基于时间的学习率调度(Time-Based)
- 定义:学习率按照一定的时间间隔进行衰减。
- 公式:学习率 $lr=\dfrac{initial_learning_rate}{1+decay×epoch}$,其中 decay 是衰减率,epoch 是当前训练周期。
- 优点:能够在训练初期使用较大的学习率加速收敛,随后逐渐减小学习率以精细调整模型参数。
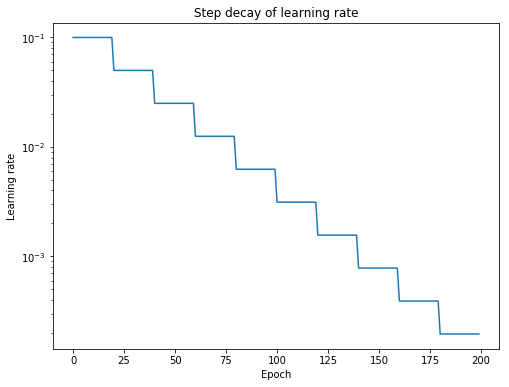
基于步骤的学习率调度(Step-Based)
- 定义:学习率在每经过一定数量的步骤或迭代后按照固定比率衰减。
- 公式:学习率 $lr=lr×decay_rate$,其中 decay_rate 是衰减比率,每经过一步更新一次学习率。
- 优点:实现简单,灵活性高,可以根据需要设置不同的衰减步长和比率。
指数学习率调度(Exponential)
- 定义:学习率按照指数函数进行衰减。
- 公式:学习率 $lr=initial_learning_rate×decay_rate^{step}$,其中 decay_rate 是衰减比率,step 是当前迭代步数。
- 优点:能够在训练初期快速减小学习率,适用于需要快速收敛的场景。
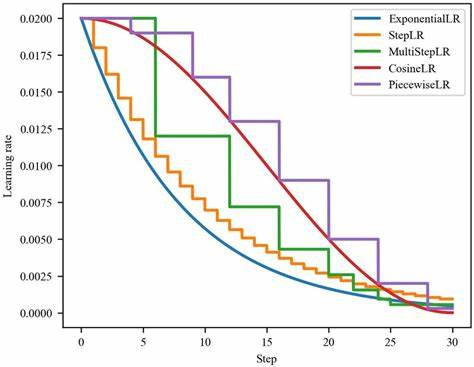
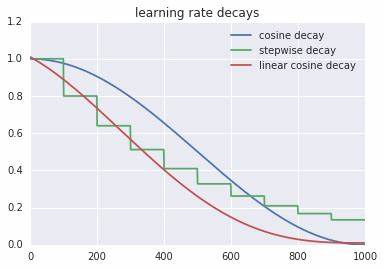
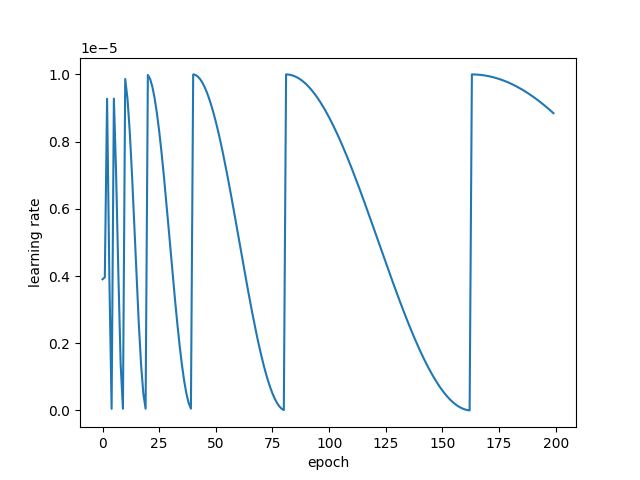
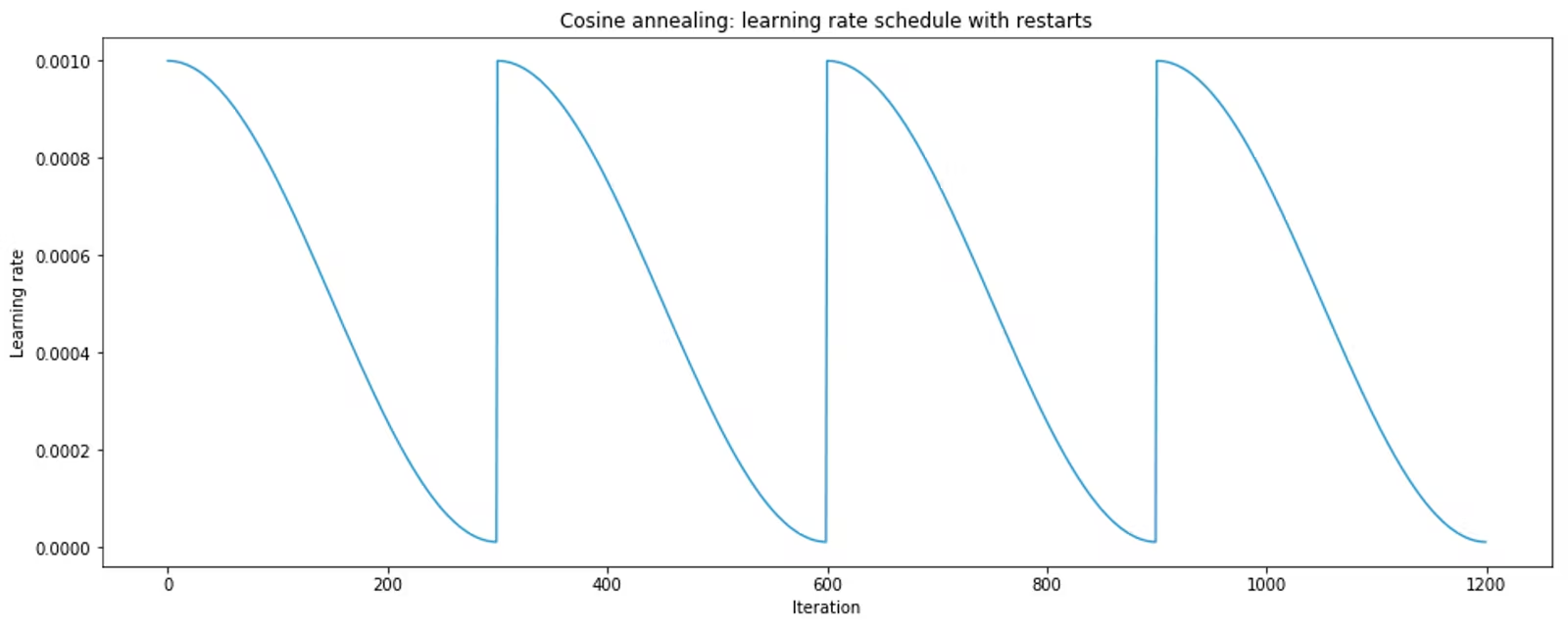
热重启学习率调度
领域的下一个重大进步可以说是 2017 年的论文SGDR: Stochastic Gradient Descent with Warm Restarts,该论文推广了热重启的概念。包含热重启的学习率调度程序偶尔会重新提高学习率。一个简单的线性示例展示了如何做到这一点:
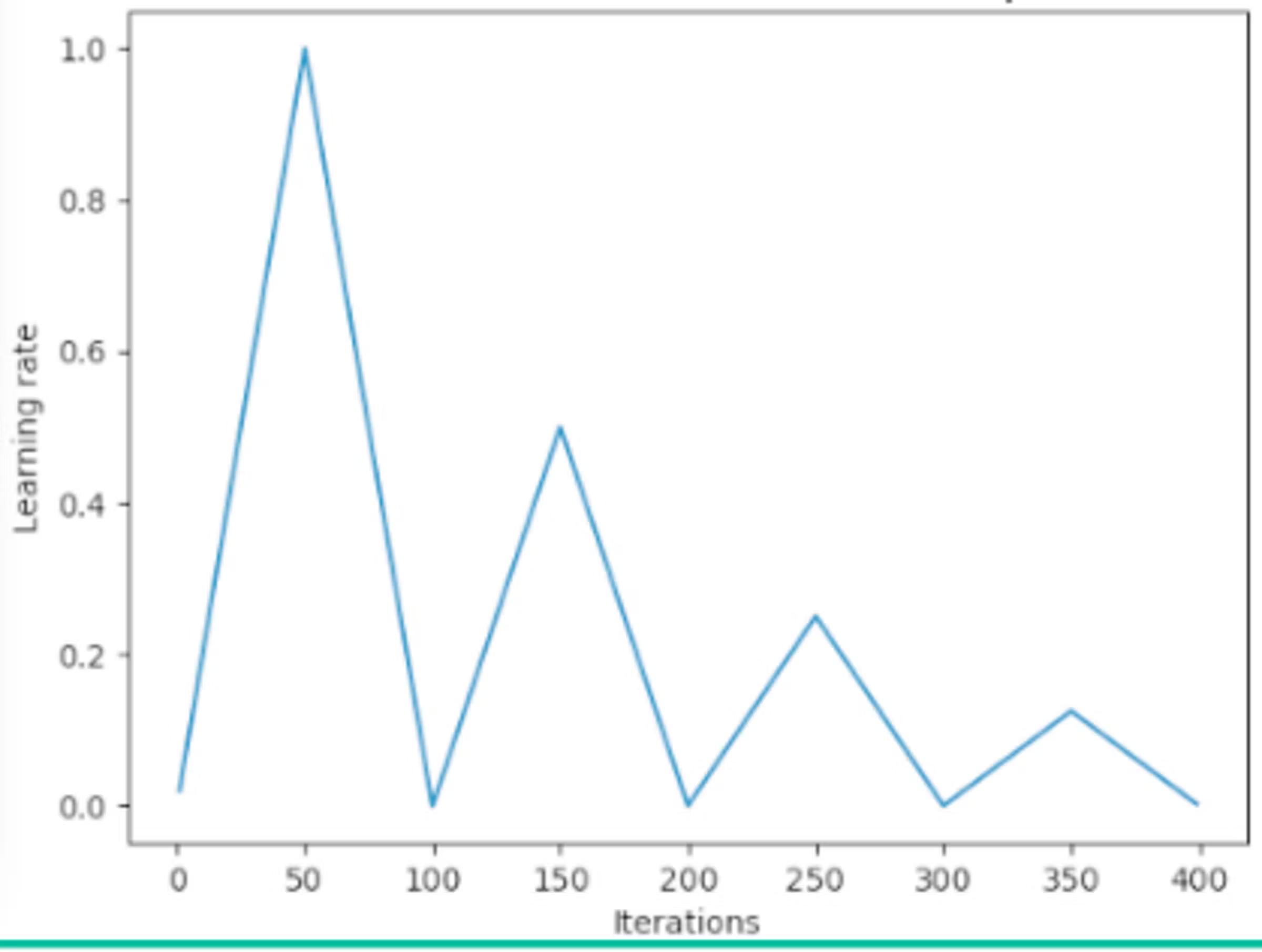
热重启通常会导致模型发散。这是故意为之。事实证明,增加一些受控发散可以让模型绕过任务成本面中的局部最小值,从而找到更好的全局最小值。这类似于找到一个山谷,然后爬上附近的一座山,然后在一个地区发现一个更深的山谷。以下是视觉摘要:
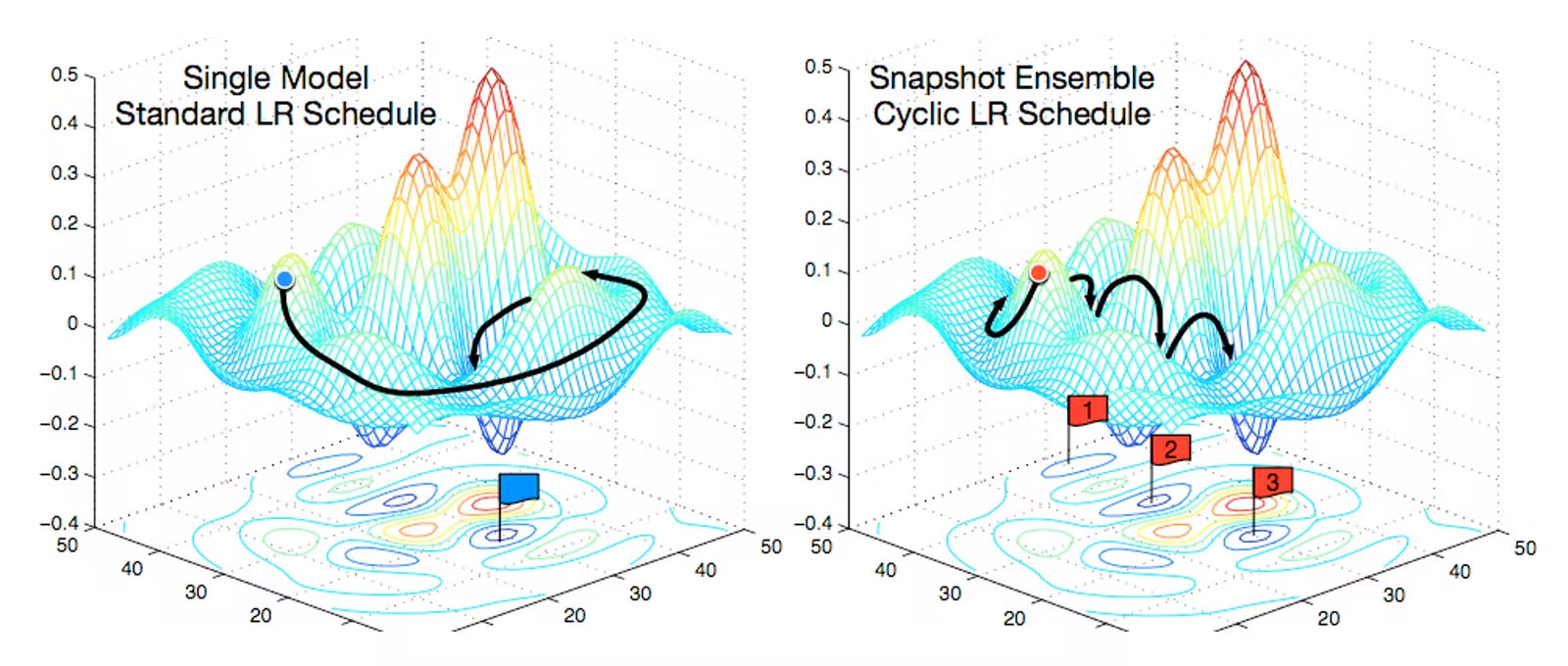
这两个学习器都收敛到相同的全局最小值。然而,在左侧,学习器沿着低梯度路径缓慢前进。在右侧,学习器陷入一系列局部最小值(谷底),然后使用热重启来越过它们(山丘)。在此过程中,它更快地找到相同的全局最小值,因为它所遵循的路径总体上具有更高的梯度。
带热重启的随机梯度下降(SGDR)
使用热重启和余弦退火的学习率调度程序具有以下形状:
单周期学习率调度器
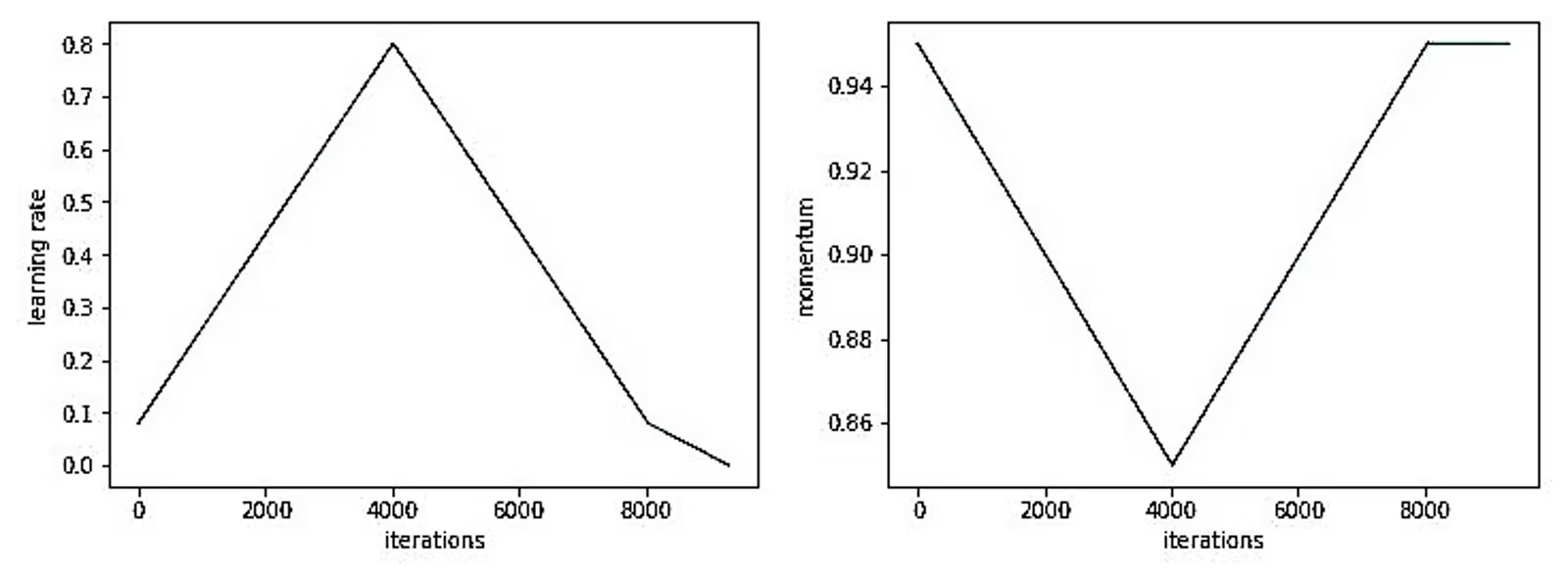
单周期学习率调度器(OneCycleLR)是一种有效的训练策略,最早由 Leslie Smith 在 2017 年的论文《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》中提出。它通过控制学习率和动量的周期性变化,加速网络收敛,甚至能够在短时间内达到比传统方法更好的性能。
OneCycleLR 的工作原理
OneCycleLR 调度器依赖于学习率和动量的动态调节,它的基本策略包括以下几个阶段:
热身阶段:从较低的学习率逐步上升,帮助模型稳定开始训练。
学习率峰值阶段:在达到峰值时,学习率变得足够大,驱使模型迅速靠近损失函数的低谷。
冷却阶段:一旦学习率达到峰值后,逐渐降低以细化模型,使其稳定于一个良好的局部最优解。
微调阶段:学习率降至初始值的十分之一,以稳定最终的训练结果。
如下图所示,学习率呈现一个非对称的山峰形态,在峰值处达到模型性能的最大潜力,而动量的变化与学习率正好相反,确保训练在高速阶段依然稳定。
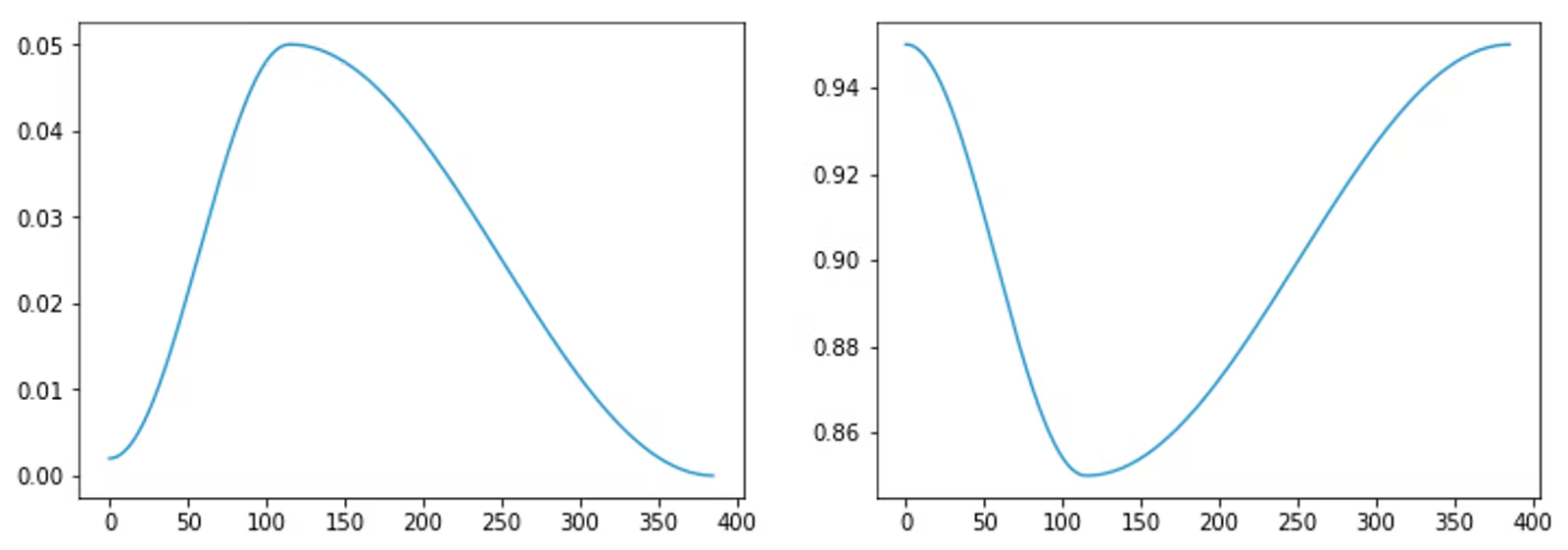
从线性退火到余弦退火
最佳情况下,学习率和动量应设置为刚好导致网络在峰值处开始发散的值。训练方案的其余部分包括热身、冷却和微调阶段。请注意,在微调期间,学习率会降至其初始值的 1/10。
单周期学习率调度程序使用的机制与余弦退火热重启学习率调度程序使用的机制大致相同,只是形式因素不同。
余弦退火变化如下图所示,它从热启动阶段逐渐进入平稳期,最大限度减少模型训练的振荡。
Adam vs. OneCycleLR:谁是赢家?
Adam 优化器是当前最流行的优化器之一,尤其在快速迭代中备受推崇。它不需要调节太多参数,并且能够鲁棒地适应各种模型。因此,在许多竞赛或快速开发项目中,Adam 仍然是主流选择。它可以在很短的时间内训练出性能大致相同或略差的模型。这是由于 Leslie Smith(一次周期的论文作者)称之为超收敛的现象。但随着模型复杂度增加,在后期优化阶段,尝试从 Adam 过渡到 OneCycleLR 能带来显著收益。
OneCycleLR 特别适合中、大规模模型的优化,它通过快速收敛机制在短时间内提升模型性能。例如,OneCycleLR 在 CIFAR-10 数据集上展示了超收敛现象——能够在短时间内接近甚至超越标准方法的性能。
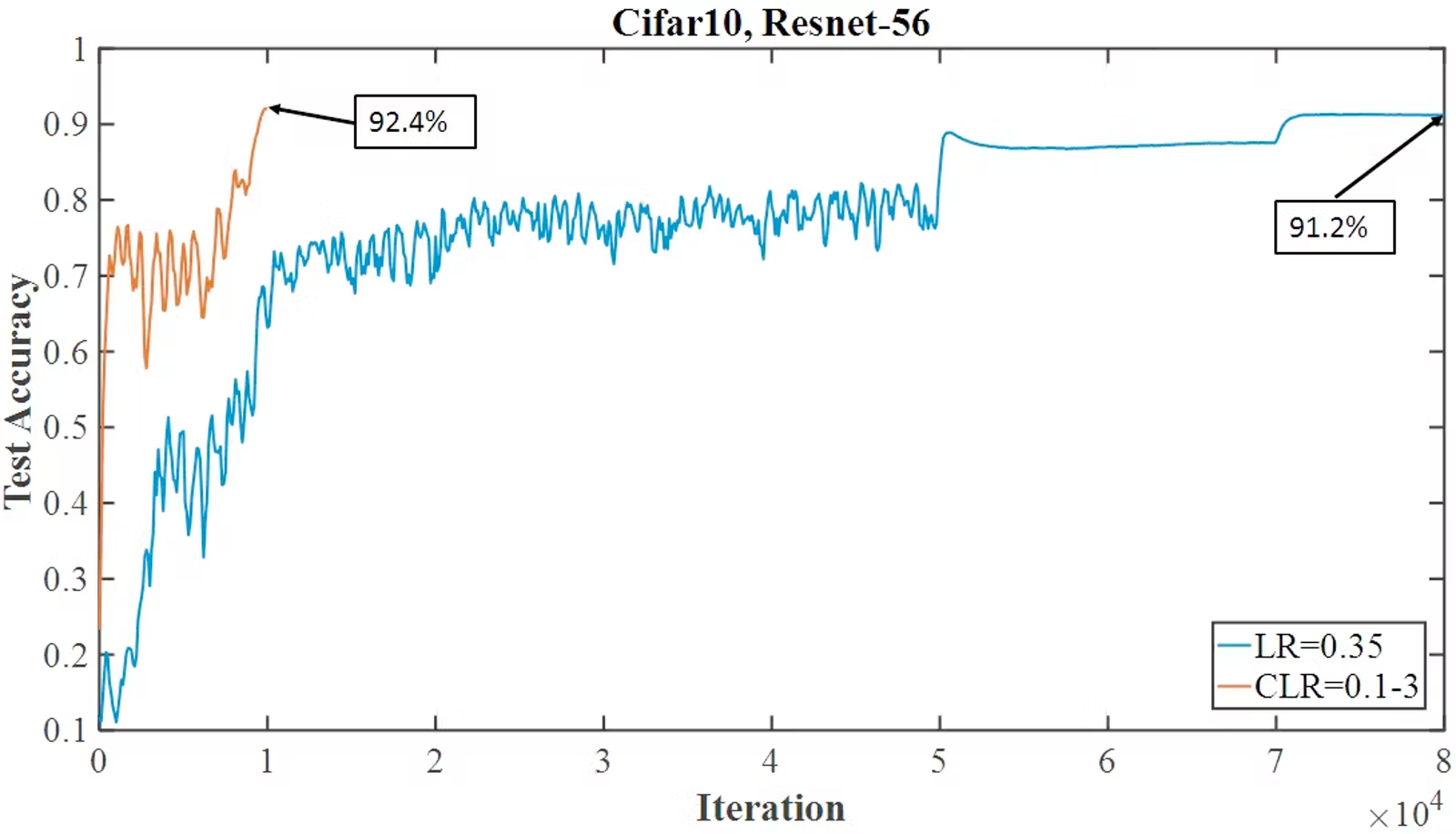
正如上图所示,OneCycleLR 调度器能够在相对较少的训练时间内达到非常优异的结果,节省训练资源的同时,也加快了模型的迭代速度。
何时选择 OneCycleLR?
虽然 Adam 优化器在很多情况下都表现出色,但 OneCycleLR 提供了一个不同的思路。特别是在希望通过少量调参实现更快收敛时,OneCycleLR 是一个有力的选择。正如 Leslie Smith 所指出的,OneCycleLR 提供了一种“超收敛”现象——在更短的时间内实现模型的收敛。
在中大型模型训练项目的优化阶段,将 Adam 替换为 OneCycleLR 可以显著加快训练速度并提高最终性能。想象一下,如果模型在训练时间减少 75% 的情况下,依然可以达到接近 98% 的性能,这无疑为训练效率带来了巨大的提升。
总结
OneCycleLR 是一种强大且高效的学习率调度策略,尤其在复杂模型的后期优化阶段,能够大幅缩短训练时间并提升模型性能。无论你是在小规模任务中快速试验,还是在大规模任务中进行精细调优,OneCycleLR 都能提供一条快速、高效的训练路径。